Azure Cosmos DB の API を特定する
Azure Cosmos DB は、あらゆるサイズまたはスケールのアプリケーションに対応する Microsoft のフル マネージドでサーバーレスの分散型データベースであり、リレーショナルと非リレーショナル両方のワークロードをサポートします。 開発者は、PostgreSQL、MongoDB、Apache Cassandra など、好みのオープンソース データベース エンジンを使って、アプリケーションの構築と移行を迅速に行うことができます。 新しい Cosmos DB インスタンスをプロビジョニングするときに、使用するデータベース エンジンを選びます。 エンジンの選択は、格納するデータの種類、既存のアプリケーションをサポートする必要性、データ ストアを操作する開発者のスキルなど、さまざまな要因に依存します。
NoSQL 用 Azure Cosmos DB
Azure Cosmos DB for NoSQL は、ドキュメント データ モデルを使用するための Microsoft のネイティブな非リレーショナル サービスです。 それは、JSON ドキュメント形式でデータを管理し、NoSQL データ ストレージ ソリューションであるにもかかわらず、SQL 構文を使ってデータを操作します。
顧客データを含む Azure Cosmos DB データベースに対する SQL クエリは、次のようになります。
SELECT *
FROM customers c
WHERE c.id = "joe@litware.com"
次に示すように、このクエリの結果は、1 つ以上の JSON ドキュメントで構成されます。
{
"id": "joe@litware.com",
"name": "Joe Jones",
"address": {
"street": "1 Main St.",
"city": "Seattle"
}
}
Azure Cosmos DB for MongoDB
MongoDB は、データがバイナリ JSON (BSON) 形式で格納される一般的なオープン ソース データベースです。 Azure Cosmos DB for MongoDB を使うと、開発者は MongoDB クライアント ライブラリとコードを使って、Azure Cosmos DB のデータを操作できます。
MongoDB クエリ言語 (MQL) では、開発者が "オブジェクト" を使用して "メソッド" を呼び出す、オブジェクト指向のコンパクトな構文が使用されます。 たとえば、次のクエリでは、find メソッドを使用して、db オブジェクト内の products コレクションに対してクエリを実行します。
db.products.find({id: 123})
このクエリの結果は、次のような JSON ドキュメントで構成されます。
{
"id": 123,
"name": "Hammer",
"price": 2.99
}
PostgreSQL 用 Azure Cosmos DB
Azure Cosmos DB for PostgreSQL は、Azure の分散 PostgreSQL オプションです。 Azure Cosmos DB for PostgreSQL は PostgreSQL のネイティブなグローバル分散リレーショナル データベースであり、高度にスケーラブルなアプリを構築できるようデータを自動的にシャード化します。 他の PostgreSQL と同じように、単一ノード サーバー グループでアプリの構築を開始できます。 アプリのスケーラビリティとパフォーマンスの要件が高まるにつれて、テーブルを透過的に分散することで、複数のノードにシームレスにスケーリングできます。 PostgreSQL はリレーショナル データベース管理システム (RDBMS) であり、データのリレーショナル テーブルを定義します。たとえば、次のような製品のテーブルを定義できます。
| ProductID | ProductName | 価格 |
|---|---|---|
| 123 | Hammer | 2.99 |
| 162 | Screwdriver | 3.49 |
その後、次のような SQL を使ってこのテーブルのクエリを実行し、特定の製品の名前と価格を取得できます。
SELECT ProductName, Price
FROM Products
WHERE ProductID = 123;
このクエリの結果には、次のような製品 123 の行が含まれます。
| ProductName | 価格 |
|---|---|
| Hammer | 2.99 |
Azure Cosmos DB for Table
Azure Cosmos DB for Table は、Azure Table Storage と同様に、キー値テーブル内のデータを操作するために使われます。 それは、Azure Table Storage より高いスケーラビリティとパフォーマンスを提供します。 たとえば、次のように Customers という名前のテーブルを定義できます。
| パーティション キー | 行キー | 名前 | |
|---|---|---|---|
| 1 | 123 | Joe Jones | joe@litware.com |
| 1 | 124 | Samir Nadoy | samir@northwind.com |
その後、言語固有の SDK の 1 つで Table API を使って、サービス エンドポイントを呼び出し、テーブルからデータを取得できます。 たとえば、次の要求は、前出のテーブルの Samir Nadoy のレコードを含む行を返します。
https://endpoint/Customers(PartitionKey='1',RowKey='124')
Azure Cosmos DB for Apache Cassandra
Azure Cosmos DB for Apache Cassandra は、列ファミリ ストレージ構造を使用する一般的なオープンソース データベースである Apache Cassandra と互換性があります。 列ファミリは、リレーショナル データベースのテーブルに似たテーブルです。ただし、すべての行に同じ列が含まれる必要はありません。
たとえば、次のような Employees テーブルを作成できます。
| id | 名前 | Manager |
|---|---|---|
| 1 | Sue Smith | |
| 2 | Ben Chan | Sue Smith |
Cassandra では、SQL に基づく構文がサポートされています。そのため、クライアント アプリケーションでは、次のように Ben Chan のレコードを取得できます。
SELECT * FROM Employees WHERE ID = 2
Azure Cosmos DB for Apache Gremlin
Azure Cosmos DB for Apache Gremlin は、グラフ構造のデータで使われます。この構造のエンティティは、接続されたグラフ内のノードを形成する頂点として定義されます。 次のように、ノードは、リレーションシップを表す "エッジ" によって接続されます。
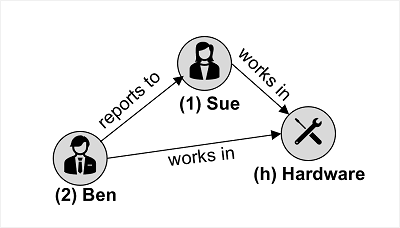
図の例は、2 種類の頂点 (従業員と部署) と、それらを接続するエッジ (従業員 "Ben" が従業員 "Sue" に報告を行い、両方の従業員が "ハードウェア" 部門で働く) を示しています。
Gremlin 構文には、頂点とエッジで動作する関数が含まれており、グラフでのデータの挿入、更新、削除、クエリを実行できます。 たとえば、次のコードを使用して、ID 1 の従業員 (Sue) に報告を行う Alice という名前の新しい従業員を追加できます。
g.addV('employee').property('id', '3').property('firstName', 'Alice')
g.V('3').addE('reports to').to(g.V('1'))
次のクエリは、ID 順にすべての "従業員" の頂点を返します。
g.V().hasLabel('employee').order().by('id')