回復性に関する設計とポリシー
"ディザスター リカバリー" は "ビジネス継続性" であると共に、最もよく聞かれるフレーズがあります。継続性には肯定的な意味合いがあります。 これは、障害イベントの範囲を、データ センターの壁内に限定する (実際には範囲をより狭くする) という理想を証明するものです。
しかし、"継続性" はエンジニアリング用語ではありません (その努力にもかかわらず)。 ビジネス継続性には 1 つの式、方法、レシピはありません。 組織によっては、運営するビジネスの種類と方法に関連する、ベスト プラクティスの一意のセットが存在する場合があります。 継続性とは、これらのプラクティスを正しく適用して良い結果を得ることです。
回復性の意味
エンジニアは、"回復性" の概念を理解しています。 システムがさまざまな状況で適切に動作する場合、回復性があると言われます。 フェールセーフ、セキュリティ対策、障害手順が実装されており、直面する可能性のある悪影響に対応する準備ができている場合に、リスク マネージャーはビジネスが十分に準備されているものと判断します。 エンジニアは、システムの動作環境を、白か黒かの観点で "通常" と "危険"、"安全" と "障害" などと認識しない可能性があります。この担当者は、ビジネスをサポートするシステムを、逆境に直面したときに継続的かつ予測可能なサービス レベルが提供される場合に、適切に稼働していると認識します。
2011 年に、クラウド コンピューティングがデータ センターにおいて上昇傾向になった場合と同じように、欧州ネットワーク情報セキュリティ機関 (ENISA。欧州連合の機関の 1 つ) ではレポートを発行しました。これは、E.U. 政府による、情報収集に使用されたシステムの回復性に関する分析情報の要求に応じたものです。 このレポートには、"回復性" の実際の意味、あるいはその測定方法について、ICT スタッフ間で合意がまだ得られていないことは明白であると示されました (ヨーロッパでは、"ICT" は、通信を含む、"IT" を表す用語です)。
これにより、ENISA では、カンザス大学 (KU) の James P. G. Sterbenz 教授が率いる研究者チームによってプロジェクトが立ち上げられたことを認識しました。これは、米国防総省での展開を目的としたものです。 これは、Resilient and Survivable Networking Initiative (ResiliNets)1 と呼ばれるもので、さまざまな状況において、情報システムの回復性の変動状態を視覚化するための方法です。 ResiliNets は、組織における回復性ポリシーの合意モデル用のプロトタイプです。
KU モデルでは、多くの使い慣れた簡単に説明できるメトリックが利用されますが、その一部はこの章で既に紹介されています。 これには次のようなものがあります。
フォールト トレランス - 前述のとおり、障害が発生した場合に予測されるサービス レベルを維持するためのシステムの能力
中断トレランス - システム自体が原因ではない、予想不可能で、多くの場合、極端な動作状況 (停電、インターネット帯域幅不足、トラフィックの急増など) に直面した場合に、予測されるサービス レベルを維持するための同じシステムの能力
サバイバビリティ - 自然災害を含む考えられるすべての状況において、(必ずしも公称であるとは限らない場合) 適切なサービス パフォーマンス レベルを提供するシステムの能力の推定値
ResiliNets で提唱される重要な理論は、システム エンジニアリングと人間の試みを組み合わせることによって、情報システムの回復性が定量的に高められるというものです。 さらに重要なことは、人々の行動です。つまり、日常的なプラクティスとして "継続して" 行う内容により、システムがより強力なものになります。
活発な戦域において、陸軍兵、海軍兵、海兵隊員が戦術的配備の原理を学習して記憶する方法をヒントに、KU チームでは、ResiliNets プラクティスのライフサイクルを記憶するために、次のような簡単なニーモニックを提案しました: D2R2 + DR。 図 9 に示すように、変数は、この順序の以下の略です:**
