演習 - 生成 AI アプリのパフォーマンスの評価を行う
生成 AI アプリを作成したい場合は、プロンプト フローを使用してチャット アプリケーションを開発します。 フローの実行後に応答を評価することで、アプリのパフォーマンスを評価できます。
個々のプロンプトを使用してフローをテストする
アクティブな開発においては、以下のようにコンピューティング セッションを実行しながらチャット機能を使用することで、作成中のチャット フローをテストできます。

チャット ウィンドウで個々のプロンプトを使用してフローをテストすると、指定した入力でフローが実行されます。 実行が成功すると、応答がチャット ウィンドウに表示されます。 また、最終的な応答がどのように構築されたかを理解するために、以下のようにフローの個別ノードそれぞれの出力を調べることもできます。

評価フローを使用してフローを自動的にテストする
チャット フローを一括で評価するためには、自動評価を実行します。 組み込みの自動評価を使用することも、独自の評価フローを作成することでカスタム評価を定義することもできます。
Microsoft キュレーション メトリックを使用して評価する
組み込みまたは Microsoft キュレーション メトリックには、以下のメトリックが含まれています。
パフォーマンスと品質:
- 一貫性:生成 AI アプリケーションが流れがスムーズで、文章として自然で、人間の言語に近い出力をどの程度上手く生成できるかを測定します。
- 流暢性:生成 AI アプリケーションの予測回答の言語能力を測定します。
- GPT 類似度:ソース データ (グラウンド トゥルース) 文と生成 AI アプリケーションによって生成された応答の類似度を測定します。
- F1 スコア:生成 AI アプリケーションの予測とソース データ (グラウンド トゥルース) の間の単語数の比を測定します。
- グラウンデッドネス:生成 AI アプリケーションによって生成された回答が、入力ソースからの情報とどの程度一致しているかを測定します。
- 関連性:生成 AI アプリケーションによって生成された応答がどの程度妥当かつ与えられた質問に直接的に関連しているかを測定します。
リスクと安全性:
- 自傷行為に関連するコンテンツ:生成 AI アプリケーションの自傷行為に関連するコンテンツの生成を行おうとする傾向を測定します。
- 憎悪に満ちた不公平なコンテンツ:生成 AI アプリケーションの憎悪に満ちた不公平なコンテンツを生成しようとする傾向を測定します。
- 暴力的なコンテンツ:生成 AI アプリケーションの暴力的なコンテンツを生成しようとする傾向を測定します。
- 性的なコンテンツ:生成 AI アプリケーションの性的なコンテンツを生成しようとする傾向を測定します。

組み込みの自動評価を使用してチャット フローを評価するには、以下の操作を行う必要があります。
- データセットを作成します。
- Azure AI Foundry ポータルで新しい自動評価を作成します。
- モデルによって生成された出力を含むフローまたはデータセットを選択します。
- 評価に使用したいメトリックを選択します。
- 評価フローを実行します。
- 結果を確認します。

