演習 - HDInsight Spark クラスターでクエリを実行する
この演習では、csv ファイルからデータフレームを作成する方法と、Azure HDInsight で Apache Spark クラスターに対して対話型の Spark SQL クエリを実行する方法を説明します。 Spark のデータフレームは、名前付きの列に編成された、データの分散型コレクションです。 データフレームは概念的には、リレーショナル データベースのテーブルまたは R/Python のデータ フレームと同等です。
このチュートリアルでは、次の作業を行う方法について説明します。
- csv ファイルからデータフレームを作成する
- データフレームでクエリを実行する
csv ファイルからデータフレームを作成する
次のサンプル csv ファイルは、ある建物の温度情報が含まれており、Spark クラスターのファイル システムに格納されています。
次のコードを Jupyter Notebook の空のセルに貼り付け、Shift + Enter キーを押してコードを実行します。 このコードにより、このシナリオに必要な種類がインポートされます。
from pyspark.sql import * from pyspark.sql. types import *Jupyter で対話型のクエリを実行すると、Web ブラウザー ウィンドウまたはタブのキャプションに [(ビジー)] 状態とノートブックのタイトルが表示されます。 また、右上隅にある PySpark というテキストの横に黒丸も表示されます。 ジョブが完了すると、白丸に変化します。
次のコードを実行して、データフレームと一時テーブル (hvac) を作成します。
# Create a dataframe and table from sample data csvFile = spark.read.csv ('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv', header=True, inferSchema=True) csvFile.write. saveAsTable("hvac")
データフレームでクエリを実行する
テーブルを作成したら、データに対して対話型のクエリを実行できます。
Notebook の空のセルで次のコードを実行します。
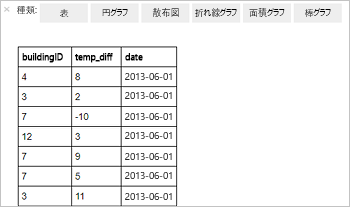
%%sql SELECT buildingID, (targettemp - actualtemp) AS temp_diff, date FROM hvac WHERE date = \"6/1/13\"次の表形式の出力が表示されます。
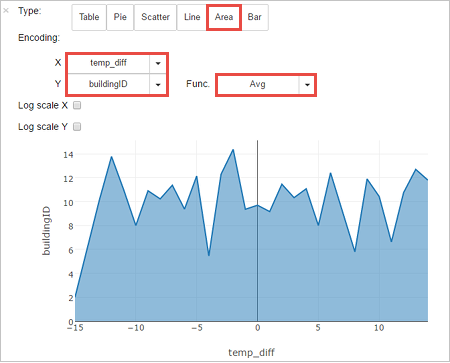
他の視覚化で結果を表示することもできます。 同じ出力に対して面積グラフを表示するには、[Area](面積) を選択し、他の値を次のように設定します。
ノートブックのメニュー バーから [File](ファイル) > [Save and Checkpoint](保存とチェックポイント) に移動します。
ノートブックのメニュー バーから [File](ファイル) > [Close and Halt](閉じて停止) に移動し、ノートブックをシャットダウンしてクラスター リソースを解放します。