SQL Database Hyperscale について理解する
Azure SQL Database には長年、データベースあたりのストレージが 4 TB という制限があります。 この制限は、Azure インフラストラクチャの物理的な制限によるものです。 Azure SQL Database Hyperscale は革新的で、データベースを 100 TB 以上にできます。 Hyperscale では、新しい水平スケーリング技術を導入していて、データ サイズの増加に応じてコンピューティング ノードを追加できます。 Hyperscale のコストは Azure SQL Database のコストと同じですが、ストレージにテラバイトあたりのコストがかかります。 一度 Azure SQL Database を Hyperscale に切り替えると、それを "通常の" Azure SQL Database に戻すことはできない点に注意する必要があります。 Hyperscale は、必要に応じて適切にスケーリングできるアーキテクチャの機能です。
Azure SQL Database Hyperscale は、個別にスケーラブルなコンピューティング リソースとストレージ リソースを使用して優れた柔軟性と高パフォーマンスを提供するため、ほとんどのビジネス ワークロードにとって優れたオプションとなります。
Hyperscale では、さまざまなデータ エンジンのセマンティクスが枝分かれしているクエリ処理エンジンと、データの長期的なストレージと持続性を提供するコンポーネントが分かれています。 これにより、ストレージ容量をスムーズに必要なだけスケールアウトできます。
Azure SQL Database の Hyperscale サービス レベルは、仮想コアベースの購入モデルにおける最新のサービス レベルです。 このサービス レベルは、拡張性の高いストレージおよびコンピューティング パフォーマンス レベルであり、Azure を利用して、General Purpose および Business Critical サービス レベルの制限を大きく超えて、Azure SQL Database 用のストレージおよびコンピューティング リソースをスケールアウトします。
メリット
Hyperscale サービス レベルでは、クラウド データベースにおいて従来見られた実質的な制限の多くが取り除かれます。 他のほとんどのデータベースは 1 つのノードで使用可能なリソースによって制限されますが、Hyperscale サービス レベルのデータベースにはそのような制限はありません。 ストレージ アーキテクチャの柔軟性が高く、必要に応じてストレージが拡張されます。 実際、Hyperscale データベースの作成時には最大サイズは定義されません。 Hyperscale データベースは必要に応じて拡大し、使用している容量に対してのみ課金されます。 読み取り集中型ワークロードでは、Hyperscale サービス レベルにより、読み取りワークロードのオフロード用に必要に応じて追加のレプリカがプロビジョニングされ、迅速なスケールアウトが提供されます。
