パフォーマンスとセキュリティを調べる
Azure エコシステムには、Azure 仮想マシン上の SQL Server インスタンスに対して、いくつかのパフォーマンスとセキュリティのオプションが用意されています。 各オプションには、ワークロードの容量とパフォーマンスの要件を満たす、さまざまなディスクの種類など、いくつかの機能が用意されています。
ストレージに関する考慮事項
オンプレミスのインスタンスでも、Azure VM にインストールされていても、SQL Server で信頼性の高いアプリケーション パフォーマンスを提供するには、優れたパフォーマンスのストレージが必要です。 Azure には、ワークロードのニーズを満たすためのさまざまなストレージ ソリューションが用意されています。 Azure にはさまざまな種類のストレージ (BLOB、ファイル、キュー、テーブル) が用意されていますが、SQL Server のワークロードには、ほとんどの場合、Azure マネージド ディスクが使用されます。 例外として、フェールオーバー クラスター インスタンスはファイル ストレージに構築でき、バックアップには BLOB ストレージが使用されます。 Azure のマネージド ディスクは、Azure VM に提供されるブロック レベルのストレージ デバイスとして機能します。 マネージド ディスクには、99.999% の可用性、スケーラブルなデプロイ (1 つのリージョンでサブスクリプションあたり最大 50,000 の VM ディスクを使用可能)、障害発生時に高いレベルの回復性を提供するための可用性セットおよび可用性ゾーンとの統合など、数多くのメリットがあります。
すべての Azure マネージド ディスクで、2 種類の暗号化が提供されています。 Azure のサーバー側暗号化は、ストレージ サービスによって提供され、保存時の暗号化として機能します。 Azure Disk Encryption では、Windows の BitLocker および Linux の DM-Crypt を使用して、VM 内の OS ディスクとデータ ディスクの暗号化が提供されます。 どちらのテクノロジも Azure Key Vault と統合され、独自の暗号化キーを取り込むことができます。
各 VM には、少なくとも 2 つのディスクが関連付けられています。
オペレーティング システム ディスク - 各仮想マシンには、ブート ボリュームが含まれるオペレーティング システム ディスクが必要です。 このディスクは、Windows プラットフォームの仮想マシンの場合は C: ドライブ、Linux の場合は /dev/sda1 になります。 オペレーティング システムは、オペレーティング システム ディスクに自動的にインストールされます。
一時ディスク - 各仮想マシンには、一時ストレージに使用される 1 つのディスクが含まれます。 このストレージは、ページ ファイルやスワップ ファイルなど、持続性を必要としないデータに使用されます。 このディスクは一時的なものであるため、データベースやトランザクション ログ ファイルなどの重要な情報を格納するためには使用しないでください。仮想マシンのメンテナンスや再起動の間に失われます。 このドライブは、Windows では D:\ として、また Linux の場合は /dev/sdb1 としてマウントされます。
さらに、SQL Server を実行する Azure VM にはデータ ディスクを追加することができ、追加する必要があります。
- データ ディスク - Azure portal ではデータ ディスクという用語が使用されますが、実際には VM に追加されるマネージド ディスクにすぎません。 Windows の記憶域スペースまたは Linux の論理ボリューム管理を使用して、これらのディスクをプールし、使用可能な IOPS とストレージ容量を増やすことができます。
さらに、各ディスクは次のいずれかの種類にすることができます。
| 機能 | Ultra Disk | Premium SSD | Standard SSD | Standard HDD |
|---|---|---|---|---|
| ディスクの種類 | SSD | SSD | SSD | HDD |
| 最適な用途 | IO 集中型のワークロード | パフォーマンスに影響されやすいワークロード | 軽量なワークロード | バックアップ、重要でないワークロード |
| 最大ディスク サイズ | 65,536 GiB | 32,767 GiB | 32,767 GiB | 32,767 GiB |
| 最大スループット | 2,000 MB/秒 | 900 MB/秒 | 750 MB/秒 | 500 MB/秒 |
| 最大 IOPS | 160,000 | 20,000 | 6,000 | 2,000 |
Azure での SQL Server のベスト プラクティスとしては、Premium ディスクをプールして使用し、IOPS とストレージ容量を向上させることをお勧めします。 データ ファイルは、Azure ディスク上の読み取りキャッシュを使用する独自のプールに格納する必要があります。