通常の動作に対する脅威からシステムを防御する
考えられる障害と外部の状況による、悪影響の発生を検出する
影響がまだ持続していない場合でも、これらの効果がシステムに与える可能性がある以降の影響を修復する
通常のサービス レベルに回復させる
イベントの根本原因を診断する
より適切に再発に備えるために、必要に応じて今後の動作を調整する
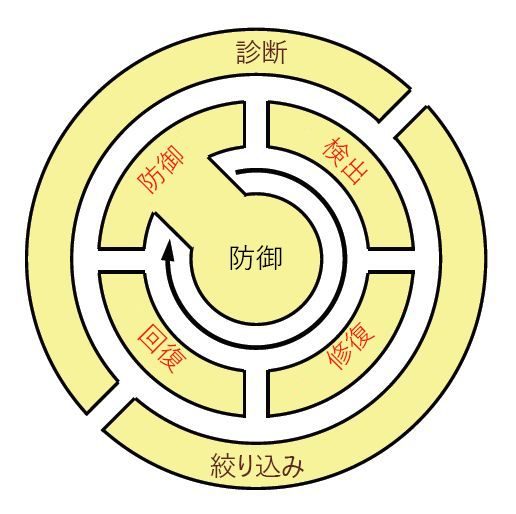
図 9: ResiliNets を利用する環境におけるベストプラクティス アクティビティのライフサイクル。
これらの各ステージでは、特定のパフォーマンスおよび動作メトリックが、人々とシステムの両方について取得されます。 これらのメトリックを組み合わせると、図 9.10 に示すように、ユークリッド ジオメトリック平面を使用してグラフにプロットできるポイントが生成されます。 各メトリックは 2 つの 1 次元値に減らすことができます。1 つはサービスレベル パラメーター P を反映し、もう 1 つは動作状態 N を表します。ResiliNets サイクルの 6 つのステージがすべて実装され、繰り返されるため、サービス状態 S は、グラフの座標 (N、P) でプロットされます。
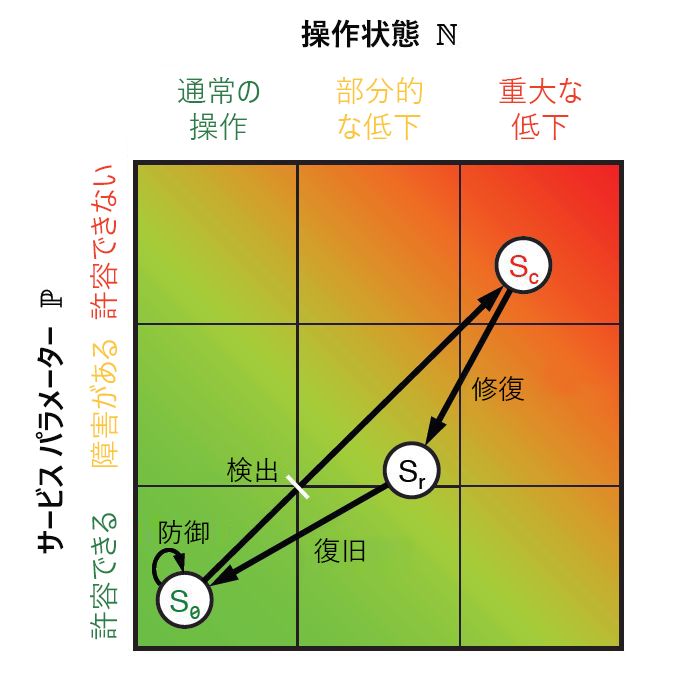
図 10: ResiliNets の状態領域と戦略の内部ループ。
サービスの目標を達成しようとしている組織では、S の状態をグラフの左下隅に緊密に近づけます。"内部ループ" と呼ばれる期間中は、できれば、そこに、またはその近くに留まるようにします。 サービス目標が下がると、状態は望ましくないベクトルで右上に移動します。
ResiliNets モデルは、企業における IT の回復性を普遍的に表現するものではありませんが、特に公的機関における一部の主要な組織によって採用されたことで、クラウド革命のきっかけとなったいくつかの変化を引き起こしました。
パフォーマンスの視覚化。 回復性は、直接の利害関係者に伝達される現在の状態に対する理念である必要はありません。 実際には、1 語未満の単語を使用してデモンストレーションすることができます。 クラウドからメトリックを取り込む最新のパフォーマンス管理プラットフォームには、効率的に論証するダッシュボードおよび同様のツールが組み込まれています。
復旧の手段と手順は、災害が発生するまで待つ必要はない。 綿密で適切に設計された情報システムでは、警戒を怠らないエンジニアやオペレーターが常時配置されており、危機発生時の修復手順とほとんど変わらないメンテナンス手順が日常的に実施されています。 たとえば、ホット スタンバイ方式のディザスター リカバリー環境では、実際、サービス レベル問題の修復が自動化されており、メイン ルーターは、影響を受けたコンポーネントからトラフィックを転送するだけです。 言い換えれば、障害への備えは、障害が発生するまで待つ必要はありません。
情報システムは、人で構成されている。 自動化によって、人の作業効率が向上し、製品はより効率的に生産されます。 しかし、予想できない状況や環境の変化に対応できるように設計されたシステムで人に代わるものではありません。
復旧指向コンピューティング
ResiliNets は、世紀が改まった直後に Microsoft が構築を支援した、"復旧指向コンピューティング" (ROC)2 と呼ばれる概念の 1 つの実装です。この基本原則は、障害やバグはコンピューティング環境の永遠の真実であるということでした。 この環境の駆除に途方もない時間を費やすよりもむしろ、常識的な対策を適用して環境の予防接種に役立てた方が組織にとって有益かもしれません。 これは、人は 1 日に何回も手を洗う必要があるという、20 世紀を迎える直前に導入された急進的な概念に相当するコンピューティングです。
パブリック クラウドでの回復性
パブリック クラウド サービス プロバイダーはすべて、回復性の原則とフレームワークに準拠しています。回復性という名前で呼ばないことを選択した場合でも同じです。 ただし、クラウド プラットフォームでは、組織の情報資産全体がクラウドに吸収されない限り、組織のデータ センターの回復性が強化されません。 ハイブリッド クラウド実装は、最も熱心ではない管理者と同等の回復力しかありません。 CSP の管理者が回復性の原則への準拠に熱心である (そうしなければ、SLA の条項に違反する) と想定できれば、システム全体の回復性を維持するのは、常にお客様の仕事である必要があります。