さらに、データベース バックアップの作成に必要な時間や、スケールアップまたはスケールダウンに必要な時間は、データベース内のデータの量に関連しなくなっています。 Hyperscale データベースは瞬時にバックアップできます。 また、数十テラバイトのデータベースを、数分でスケールアップまたはスケールダウンできます。 この機能により、初期構成の選択によって縛り付けられることを心配する必要はなくなります。 Hyperscale では、数日または数時間もかからず、数分で実行される高速なデータベース復元も提供されます。
ハイパースケールでは、ワークロードの需要に基づいて迅速なスケーラビリティを提供します。
スケールアップ/ダウン - CPU やメモリなどのリソースの観点で主要なコンピューティング サイズをスケールアップしてから、一定時間でスケールダウンできます。 ストレージは共有されるため、スケールアップとスケールダウンはデータベース内のデータ量にリンクされません。
スケールイン/アウト - 読み取り要求を処理するために使用できる 1 つ以上のコンピューティング レプリカをプロビジョニングする機能も提供されます。 つまり、これらの追加のコンピューティング レプリカを読み取り専用レプリカとして使用し、主なコンピューティングから読み取りワークロードをオフロードできます。 読み取り専用に加え、これらのレプリカは、プライマリからフェールオーバーするホット スタンバイとしても機能します。
これらの追加のコンピューティング レプリカのそれぞれのプロビジョニングは、オンライン操作で、一定時間で行うことができます。 これらの読み取り専用コンピューティング レプリカに接続するには、接続文字列の ApplicationIntent 引数を ReadOnly に設定してください。 ReadOnly のアプリケーションの目的を持つ接続はすべて、読み取り専用コンピューティング レプリカのいずれかに自動的にルーティングされます。
Hyperscale では、クエリ処理エンジンと、データの長期的なストレージと持続性を提供するコンポーネントが分かれています。 このアーキテクチャにより、ストレージ容量を必要なだけスムーズにスケーリングする機能 (初期ターゲットは 100 TB) と、コンピューティング リソースを迅速にスケーリングする機能が提供されます。
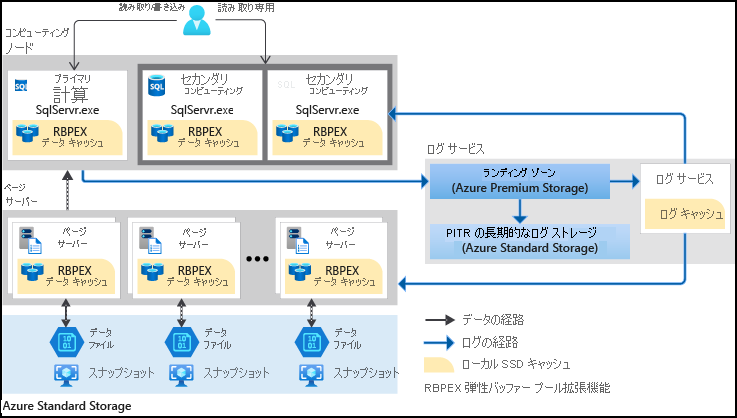
セキュリティに関する考慮事項
Hyperscale サービス レベルのセキュリティは、他の Azure SQL Database レベルと同じ優れた機能を共有します。 下の図に示すように多層防御アプローチによって保護され、外側から内側に移動します。
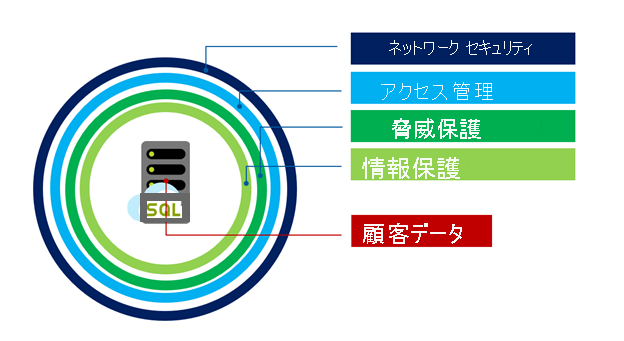
ネットワーク セキュリティは、防御の第 1 層であり、IP ファイアウォール規則を使用して、発信元 IP アドレスと Virtual Network ファイアウォール規則に基づいてアクセスを許可し、仮想ネットワーク内の選択したサブネットから送信される通信を受け入れる機能を許可します。
アクセス管理は、以下の認証方法を使用して提供され、ユーザーが要求するユーザーであることを確認します。
- SQL 認証
- Microsoft Entra 認証
- Microsoft Entra プリンシパルの Windows 認証 (プレビュー)