トランザクション ログ ファイルにはこのキャッシュによるメリットがないため、それらのファイルはキャッシュなしの独自プールに格納する必要があります。 TempDB は、必要に応じて、独自のプールに格納することも、VM が実行されている物理サーバーに物理的に接続されているため待機時間が短い VM の一時ディスクを使用することもできます。 Premium SSD を適切に構成すると、待機時間はミリ秒 1 桁になります。 それより短い待機時間が必要なミッション クリティカルなワークロードの場合は、Ultra SSD を考慮する必要があります。
セキュリティに関する考慮事項
仮想マシンで実行されている SQL Server に適合したソリューションを構築できるようにする、Azure が準拠している業界の規制と標準がいくつかあります。
Microsoft Defender for SQL
Microsoft Defender for SQL は、脆弱性評価やセキュリティ アラートなどの Azure Security Center のセキュリティ機能を提供します。
Azure Defender for SQL を使用して、SQL Server インスタンスとデータベースの潜在的な脆弱性を特定して軽減できます。 脆弱性評価機能は、SQL Server 環境の潜在的なリスクを検出し、それらを修復するのに役立ちます。 セキュリティの状態に関する分析情報や、セキュリティの問題を解決するための実行可能な手順が示されます。
Azure Security Center
Azure Security Center は、データ環境のいくつかのセキュリティ側面を改善する機会を評価して提供する統合セキュリティ管理システムです。 Azure Security Center は、すべてのハイブリッド クラウド資産のセキュリティ正常性の包括的なビューを提供します。
パフォーマンスに関する考慮事項
既存のオンプレミス SQL Server パフォーマンス機能のほとんどは、Azure 仮想マシン (VM) でも使用できます。 提供されるオプションの 1 つはデータ圧縮です。これは、データベースのサイズを小さくしながら、I/O 集中型ワークロードのパフォーマンスを向上させることができます。 同様に、テーブルとインデックスのパーティション分割は、大規模なテーブルのクエリ パフォーマンスを向上させつつ、一方でパフォーマンスとスケーラビリティを向上させることもできます。
テーブルのパーティション分割
テーブルのパーティション分割には多くの利点がありますが、多くの場合、この方法が考慮されるのは、クエリのパフォーマンスを低下させるほどテーブルが大きくなった場合のみです。 テーブルのパーティション分割の候補となるテーブルを特定することで、中断や介入を減らせる可能性があります。 パーティション列を使用してデータをフィルター処理すると、テーブル全体ではなく、データのサブセットのみがアクセスすることができます。 同様に、パーティション分割されたテーブルのメンテナンス操作では、特定のパーティション内の特定のデータを圧縮したり、インデックスの特定のパーティションを再構築したりすることで、メンテナンス期間が短縮されます。
テーブル パーティションを定義する場合は、次の 4 つの主要な手順が必要です。
- ファイル グループの作成。パーティションの作成時に関連するファイルを定義します。
- パーティション関数の作成。指定した列に基づいてパーティション規則を定義します。
- パーティション構成の作成。各パーティションのファイル グループを定義します。
- パーティション分割するテーブル。
次の例では、2021 年 1 月 1 日から 2021 年 12 月 1 日までのパーティション関数を作成し、パーティションをさまざまなファイル グループに分散する方法を示します。
-- Partition function
CREATE PARTITION FUNCTION PartitionByMonth (datetime2)
AS RANGE RIGHT
-- The boundary values defined is the first day of each month, where the table will be partitioned into 13 partitions
FOR VALUES ('20210101', '20210201', '20210301',
'20210401', '20210501', '20210601', '20210701',
'20210801', '20210901', '20211001', '20211101',
'20211201');
-- The partition scheme below will use the partition function created above, and assign each partition to a specific filegroup.
