Azure Data Factory での変換の種類について説明する
マッピング データ フローには、データを変更するためのさまざまな変換の種類が用意されています。 それらは次のカテゴリに分類されます。
| カテゴリ名 | 説明 |
|---|---|
| スキーマ修飾子変換 | これらの種類の変換では、変換のアクションに基づいて新しい列を作成することによって、シンクのターゲットを変更します。 たとえば、派生列変換では、既存の列に対して実行される操作に基づいて、新しい列が作成されます。 |
| 行修飾子変換 | これらの種類の変換は、変換先での行の表示方法に影響します。 たとえば、並べ替え変換では、データが並べ替えられます。 |
| 複数入力、出力変換 | これらの種類の変換では、新しいデータ パイプラインを生成するか、複数のパイプラインを 1 つにマージします。 たとえば、結合変換では、複数のデータ ストリームが結合されます。 |
以下は、マッピング データ フローで使用可能な変換の一覧です
| 名前 | カテゴリ | 説明 |
|---|---|---|
| 集計 | スキーマ修飾子 | 既存の列または計算列によってグループ化される、SUM、MIN、MAX、COUNT などのさまざまな種類の集計を定義できます。 |
| 行の変更 | 行の修飾子 | 行に対して、挿入、削除、更新および upsert の各ポリシーを設定します。 一対多の条件を式として追加できます。 各行は一致する最初の式に対応したポリシーでマークされるので、これらの条件は優先度の順に指定する必要があります。 これらの条件によってそれぞれ、行が挿入、更新、削除、アップサートされます。 行の変更では、ご利用のデータベースに対して DDL と DML の両方を生成できます。 |
| 条件分割 | 複数の入力/出力 | 一致条件に基づいて、データの行を異なるストリームにルートします。 |
| 派生列 | スキーマ修飾子 | データ フローの言語を使用して、新しい列を生成するか、既存のフィールドを変更します。 |
| Exists | 複数の入力/出力 | お使いのデータが別のソースまたはストリームに存在するかどうかを確認します。 |
| Assert | 行の修飾子 | 条件に基づいて、行をフィルターします。 |