Azure SQL Database Hyperscale では、行レベルのセキュリティもサポートします。 行レベル セキュリティにより、顧客はクエリを実行するユーザーの特性に基づき、データベース テーブルの行へのアクセスを制御できます (たとえば、グループのメンバーシップや実行コンテキストなど)。
監査機能と脅威検出機能にける脅威保護機能。 SQL Database と SQL Managed Instance の監査はデータベース アクティビティを追跡し、顧客が所有する Azure ストレージ アカウントの監査ログにデータベース イベントを記録することによって、セキュリティ標準のコンプライアンスを維持できるようにします。 Advanced Threat Protection は、追加料金でサーバーごとに有効にすることができます。このサービスでは、ログを分析して、通常とは異なる動作や、データベースへのアクセスやデータベースの悪用を試みる害を及ぼす可能性のある試行を検出します。 SQL インジェクション、潜在的なデータ侵入、ブルートフォース攻撃などの疑わしいアクティビティや、特権の昇格と不正な資格情報の使用を検出するアクセス パターンの異常に対してアラートが作成されます。
Information Protection は、次のさまざまな方法で提供されます。
- トランスポート層セキュリティ (転送中の暗号化)
- Transparent Data Encryption (保存時の暗号化)
- Azure Key Vault のキー管理
- Always Encrypted (使用時の暗号化)
- 動的データ マスク
パフォーマンスに関する考慮事項
Hyperscale サービス レベルの対象として意図されているのは、大規模なオンプレミスの SQL Server データベースを備えていて、クラウドに移行することによりアプリケーションを最新化することを考えているお客様、または既に Azure SQL Database を使用しており、データベースのサイズを増大するために大幅な拡張を望むお客様です。 ハイパースケールでは、高いパフォーマンスと高いスケーラビリティを必要としているお客様も対象になります。
Hyperscale には、次のパフォーマンス機能が用意されています。
- サイズに関係なく、コンピューティング リソースに対する IO の影響もなく、ほぼ瞬間的に行われるデータベース バックアップ (Azure BLOB Storage に格納されたファイル スナップショットに基づく)。
- 数時間あるいは数日かからずに数分間で行われる迅速なデータベース復元 (ファイル スナップショットに基づく) (データ操作の規模ではない)。
- データ ボリュームに関係なく、高いトランザクション ログ スループットと速いトランザクション コミット時間による、全体的に高いパフォーマンス。
- 迅速なスケールアウト - 読み取りワークロードのオフロード用と、ホット スタンバイ用に、1 つ以上の読み取り専用レプリカをプロビジョニングできます。
- 迅速なスケールアップ - 大きいワークロードに対応する必要があるときはコンピューティング リソースを一定の時間でスケールアップでき、必要がなくなったらコンピューティング リソースをスケールダウンして戻すことができます。
注意
SQL Database Hyperscale では、次の機能はサポートされません。