CREATE PARTITION SCHEME PartitionByMonthSch
AS PARTITION PartitionByMonth
TO (FILEGROUP1, FILEGROUP2, FILEGROUP3, FILEGROUP4,
FILEGROUP5, FILEGROUP6, FILEGROUP7, FILEGROUP8,
FILEGROUP9, FILEGROUP10, FILEGROUP11, FILEGROUP12);
-- Creates a partitioned table called Order that applies PartitionByMonthSch partition scheme to partition the OrderDate column
CREATE TABLE Order ([Id] int PRIMARY KEY, OrderDate datetime2)
ON PartitionByMonthSch (OrderDate) ;
GO
データ圧縮
SQL Server には、データを圧縮するためのさまざまなオプションが用意されています。 SQL Server では圧縮したデータを 8 KB のページに保存します。データを圧縮すると、1 ページに格納できるデータの行数が増えるため、クエリで読み取るページ数を減らすことができます。 読み取るページの数が減ることには、2 つのメリットがあります。1 つが物理的な I/O の回数を減らせる点、もう 1 つが、バッファ プールに保存できる行数が増え、メモリの使用を効率化できる点です。 必要に応じて、データベース ページの圧縮を有効にすることをお勧めします。
圧縮のトレードオフとしては、若干の CPU オーバーヘッドが発生することが挙げられます。もっとも、プロセッサの使用量が増大しても、記憶域の I/O に関するメリットの方が上回ることがほとんどです。
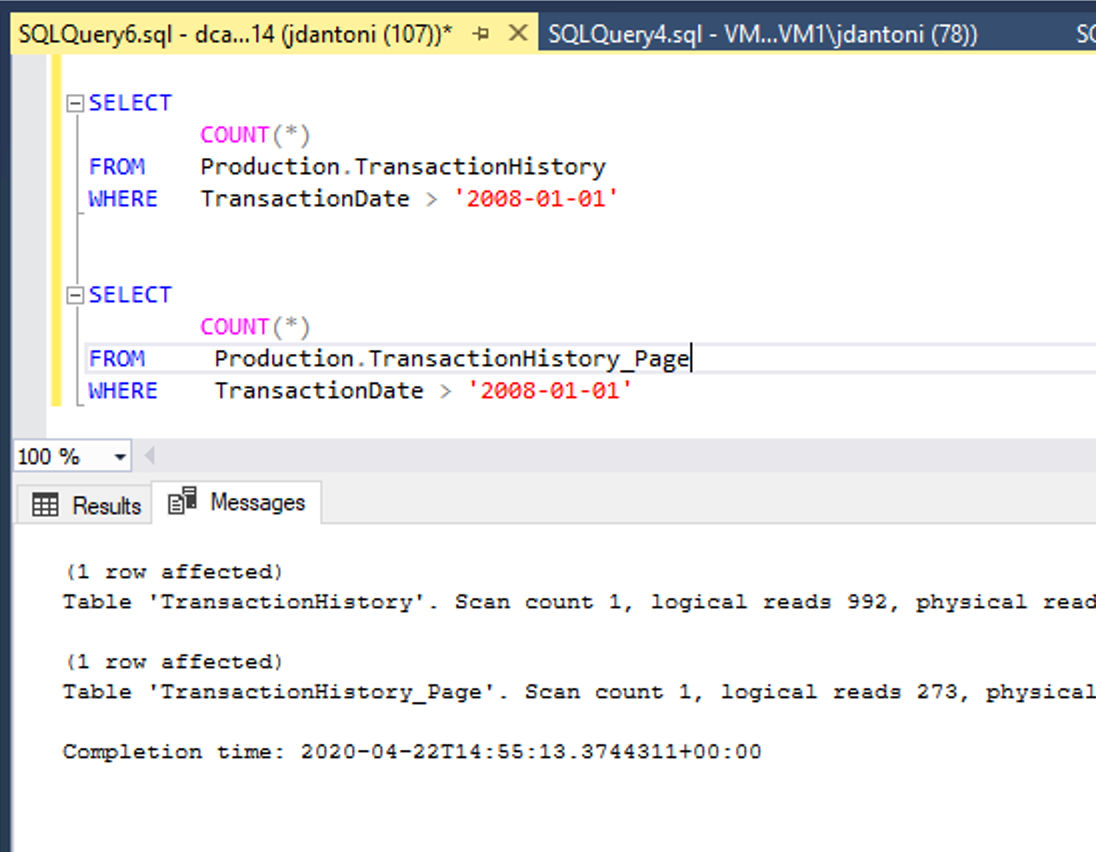
上の画像は、このパフォーマンス面のメリットを示したものです。 テーブルはインデックスが同じで、唯一の違いは、Production.TransactionHistory_Page テーブルの方ではクラスター化インデクスと非クラスター化インデックスにページ圧縮を実施しているという点です。 ページ圧縮を実施したオブジェクトに対するクエリの方が、圧縮をしていないオブジェクトを使用したクエリよりも論理読み取りの回数が 72% 少なくなっています。
SQL Server では、オブジェクト レベルで圧縮が実施されます。 各インデックスまたはテーブルを個別に圧縮できるほか、パーティション単位に分割されたテーブルまたはインデックス内部のパーティションを圧縮することもできます。 領域をどの程度節約できるかは、システム ストアド プロシージャ sp_estimate_data_compression_savings を使うと評価することができます。 SQL Server 2019 よりも前のバージョンでは、このプロシージャが列ストア インデックスと列ストア アーカイブ圧縮のいずれもサポートしていませんでした。
