Azure Data Factory コンポーネントを理解する
Azure サブスクリプションには、1 つ以上の Azure Data Factory インスタンスが含まれている場合があります。 Azure Data Factory は、4 つのコア コンポーネントで構成されています。 これらのコンポーネントの連携によって実現するプラットフォームを基盤として、データ移動とデータ変換のステップを含んだデータ主導型のワークフローを作成することができます。
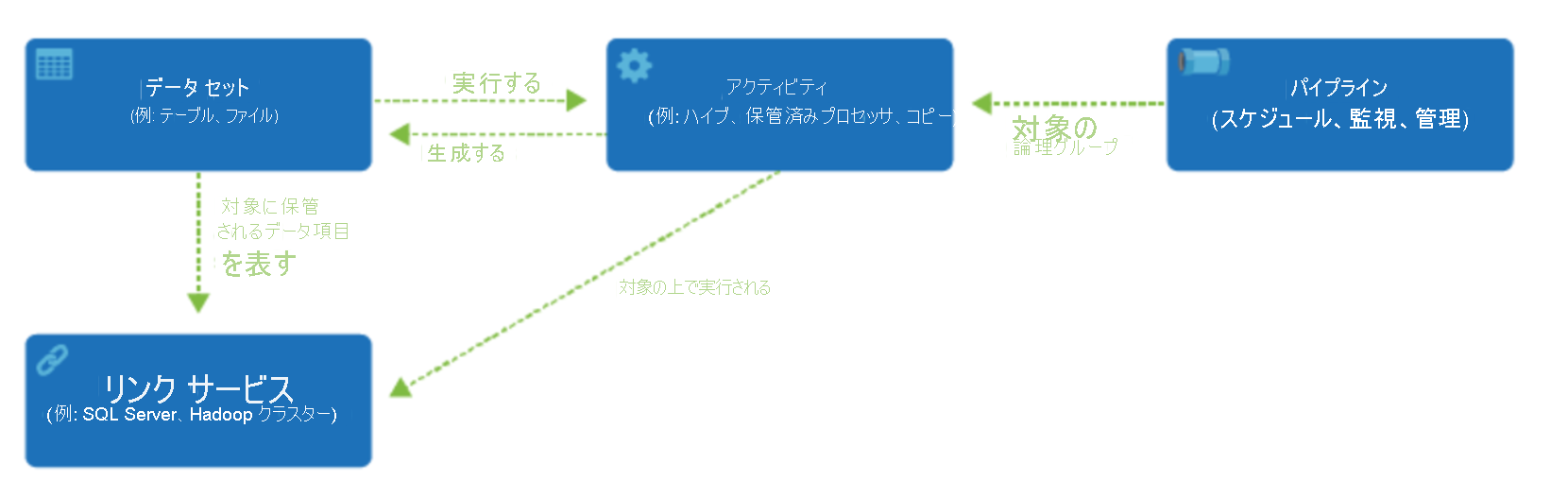
Data Factory は、リンクされたサービスと呼ばれるオブジェクトを作成することによって接続できるさまざまなデータ ソースをサポートしています。これにより、データ ソースからデータを取り込み、変換や分析用のデータを作成する準備を整えることができます。 また、リンクされたサービスは、必要に応じてコンピューティング サービスを起動できます。 たとえば、Hive クエリを使用してデータを処理することだけを目的として、オンデマンドの HDInsight クラスターを開始する必要がある場合があります。 そのため、リンクされたサービスを使用すると、データ ソース、またはデータの取り込みと準備に必要なコンピューティング リソースを定義できます。
リンクされたサービスを定義すると、 データセット オブジェクトの作成を通じて使用するデータセットが Azure Data Factory に認識されます。 データセットは、リンクされたサービス オブジェクトによって参照されるデータ ストア内のデータ構造を表します。 データセットは、アクティビティと呼ばれる ADF オブジェクトでも使用できます。
アクティビティ には通常、Azure Data Factory の作業の変換ロジックまたは分析コマンドが含まれています。 アクティビティには、さまざまなデータ ソースからデータを取り込むために使用できるコピー アクティビティが含まれています。 また、コードを使用しないデータ変換を実行するためのマッピング データ フローを含めることもできます。 また、データを変換するためのストアド プロシージャ、Hive クエリ、または Pig スクリプトを実行することもできます。 データを機械学習モデルにプッシュして、分析を実行することができます。 SQL ストアド プロシージャを使用してデータを変換した後、Databricks で分析を実行するなど、複数のアクティビティを実行することは珍しくありません。 この場合、複数のアクティビティを、パイプラインと呼ばれるオブジェクトと共に論理的にグループ化し、実行するように "スケジュール" することも、パイプラインの実行をいつ開始するかを決定する "トリガー" を定義することもできます。 さまざまな種類のイベントに合わせて、さまざまな種類のトリガーがあります。
"制御フロー" は、パイプライン アクティビティのオーケストレーションです。これには、シーケンスに従うアクティビティの連鎖、分岐、パイプライン レベルでのパラメーターの定義、オンデマンドかトリガーからパイプラインが呼び出される際の引数の受け渡しが含まれます。 さらに、カスタム状態の受け渡しや、ループ コンテナー、および For-each 反復子も含まれます。
"パラメーター" は、読み取り専用の構成のキーと値のペアです。 パラメーターはパイプラインで定義されます。 定義済みパラメーターの引数は、実行時に、トリガーが作成した実行コンテキストか、手動で実行されるパイプラインから渡されます。 パイプライン内のアクティビティは、パラメーターの値を使用します。
Azure Data Factory には、アクティビティとリンクされたサービス オブジェクト間をブリッジできる "統合ランタイム" があります。 統合ランタイムは、リンクされたサービスによって参照され、アクティビティが実行されたりディスパッチされたりするコンピューティング環境を提供します。 そうすることで、可能な限り近いリージョンでアクティビティを実行できるようになります。 統合ランタイムには、Azure、自己ホスト型、および Azure SSIS の 3 種類があります。
すべての作業が完了したら、Data Factory を使用して、最終的なデータセットを、Power BI や Machine Learning などのテクノロジで使用できる別のリンク サービスに発行することができます。