- SQL Managed Instance
- エラスティック プール
- geo レプリケーション
- Query Performance Insights
Azure SQL Database Hyperscale のデプロイ
Hyperscale サービス レベルで Azure SQL Database をデプロイするには、以下の手順を実行します。
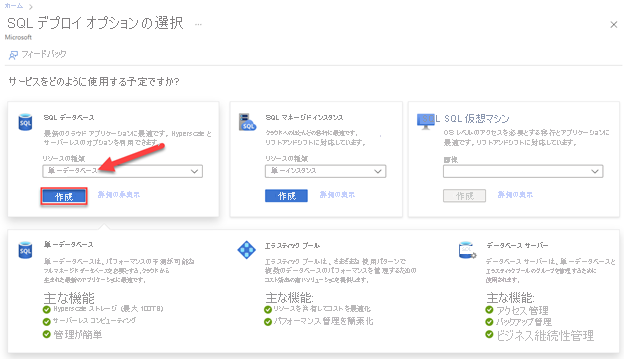
[SQL デプロイ オプションの選択] ページを開きます。
[SQL データベース] で、 [リソースの種類] を [単一データベース] に設定し、 [作成] を選択します。
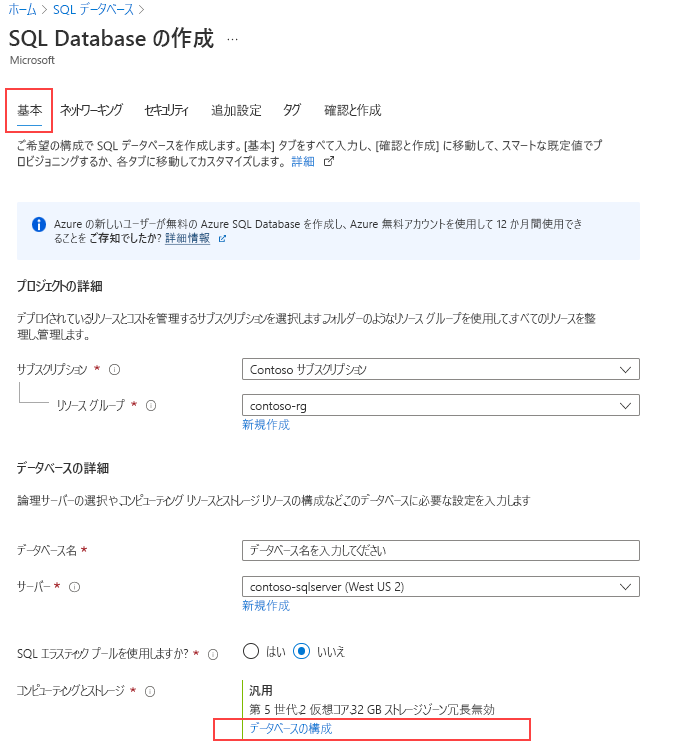
[SQL Database の作成] ページの [基本] タブで、目的のサブスクリプション、リソース グループ、およびデータベース名を選択します。
サーバーの [新規作成] リンクを選択し、サーバー名、サーバー管理者のログインとパスワード、場所などの新しいサーバーに関する情報を入力します。
[コンピューティングとストレージ] で、[データベースの構成] リンクを選択します。
[サービス レベル] で、[Hyperscale] を選択します。
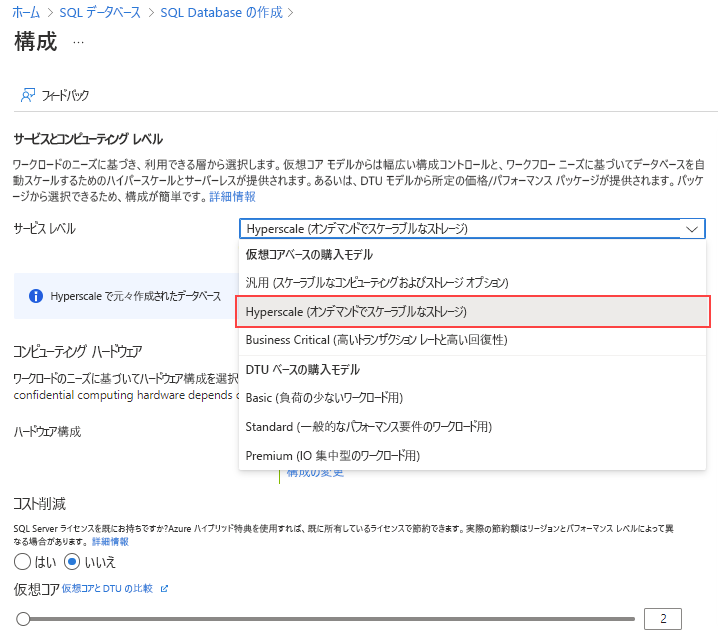
[ハードウェア構成] で、[構成の変更] リンクを選択します。 使用可能なハードウェア構成を確認し、お使いのデータベースに最適な構成を選択します。 この例では、[Gen5] 構成を選択します。
[OK] を選択して、ハードウェアの生成を確認します。
必要に応じて、データベースの仮想コアの数を増加する場合は、[仮想コア] のスライダーを調整します。 この例では、[2 つの仮想コア] を選択します。
[高可用性セカンダリ レプリカ] のスライダーを調整して、1 つの高可用性 (HA) レプリカを作成します。 [適用] を選択します。
ページの下部にある [Next: Networking](次へ: ネットワーク) を選択します。
![Azure SQL Database Hyperscale をプロビジョニングしているときの [ネットワーク] ページ](../../wwl-data-ai/deploy-paas-solutions-with-azure-sql/media/module-22-plan-implement-final-42.png)
[ネットワーク] タブの [ファイアウォール規則] で、[現在のクライアント IP アドレスを追加する] を [はい] に設定します。 [Azure サービスおよびリソースにこのサーバー グループへのアクセスを許可する] を [いいえ] に設定したままにします。
ページの下部で [次へ: セキュリティ] を選択します。
[確認および作成] タブで、 [作成] を選択します。
![Azure SQL Database Hyperscale をプロビジョニングしているときの [確認と作成] ページ](../../wwl-data-ai/deploy-paas-solutions-with-azure-sql/media/module-22-plan-implement-final-44.png)