HDInsight Spark クラスターで Jupyter Notebook を開く
HDInsight Spark クラスターを作成したら、Azure HDInsight の Apache Spark クラスターに対して対話型の Spark SQL クエリまたはジョブを実行できます。 これを行うには、最初にノートブックを作成する必要があります。 ノートブックは、データ エンジニアやデータ サイエンティストがさまざまな言語を使用してデータを操作できるようにする対話型のエディターです。 これには、Python、SQL、Scala などの言語を含めることができます。 HDInsight では、データを操作できる Jupyter、Zeppelin、Livy をサポートしています。 操作のレベルは、管理しているワークロードによって異なります。
HDInsight の Apache Spark では、次のワークロードをサポートしています。
対話型のデータ分析と BI
ノートブックを使用して、非構造化/半構造化データを取り込み、ノートブック内にスキーマを定義することができます。 次に、ビジネス ユーザーがノートブック内のデータに対してデータ分析を実行できるように、Power BI などのツールで、スキーマを使用してモデルを作成できます。
Spark の機械学習
ノートブックを使用して、MLlib (Spark 上に構築された機械学習ライブラリ) を操作し、機械学習アプリケーションを作成することができます。
Spark のストリーミングおよびリアルタイム データ分析
HDInsight の Spark クラスターには、リアルタイム分析ソリューションを構築するための豊富なサポートが用意されています。 Spark には、Kafka、Flume、X、ZeroMQ、TCP ソケットなど、多数のソースからデータを取り込むためのコネクタが既にありますが、HDInsight の Spark では、Azure Event Hubs からデータを取り込むためのファーストクラスのサポートが追加されます。
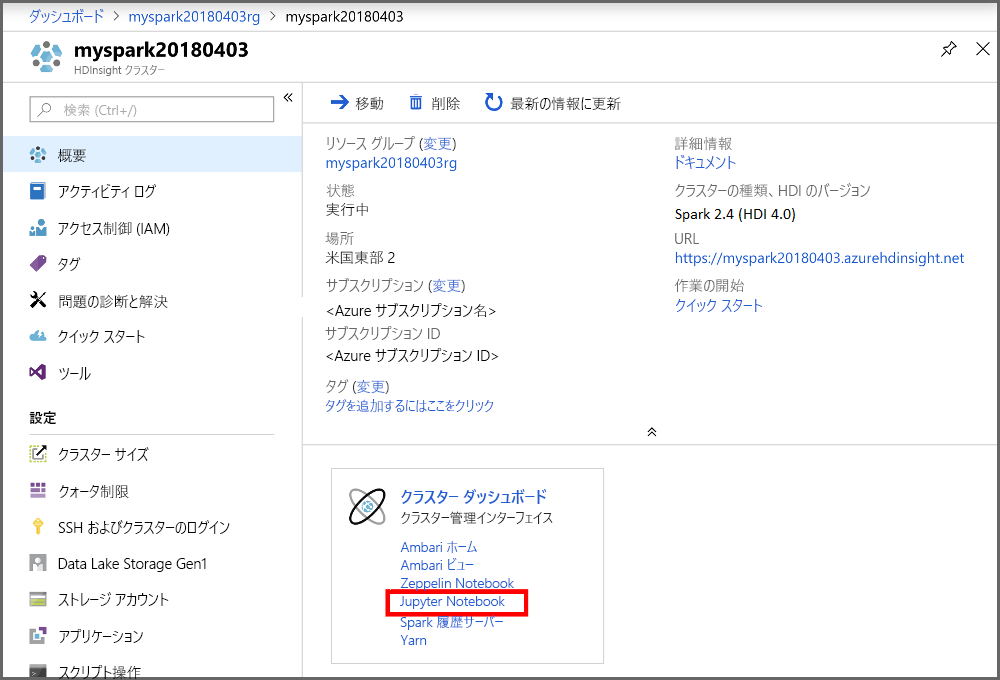
Jupyter Notebook の作成
次の手順を使用して、Azure portal で Jupyter Notebook を作成します。
ポータルの [クラスター ダッシュボード] セクションで、[Jupyter Notebook] を選択します。 入力を求められたら、クラスターに対してクラスターのログイン資格情報を入力します。
[新規] > [PySpark] を選択して、ノートブックを作成します。

Untitled (Untitled.pynb) という名前の新しいノートブックが作成されて開かれ、ジョブの作成とクエリの実行を開始できます。