データ ファクトリ プロセスについて説明する
データドリブン ワークフロー
通常、Azure Data Factory のパイプライン (データドリブン ワークフロー) では次の 4 つのステップが実行されます。
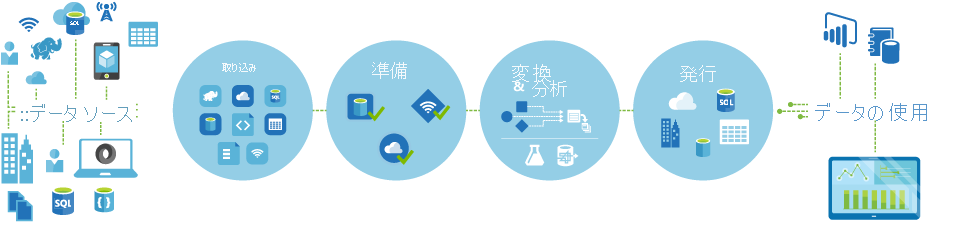
接続と収集
オーケストレーション システムを構築するための最初の手順は、データベース、ファイル共有、FTP Web サービスなど、必要なすべてのデータ ソースを定義して接続することです。 次の手順は、必要に応じて、以降の処理のために、一元化された場所にデータを取り込むことです。
変換と強化
Databricks や Machine Learning などのコンピューティング サービスを使用すると、メンテナンス可能で管理されたスケジュールで変換されたデータを準備または生成し、クレンジングされ、変換されたデータを運用環境に提供することができます。 場合によっては、分析を支援するためにデータを追加してソース データを補強したり、正規化プロセスによってソース データを統合したりして、たとえば Machine Learning 実験で使用することができます。
発行
変換と強化のフェーズで生データがビジネス用途に適した形式へ洗練された後、Azure Data Warehouse、Azure SQL Database、Azure Cosmos DB、またはビジネス ユーザーがビジネス インテリジェンス ツールから指定できる分析エンジンへと、データを読み込むことができます。
モニター
Azure Data Factory には、Azure Monitor、API、PowerShell、Azure Monitor ログ、および Azure portal の正常性パネルを介したパイプライン監視のサポートが組み込まれており、スケジュールされたアクティビティとパイプラインの成功率と失敗率を監視することができます。