ポーリング トリガー
ポーリング トリガーは、REST API サービスを定期的に呼び出して新しいデータを確認する実装です。 プラットフォームで新しいデータがあることが確認されると、トリガーが起動され、収集した新しいデータがクラウド フローまたは Logic Apps ワークフローに渡されます。
次の図は、ポーリング トリガーが新しいデータを取得する基本的なプロセス フローを示しています。

ポーリング トリガーは、データを取得して状態を設定することで開始されます。 その後、前回の状態の更新からのすべてのデータを要求して、定期的に更新を確認します。 新しいデータを取得すると、新しい状態が設定され、プロセスが継続されます。 API は、パラメーターの値に基づいて、データの増分を返すことができる必要があります。 状態は Power Automate または Azure Logic Apps によって管理されるため、API には特別な状態の管理の要件はありません。
Webhook トリガーとは異なり、ポーリング トリガーには設定や停止の要件はなく、いつでも処理を停止できます。 要件がシンプルなことが、ポーリング トリガーの主な利点の 1 つです。
API の要件
ポーリング トリガーで API に必要とされるのは、クエリ文字列パラメーターを使用してデータをフィルター処理できるデータ取得方法があることのみです。 また、返されたデータからパラメーターの次の値を抽出する方法がある必要があります。 この実装は、専用または既存のアクション メソッドで行うことができます。
たとえば、注文番号が増え続けるオンライン店舗での実装を考えてみましょう。 この店舗の API には、店舗で作成された注文を返す ListOrders というメソッドがあります。
ListOrders は、注文番号を降順で並べ替えて注文を返します。 そのため、最も大きい注文番号はリストの最初の注文のものになります。
ListOrders はクエリ文字列パラメーターを受け取り、注文番号がパラメーターの値よりも大きい注文を取得します。
これらの 2 つの性質により、このアクションをポーリング トリガーとして使用できます。 プラットフォームは、返されたデータから最も大きい注文番号を抽出し、次の要求にパラメーターとして渡します。 実質的に、このメソッドは最後の注文より後に作成されたすべての注文を選択することになります。
実装
ポーリング トリガーは、Power Automate のウィザードを使用して作成します。 このプロセスには、以下のステップが含まれます。
データの取得に使用する HTTP 要求を定義します。
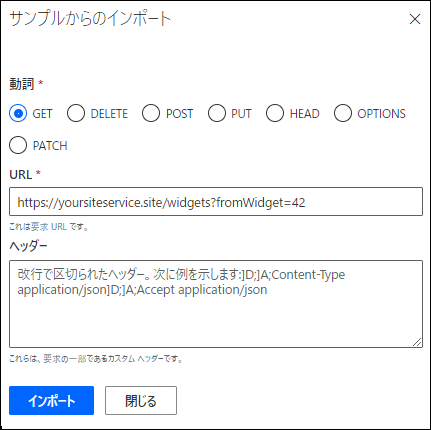
要求のクエリ文字列には、fromWidget パラメーターを含めます。これにより、パラメーターの定義をあらかじめ作成できます。 このパラメーターによって、返されるデータは増分になり、パラメーターで指定したウィジェットより後に作成されたすべてのウィジェットが返されます。
パラメーターの表示を内部に変更します。これにより、ユーザーがこのパラメーターを変更できなくなり、コネクタの内部でのみ使用されます。
サービスから返されるデータを定義します。 このデータには、連続した要求で fromWidget の値として使用するプロパティを含める必要があります。
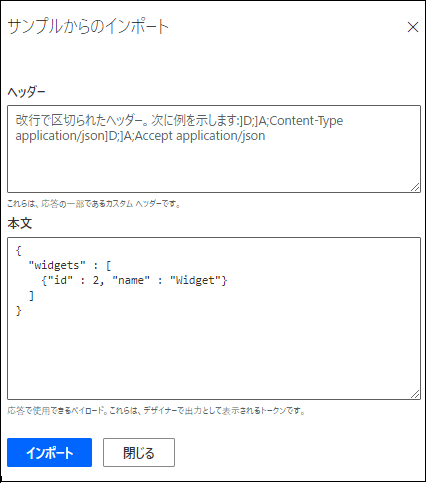
この例では、プロパティは ID です。
トリガーの設定を行います。 クエリ パラメーターを選択し、値を返す値または式を定義して、トリガーのデータを含むコレクションを選択します。
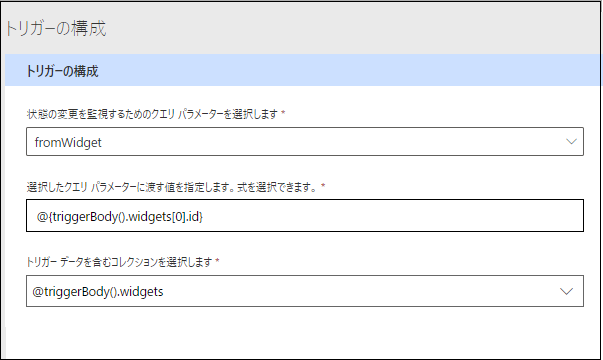
この例には、以下のパラメーターが含まれています。
ラボの結果から抽出された値を受け取るクエリ パラメーターとして、fromWidget が選択されています。
@{triggerBody().widgets[0].id} 式は、その時点で最も大きいウィジェット ID を抽出します。 返されるコレクションは ID の値の降順で並べ替えられるため、最初の要素から値を抽出することによって、その時点で最も大きい ID であることを保証できます。
@triggerBody().widgets 式は、データ コレクションを定義します。



