データ ハブを探索する
データ ハブを使用すると、次の手順に示すように、ソース データおよびリンク サービスとやり取りして探索することができます。
Azure Synapse Studio の左側で、データ ハブをクリックします。
データ ハブから、ワークスペース内のプロビジョニングされた SQL プール データベースと SQL サーバーレス データベースのほか、ストレージ アカウントやその他のリンク サービスなどの外部データ ソースにアクセスできます。
データ ハブ (1) の [ワークスペース] (2) タブで、[データベース] の下にある [SQLPool01] (3) SQL プールを展開します。
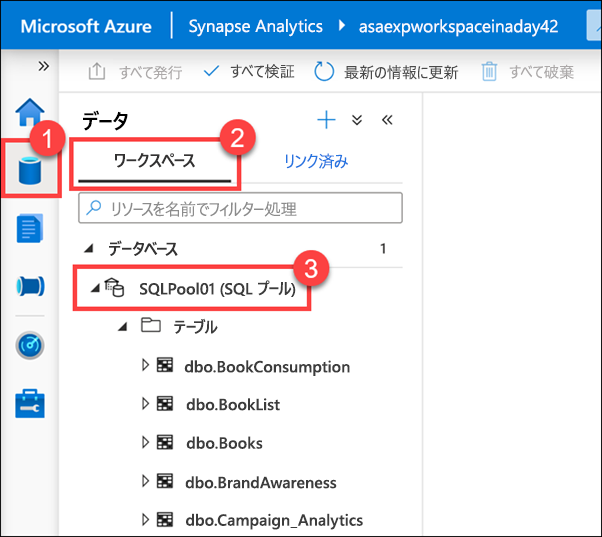
[テーブル]、[プログラミングとストアド プロシージャ] の順に展開します。
SQL プールの下に一覧表示されるテーブルには、SAP Hana、X、Azure SQL Database、オーケストレーション パイプラインからコピーされた外部ファイルなど、複数のソースからのデータが保存されています。 Synapse Analytics では、これらのデータ ソースを組み合わせて分析とレポート作成を行うことができ、すべてを 1 か所で行うことができます。
ストアド プロシージャなど、使い慣れたデータベース コンポーネントも表示されます。 ストアド プロシージャは、T-SQL スクリプトを使用して実行したり、オーケストレーション パイプラインの一部として実行したりできます。
[リンク] タブを選択し、[Azure Data Lake Storage Gen2] グループを展開して、ワークスペースの [プライマリ ストレージ] を展開します。
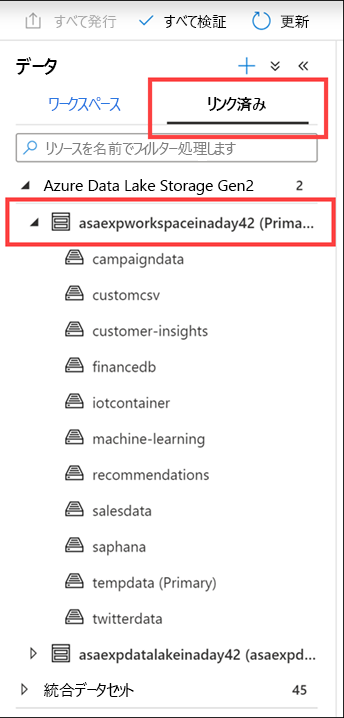
すべての Synapse ワークスペースには、プライマリ ADLS Gen2 アカウントが関連付けられています。 これは、データ レイクとして機能します。これは、オンプレミスのデータ ストアからコピーされたファイルなどのフラット ファイル、外部のサービスやアプリケーションから直接エクスポートされたデータまたはコピーされたデータ、テレメトリ データなどを格納するのに適した場所です。すべてが 1 か所にまとめられます。
この例では、ファイルとフォルダーを保持するコンテナーがいくつかあり、ワークスペース内から探索して使用することができます。 こちらには、たとえば、外部データベースからインポートされたマーケティング キャンペーン データ、CSV ファイル、財務情報のほか、機械学習アセット、IoT デバイス テレメトリ、SAP Hana データ、ツイートなどがあります。
すべてのデータが 1 か所に配置されているため、この場所で今すぐにプレビューを開始できます。
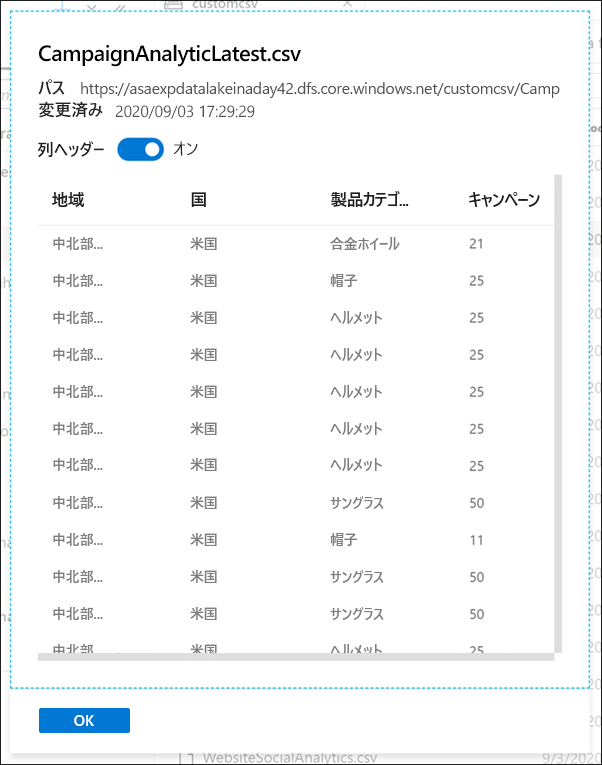
キャンペーン データを見てみましょう。
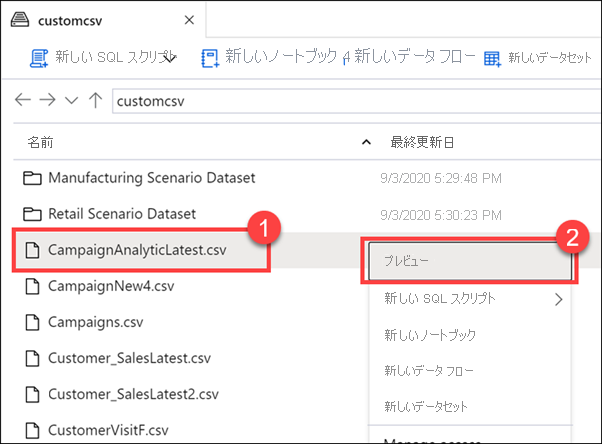
customcsv ストレージ コンテナーを選択します。

キャンペーン データをプレビューして、新しいキャンペーン名を調べましょう。
CampaignAnalyticsLatest.csv ファイル (1) を右クリックし、[プレビュー] (2) を選択します。
エクスプローラーの機能を使用すると、ファイルをすばやく検索して、それらに対してアクションを実行できます。ファイルの内容をプレビューしたり、新しい SQL スクリプトやノートブックを生成してファイルにアクセスしたり、新しいデータ フローまたはデータセットを作成したり、ファイルを管理したりすることができます。