モデルのパフォーマンスを評価する
モデルのパフォーマンスをさまざまなフェーズで評価することは、その有効性と信頼性を確保するうえで不可欠です。 モデルを評価するためのさまざまなオプションを見ていく前に、評価可能なアプリケーションの側面を確認してみましょう。
生成 AI アプリを開発する場合、チャット アプリケーションで言語モデルを使用して応答を生成します。 どのモデルをアプリケーションに統合するかを決定するために、個々の言語モデルのパフォーマンスを評価できます。
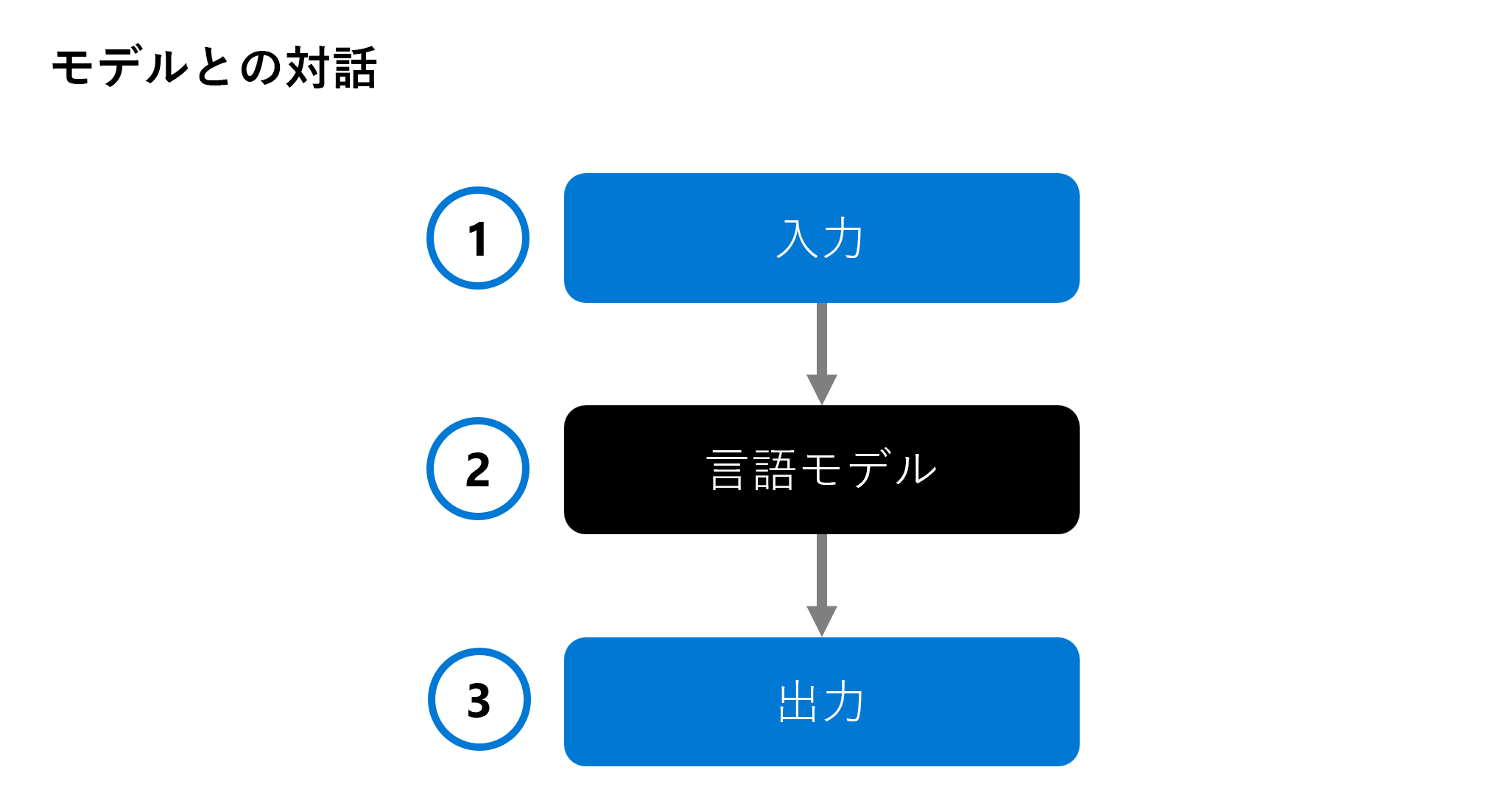
入力 (1) が言語モデル (2) に提供され、応答が出力 (3) として生成されます。 その後、入力と出力の分析が行われ、必要に応じて、予想される定義済み出力と比較され、モデルが評価されます。
生成 AI アプリを開発する場合、言語モデルをチャット フローに統合します:
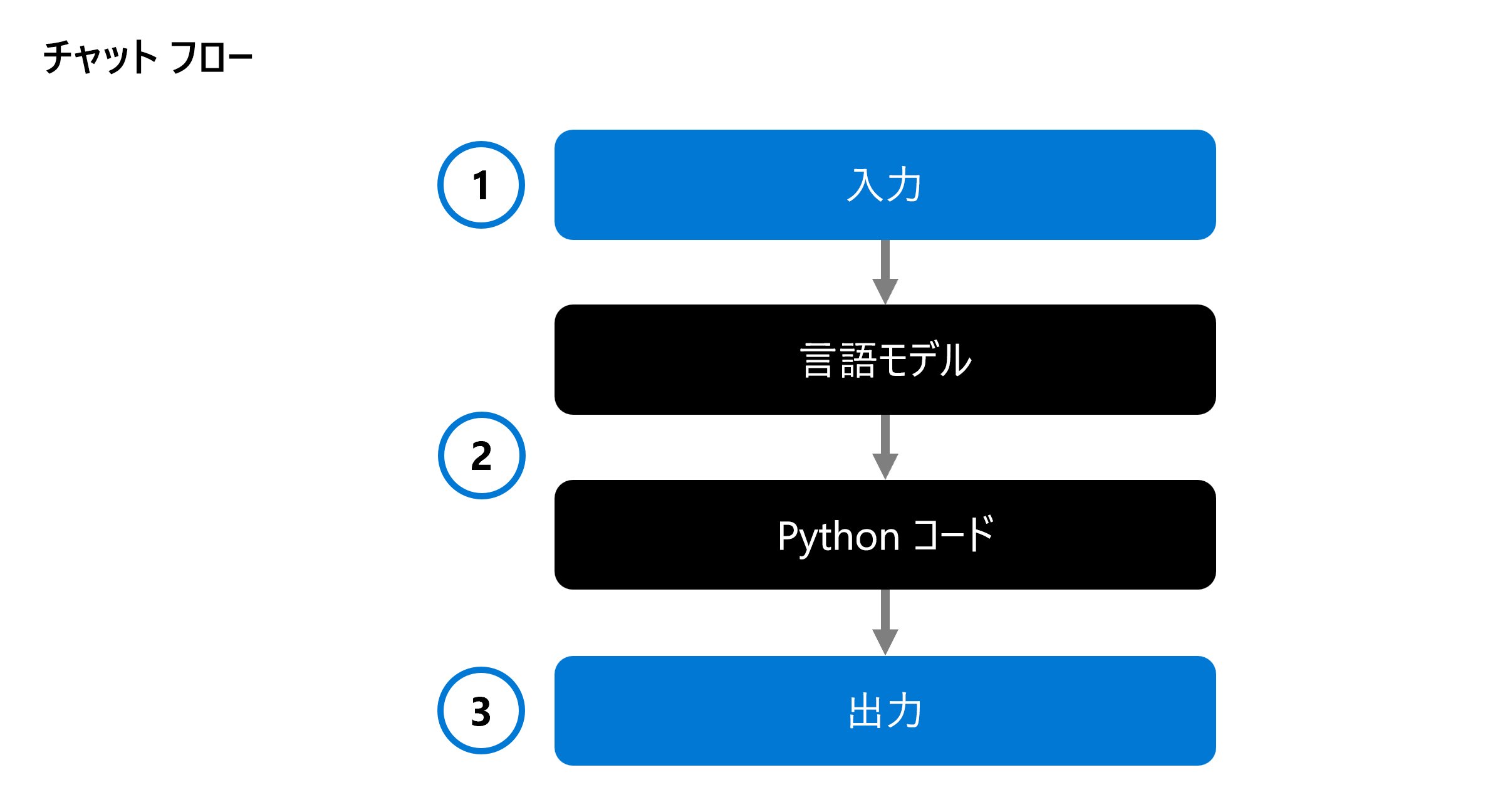
チャット フローでは実行可能フローが調整可能で、複数の言語モデルと Python コードを組み合わせることができます。 フローは入力 (1) を受け取り、さまざまなノード (2) を実行して処理し、出力 (3) を生成します。 完全なチャット フローとその個々のコンポーネントを評価することができます。