| フラット化 | スキーマ修飾子 | JSON などの階層構造体の中で配列値を取得し、それらを個々の行に展開します。 |
| Join | 複数の入力/出力 | 2 つのソースまたはストリームのデータを結合します。 |
| Lookup | 複数の入力/出力 | もう一方のソースのデータを参照できるようにします。 |
| 新しいブランチ | 複数の入力/出力 | 同じデータ ストリームに対して複数の操作と変換を行います。 |
| ピボット | スキーマ修飾子 | 1 つまたは複数のグループ化列に、個別の列に変換された個々の行の値がある集計。 |
| Select | スキーマ修飾子 | 列とストリームの名前をエイリアス化し、列を削除するか、並べ替えます。 |
| Sink | - | データの最終受信先。 |
| Sort | 行の修飾子 | 現在のデータ ストリームの受信行を並べ替えます。 |
| ソース | - | データ フローのデータ ソース。 |
| 代理キー | スキーマ修飾子 | インクリメントする非ビジネスの任意のキー値を追加します。 |
| Union (結合) | 複数の入力/出力 | 複数のデータ ストリームを垂直方向に結合します。 |
| ピボット解除 | スキーマ修飾子 | 列を行の値にピボットします。 |
| ウィンドウ | スキーマ修飾子 | データ ストリーム内の列のウィンドウベースの集計を定義します。 |
データ フローの式ビルダー
定義できる変換の一部では、データ フローの式ビルダーを使用できます。式ビルダーでは、データ フローの列、フィールド、変数、パラメーター、関数をそれらのボックスで使用して、変換の機能をカスタマイズできます。
式を作成するには、式ビルダーを使用します。式ビルダーは、変換内の式テキスト ボックスをクリックすると起動します。 変換の列を選択したときに、[計算列] のオプションが表示されることもあります。 このオプションをクリックすると、起動した式ビルダーも表示されます。
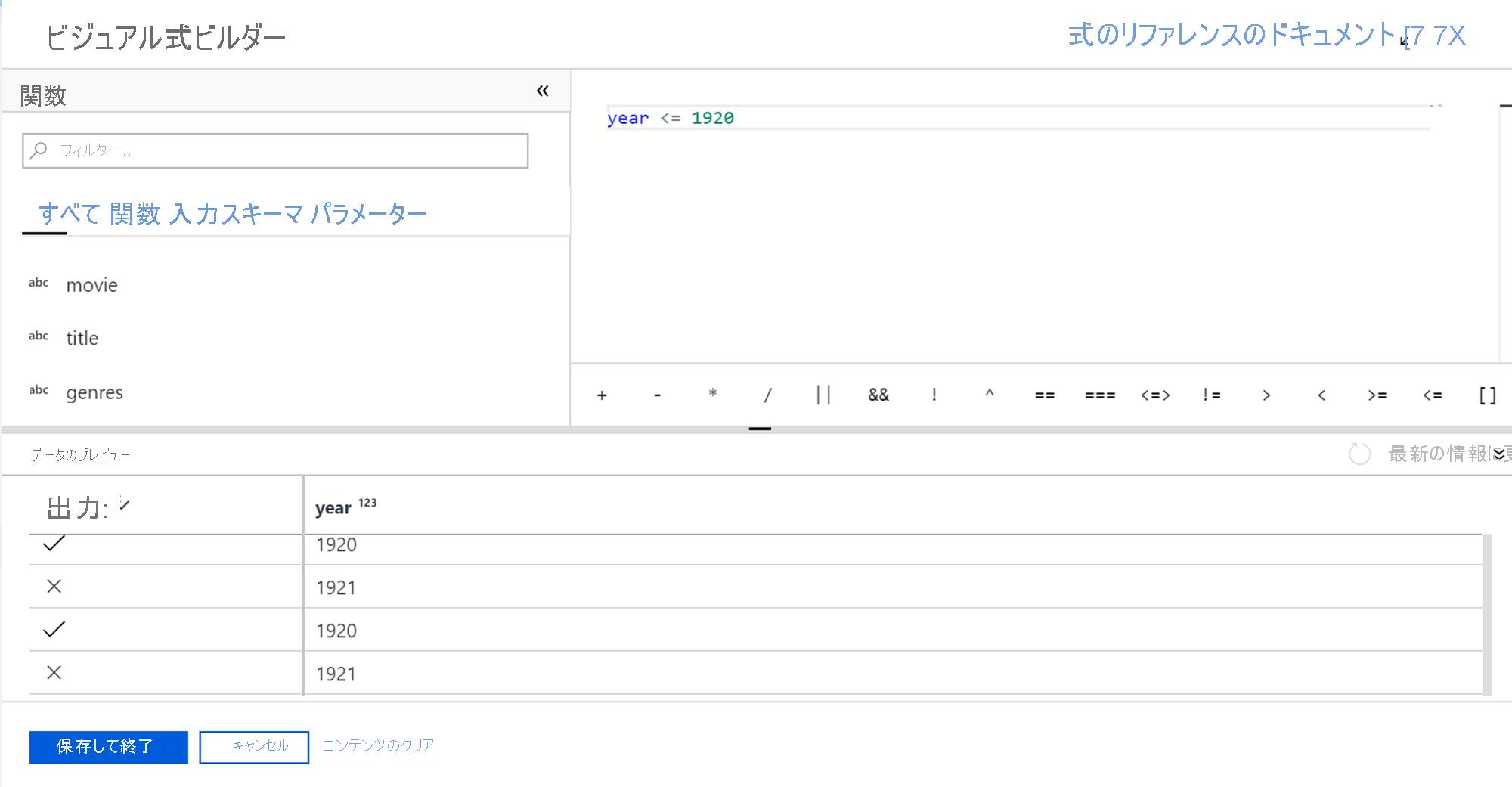
式ビルダー ツールでは、テキスト エディター オプションが既定で設定されています。 オートコンプリート機能では、Azure Data Factory Data Flow オブジェクト モデル全体から読み取り、構文チェックと強調表示を行います。