Azure Machine Learning の基礎モデルの微調整について
Azure Machine Learning のモデル カタログにある基礎モデルを微調整するために、スタジオ、Python SDK、または Azure CLI で提供されるユーザー インターフェイスを使用できます。
データとコンピューティングを準備する
モデルのパフォーマンス向上のために基礎モデルを微調整する前に、トレーニング データを準備し、GPU コンピューティング クラスターを作成する必要があります。
ヒント
Azure Machine Learning で GPU コンピューティング クラスターを作成すると、GPU 最適化仮想マシンが自動的に作成されます。 Azure で使用できる GPU 仮想マシンのサイズの詳細をご確認ください。
トレーニング データは、JSON Lines (JSONL)、CSV、または TSV 形式にすることができます。 データの要件は、どのタスクのモデルを微調整するかによって異なります。
| タスク | データセットの要件 |
|---|---|
| テキスト分類 | 2 つの列: Sentence (文字列) と Label (整数または文字列) |
| トークンの分類 | 2 つの列: Token (文字列) と Tag (文字列) |
| 質問応答 | 5 つの列: Question (文字列)、Context (文字列)、Answers (文字列)、Answers_start (整数)、Answers_text (文字列) |
| 概要 | 2 つの列: Document (文字列) と Summary (文字列) |