ソリューションを評価する場合、最初に個々のモデルをテストし、最終的に完全なチャット フローをテストすることで、生成 AI アプリが想定どおりに動作しているかどうかを検証できます。
モデルとチャット フロー、または生成 AI アプリを評価するためのアプローチをいくつか見てみましょう。
モデル ベンチマーク
モデル ベンチマークは、モデルとデータセット全体で一般公開されているメトリックです。 これらのベンチマークは、他との比較によってモデルのパフォーマンスを把握するのに役立ちます。 一般的に使用されるベンチマークを次に示します。
- 精度: モデルによって生成されたテキストと、データセットに従っている正しい応答を比較します。 生成されたテキストが回答と完全に一致する場合は結果が 1 になり、それ以外の場合は 0 になります。
- 一貫性: モデルの出力の流れがスムーズで、文章として自然であり、人間の言語に近いかどうかを測定します
- 流暢性: 生成されたテキストが、文法規則、構文構造、ボキャブラリの適切な使用法にどの程度従っているか、その結果、応答が言語的に正しく、自然に聞こえるようになっているかを評価します。
- GPT 類似度: グラウンド トゥルース文 (またはドキュメント) と AI モデルによって生成された予測文の間のセマンティック類似性を定量化します。
Azure AI Foundry ポータルでは、モデルをデプロイする前に、使用可能なすべてのモデルについて、モデル ベンチマークを確認することができます:

