テキスト読み上げ API を使用する
その Speech to text API と同様に、Azure AI 音声サービスには、音声合成用の他の REST API が用意されています。
- テキスト読み上げ API。音声認識を実行する主要な方法です。
- Batch synthesis API。大量のテキストをオーディオに変換するバッチ操作をサポートするように設計されています。たとえば、ソース テキストからオーディオブックを生成することができます。
これらの REST API について詳しくは、Text to Speech REST API に関するドキュメントをご確認ください。 実際には、インタラクティブな音声対応アプリケーションのほとんどは、(プログラミング) 言語固有の SDK を介して Azure AI 音声サービスを使用します。
Azure AI 音声 SDK の使用
音声認識と同様に、実際には、ほとんどのインタラクティブな音声対応アプリケーションは Azure AI 音声 SDK を使用して構築します。
音声合成を実装するパターンは、音声認識のパターンに似ています。
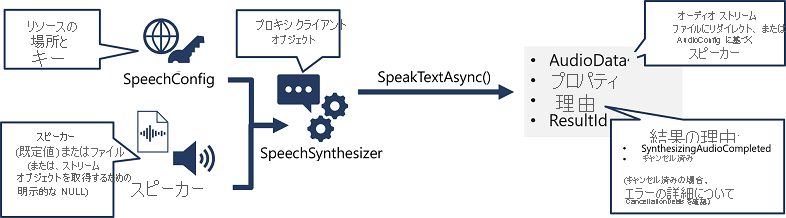
- SpeechConfig オブジェクトを使用して、Azure AI 音声リソースへの接続に必要な情報をカプセル化します。 具体的には、その "場所" と "キー" です。
- 必要に応じて、AudioConfig を使用して、合成する音声の出力デバイスを定義します。 既定では、これは既定のシステム スピーカーですが、オーディオ ファイルを指定するか、この値を明示的に null 値に設定して、直接返されるオーディオ ストリーム オブジェクトを処理することもできます。
- SpeechConfig と AudioConfig を使用して、SpeechSynthesizer オブジェクトを作成します。 このオブジェクトは、テキスト読み上げ API のプロキシ クライアントです。
- SpeechSynthesizer オブジェクトのメソッドを使用して、基になる API 関数を呼び出します。 たとえば、SpeakTextAsync() メソッドは、Azure AI 音声サービスを使用してテキストを音声に変換します。
- Azure AI 音声サービスからの応答を処理します。
SpeakTextAsync メソッドの場合、結果は次のプロパティを含む SpeechSynthesisResult オブジェクトになります。
- AudioData
- プロパティ
- 理由
- ResultId
音声が正常に合成されると、Reason プロパティが SynthesizingAudioCompleted 列挙型に設定され、AudioData プロパティにオーディオ ストリームが格納されます (AudioConfig によっては、自動的にスピーカーまたはファイルに送信されている場合もあります)。