ヒント
評価と監視のメトリックの詳細を確認する
カスタム評価メトリックを作成する
または、独自のカスタム評価フローを作成して、その中でチャット フローの出力をどのように評価するべきかを定義することもできます。 たとえば、Python コードを使用したり、大規模言語モデル (LLM) ノードを使用して AI 支援メトリックを作成することで、出力を評価できます。 簡単な例で評価フローがどのように機能するかを調べてみましょう。
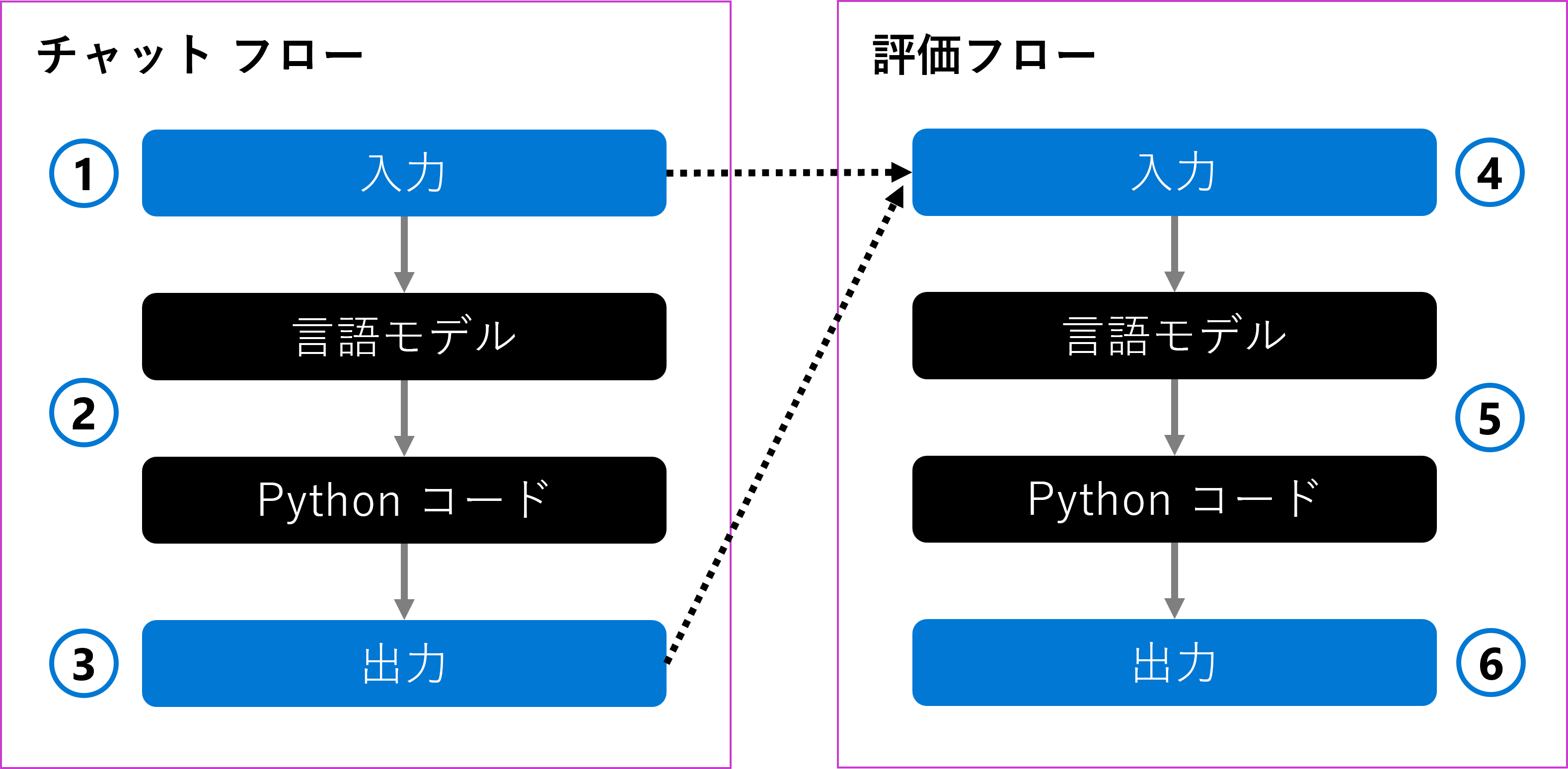
ユーザーの質問を入力として受け取るチャット フローを作成できます (1)。 フローは、言語モデルを使用して入力を処理し、Python コードを使用して回答をフォーマットします (2)。 最後に、出力として応答を返します (3)。
チャット フローを評価するには、評価フローを作成します。 評価フローは、元のユーザーの質問と生成された出力を入力として受け取ります (4)。 フローはそれを言語モデルを使用して評価し、Python コードを使用して評価メトリックを定義し (5)、これが出力として返されます (6)。
評価フローを作成するときに、チャット フローを評価する方法を選択できます。 言語モデルを使用して、独自のカスタム AI 支援メトリックを作成できます。 プロンプトで、測定したいメトリックと、言語モデルで使用する採点スケールを定義できます。 たとえば、以下のような評価プロンプトが考えられます。
# Instructions
You are provided with the input and response of a language model that you need to evaluate on user satisfaction.
User satisfaction is defined as whether the response meets the user’s question and needs, and provides a comprehensive and appropriate answer to the question.
Assign each response a score of 1 to 5 for user satisfaction, with 5 being the highest score.
評価フローを作成したら、テスト データセットを提供し評価フローを実行することで、チャット フローを評価できます。

評価フロー内で言語モデルを使用する場合、以下のように出力トレース内で結果を確認できます。

さらに、評価フローに Python ノードを追加して、テスト データセット内のすべてのプロンプトの結果を集約し、全体的なメトリックを返すことができます。
ヒント
Azure AI Foundry ポータルで評価フローを開発する方法を学習します。