手動評価
手動評価には、モデルの応答の質を評価する人間の評価者が必要です。 このアプローチは、コンテキストの関連性やユーザーの満足度など、自動化されたメトリックで見逃される可能性のある側面に関する分析情報を提供します。 人間の評価者は、関連性、情報の質や量、エンゲージメントなどの条件に基づいて応答を評価できます。
従来の機械学習メトリック
従来の機械学習メトリックも、モデルのパフォーマンスを評価するのに役立ちます。 そのメトリックの 1 つが F1 スコアであり、生成された応答とグラウンド トゥルース応答で共有される単語数の比率を測定します。 F1 スコアは、テキスト分類や情報取得など、精度と再現率が重要なタスクに役立ちます。
AI 支援メトリック
AI 支援メトリックでは、高度な手法を使用してモデルのパフォーマンスを評価します。 これらのメトリックを次に示します。
- リスクと安全性メトリック: これらのメトリックでは、モデルの出力に関連する潜在的なリスクと安全性に関する懸念を評価します。 これにより、有害なコンテンツや偏ったコンテンツがモデルによって生成されないようにできます。
- 一般的な品質メトリック: これらのメトリックでは、創造性、一貫性、目的のスタイルやトーンへの準拠などの要因を考慮して、生成されたテキストの全体的な品質を評価します。