行圧縮 - 行圧縮はごく基本的なものであり、あまり大きなオーバーヘッドは発生しません。しかし、ページ圧縮と同水準 (必要な記憶領域の削減率により測定) の圧縮にはなりません。 行圧縮では、1 行内の各列の値をそれぞれ、その値を格納するうえで必要最小限の領域を使用して格納するのが基本です。 integer、float、decimal のような数値データ型には、可変長の保存形式を使用します。また、固定長の文字列の保存にも可変長の形式を使用します。
ページ圧縮 - ページ圧縮は、行圧縮の上位集合に当たるものです。ページ圧縮では、その実行に先立ち、全ページに行圧縮を行います。 そのうえで、プレフィックス圧縮とディクショナリ圧縮と呼ばれる 2 つの手法をデータに適用します。 プレフィックス圧縮では、1 つの列の中の冗長なデータが除去され、ページ ヘッダーに戻るポインターが保存されます。 その後はディクショナリ圧縮により、繰り返し出てくる値を検索のうえポインターに置換して、記憶領域をさらに削減します。 データの冗長性が高いほど、データを圧縮した場合の領域の節約幅が大きくなります。
列ストア アーカイブ圧縮 - 列ストア オブジェクトは必ず圧縮されますが、アーカイブ圧縮を使用するとさらに圧縮することができます。アーカイブ圧縮では、データに Microsoft XPRESS という圧縮アルゴリズムを使用します。 このタイプの圧縮は、読み取りの頻度があまり高くないものの、規制または事業上の理由から保管が必要なデータに特に適しています。 このデータはさらに圧縮できるものの、I/O 削減によるパフォーマンス面のメリットよりも、圧縮解除に伴う CPU コストの方が上回る傾向にあります。
追加オプション
運用環境のワークロードに対して検討できるその他の SQL Server 機能とアクションの一覧を次に示します。
- バックアップ圧縮を有効にします
- データ ファイルの瞬時初期化を有効にします
- データベースの自動拡張を制限します
- データベースの自動圧縮/自動終了を無効にする
- システム データベースも含め、すべてのデータベースをデータ ディスクに移動します
- SQL Server エラー ログとトレース ファイルのディレクトリをデータ ディスクに移動します
- SQL Server のメモリ制限を設定する
- Lock Pages in Memory を有効にする
- OLTP の負荷の高い環境でアドホック ワークロードの最適化を有効にする
- クエリ ストアを有効にします。
- DBCC CHECKDB、インデックスの再構成、インデックス再構築、統計更新の各ジョブを実行する SQL Server エージェント ジョブのスケジュールを設定する
- トランザクション ログ ファイルの正常性とサイズを監視および管理する
パフォーマンスのベスト プラクティスの詳細については、「Azure VM 上の SQL Server のベスト プラクティス」を参照してください。