| 翻訳 | 2 つの列: Source_language (文字列) と Target_language (文字列) |
Note
データセットに、必要とされる要件を設定してください。 異なる列名を使用できますが、列を適切な要件にマップしてください。
データセットとコンピューティング クラスターの準備ができたら、Azure Machine Learning で微調整ジョブを構成できます。
基礎モデルを選択する
Azure Machine Learning スタジオでモデル カタログに移動すると、すべての基礎モデルを探索できます。
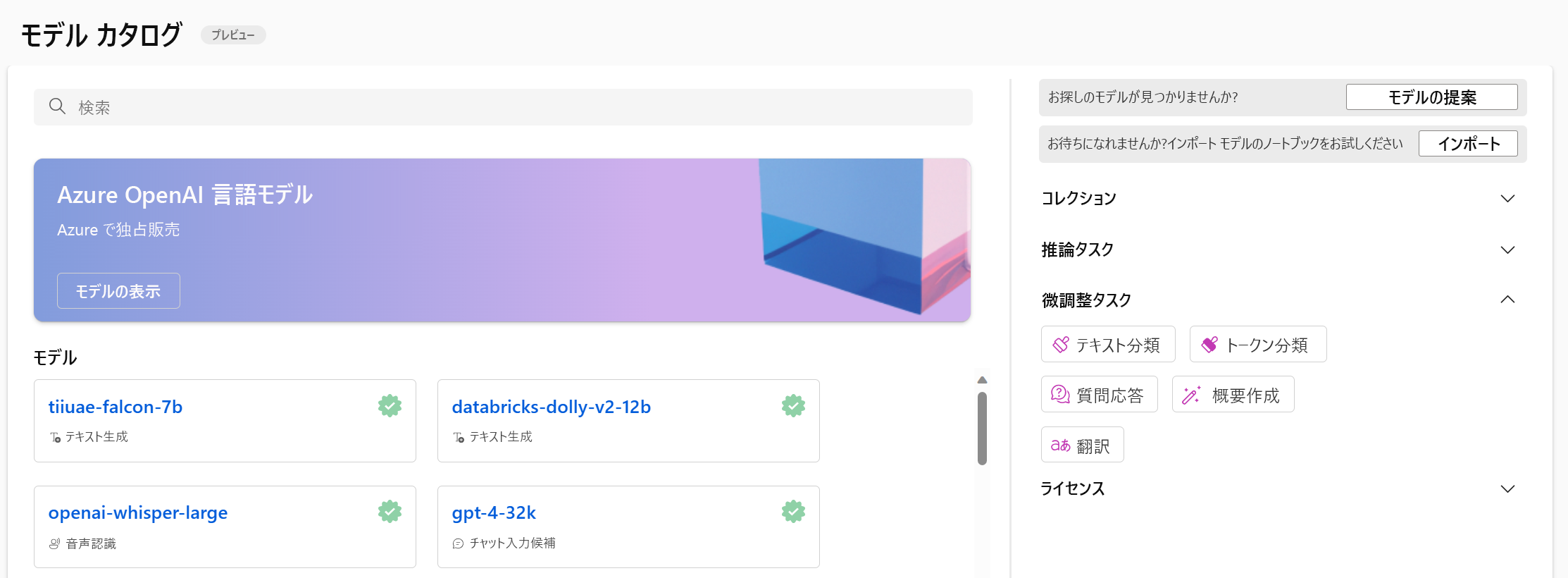
モデルを微調整するタスクに基づいて、使用可能なモデルをフィルター処理できます。 タスクごとに、基礎モデルを選択するためのいくつかのオプションがあります。 タスクの基礎モデルを決定するときに、モデルの説明と参照されるモデル カードを調べることができます。
微調整する前の、基礎モデルを決定する際に考える必要がある考慮事項を次に示します。
- モデルの機能: 基礎モデルの機能と、それらがタスクにどの程度合っているかを評価します。 たとえば、BERT のようなモデルは、短いテキストを理解することに優れています。
- 事前トレーニング データ: 基礎モデルの事前トレーニングに使用されるデータセットを検討してください。 たとえば、GPT-2 は、インターネットのフィルター処理されていないコンテンツでトレーニングされるため、偏りが発生する可能性があります。
- 制限と偏り: 制限や偏りが基礎モデルに存在する可能性があるので注意してください。
- 言語サポート: ユース ケースに必要な特定の言語サポートまたは多言語機能を提供するモデルを確認してください。