パラメーターを抽出および処理する必要があります。この変換は、コネクタのポリシーを使用してのみ実装できます。 そのため、ポーリング トリガーの設定は OpenAPI コネクタ定義とは別のポリシー テンプレートとして保存します。 つまり、ポーリング トリガーの設定はすべて、Swagger エディターでは手動で編集できません。
注意する必要がある制限は、トリガーの本文は配列にできないという点です。 たとえば、次のデータを返す ListOrders というメソッドについて考えてみましょう。
[
{"value" : 42.00, "id" : "2", ... },
{"value" : 10.00, "id" : "1", ... }
]
このトリガーの本文は処理されません。このトリガーでは、実行時に Power Automate フローまたは Logic Apps ワークフローでエラーが発生します。
代わりに、メソッドは次の例のようにレコードの配列を含むプロパティを返す必要があります。
{
"orders": [
{ "value" : 42.00, "id" : "2", ... },
{ "value" : 10.00, "id" : "1", ... }
]
}
このデータ構造は、ポーリング トリガーの実装の一部として使用することができます。
バッチ処理
Webhook トリガーと同様に、ポーリング トリガーは OpenAPI の x-ms-trigger の拡張によって定義されます。 ポーリング トリガーで定義される値は batch です。これは、Webhook の応答と同様に、メソッドが個々のオブジェクトではなく配列を返すことを意味します。
/trigger/ListInvoices:
post:
x-ms-trigger: batch
この処理は、サービスの 1 回の呼び出しで複数のレコードを返すことができるために発生します。 Power Automate または Logic Apps でポーリング トリガーを使用する場合は、トリガーの分割設定を使用して処理モードを設定できます。

受け取った配列を複数の並列処理に分割する実装は、パフォーマンス上の理由で行います。 このシナリオのクラウド フローの各インスタンスは、1 つのオブジェクトを受け取ります。 分割オプションを設定しない場合、クラウド フローの 1 つのインスタンスは 1 つの配列の値を受け取ります。
ポーリング トリガーは、Webhook トリガーよりも簡単に定義できます。ただし、Webhook トリガーほど詳細ではなく、パフォーマンスも若干劣ります。 1 種類のトリガーを作成して使用するか、別の種類のトリガーも作成して使用するかは、サービス API の特徴、構造、機能によって判断します。