ヒント
Azure Machine Learning スタジオではモデル カタログ内の各基礎モデルの説明が提供されますが、それぞれのモデル カードを使用して各モデルの詳細を確認することもできます。 モデル カードは各モデルの概要で参照され、Hugging Face の Web サイトでホストされます
微調整ジョブを構成する
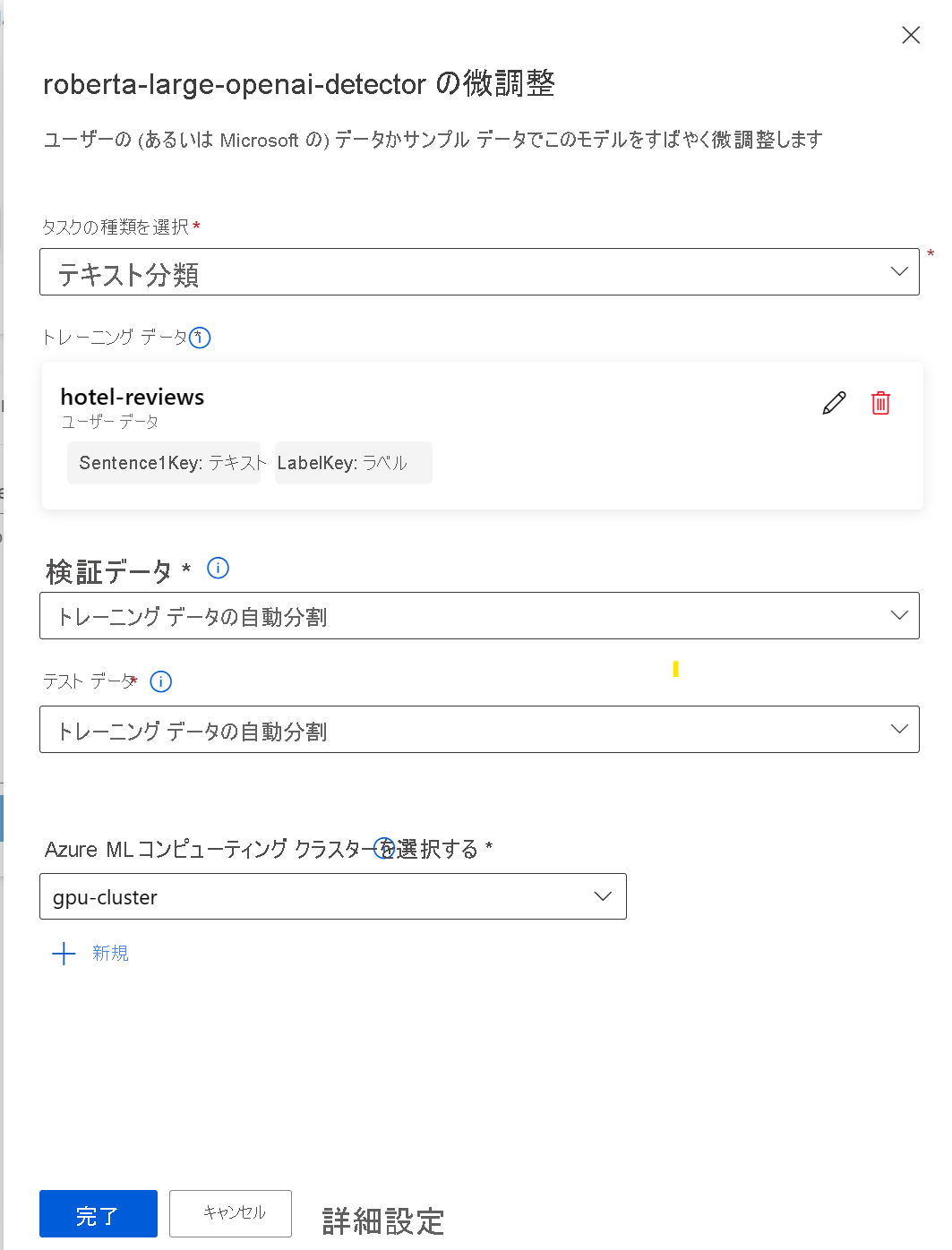
Azure Machine Learning スタジオを使用して微調整ジョブを構成するには、次のステップを実行する必要があります。
- 基礎モデルを選択します。
- [微調整] を選択して、ジョブの構成に役立つポップアップを開きます。
- タスク タイプを選択します。
- トレーニング データを選択し、トレーニング データの列をデータセットの要件にマップします。
- Azure Machine Learning でトレーニング データを自動的に分割して検証とテストのデータセットを作成するか、独自に提供します。
- Azure Machine Learning によって管理される GPU コンピューティング クラスターを選択します。
- [完了] を選択して、微調整ジョブを送信します。
ヒント
必要に応じて、詳細設定を調べて、微調整ジョブの名前やタスク パラメーター (学習率など) などの設定を変更できます。
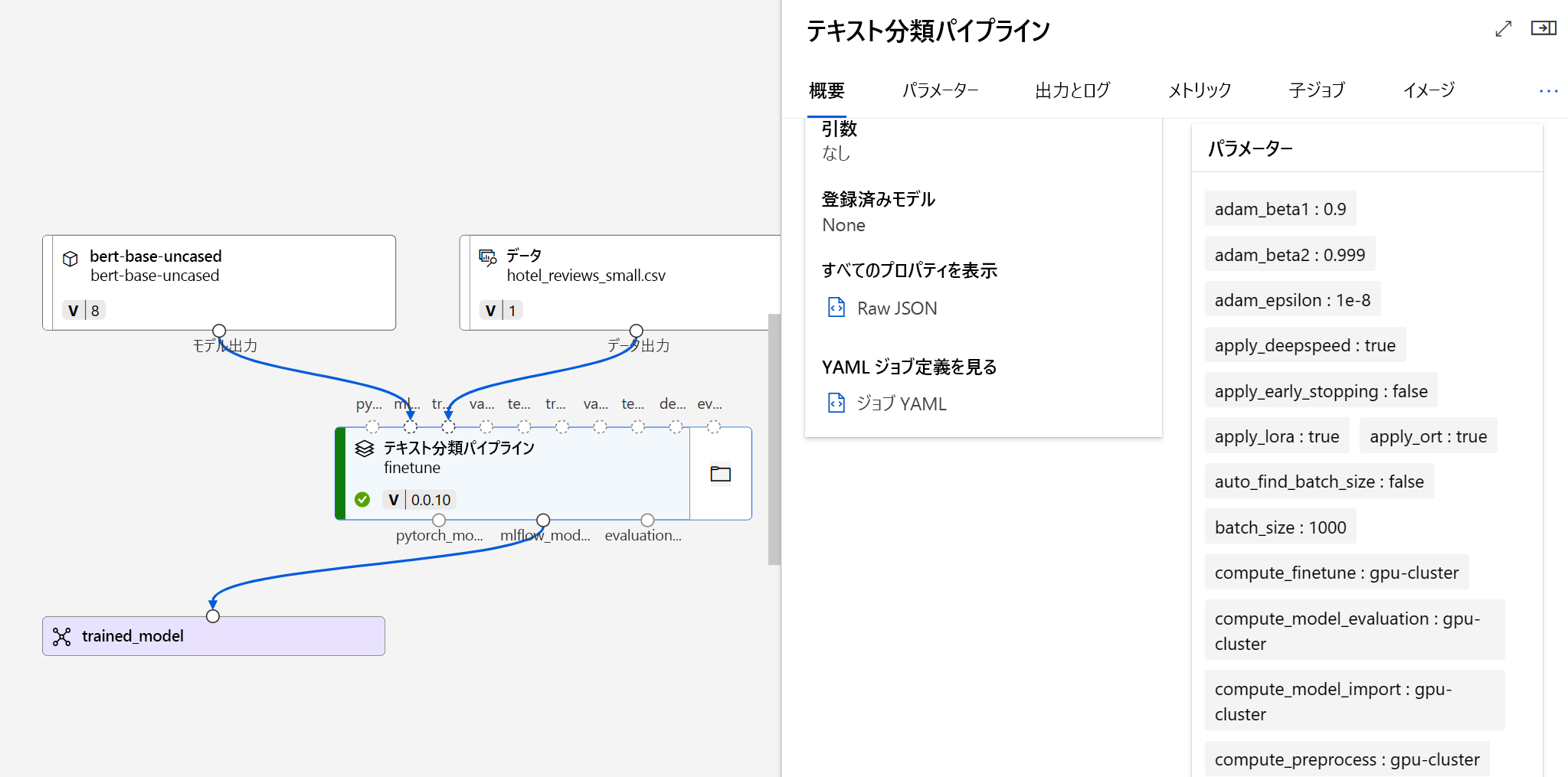
微調整ジョブを送信すると、モデルをトレーニングするためのパイプライン ジョブが作成されます。 すべての入力をレビューし、ジョブ出力からモデルを収集できます。