Azure 回復性フレームワーク
"ビジネス継続性戦略" に関する国際標準ガイダンスは、ISO 22301 です。 国際標準化機構 (ISO) の他のフレームワークと同様、これは、ベスト プラクティスと運用に関するガイドラインを規定しており、それに準拠することにより、組織は専門的な認定を受けることができます。
この ISO フレームワークでは、ビジネス継続性について、さらに言えば、回復性についても実際に定義されていません。 代わりに、組織独自の状況における継続性の意味が定義されています。 指針文書には、"組織は、ビジネス影響分析とリスク評価の出力に基づいて、ビジネス継続戦略を特定し、選択しなければならない。 ビジネス継続戦略は、1 つ以上の解決策で構成されるものとする" と記述されています。これらの解決策がどのようなものか、またはどのようなものでなければならないかについては、列挙されていません。3 (セキュリティと回復性 - ビジネス継続性管理システム - 要件)
図 11 は、Microsoft における Azure での ISO 22301 コンプライアンスの複数ステージ実装を示しています。 サービス レベル アグリーメント (SLA) の目標稼働時間も含まれていることにご注意ください。 このレベルの回復性を選択するお客様について、Azure では、ローカルの可用性ゾーン内で仮想データ センターがレプリケートされますが、その後、地理的位置が数百マイル離れている別個のレプリカがプロビジョニングされます。 ただし、法的な理由により (特に、EU のプライバシー法を順守するため)、この地理位置が離れた冗長性は、通常、北米やヨーロッパなどの "データ所在地境界" に制限されます。
![図 11: ISO 22301 に準拠して、アクティブなコンポーネントを複数のレベルで保護する Azure 回復性フレームワーク。[Microsoft 提供]](../../cmu-cloud-admin/cmu-disaster-recovery-backup/media/fig9-11.jpg)
図 11: ISO 22301 に準拠して、アクティブなコンポーネントを複数のレベルで保護する Azure 回復性フレームワーク。 [Microsoft 提供]
ISO 22301 は回復性と関連があり、多くの場合、回復性に関する一連のガイドラインとして説明されますが、Azure がテストされた回復性レベルは、Azure プラットフォームでホストされるお客様の資産ではなく、Azure プラットフォームにのみ適用されます。 資産を Azure クラウドおよびその他の場所にレプリケートする方法など、プロセスの管理、保守、頻繁な改善は、依然としてお客様の責任です。
Google Container Engine
最近まで、ソフトウェアは、機能的にはハードウェアと同一であるが、デジタル形式のマシンの状態として認識されていました。 この観点から見て、ソフトウェアは、情報システムにおいて比較的静的なコンポーネントとして認識されてきました。 セキュリティ プロトコルは、ソフトウェアが定期的に更新されることを義務付けており、この "定期的" とは通常、年に数回、更新プログラムやバグ修正が利用可能になったときを意味します。
クラウド ダイナミクスが実現可能になりましたが、多くの IT エンジニアが予想していなかったのは、ソフトウェアが段階的でありながら頻繁に進化する能力でした。 "継続的インテグレーションと継続的デリバリー" (CI/CD) は、新しく出現した一連の原則で、自動化により、サーバー側とクライアント側の両方で、ソフトウェアに対する増分変更のステージングを頻繁に (多くの場合、毎日) 行うことができます。 スマートフォン ユーザーは、アプリ ストアで週に数回の頻度でアプリが更新されるため、CI/CD を定期的に体験します。 CI/CD によってもたらされる各変更はマイナーである可能性がありますが、マイナー変更が問題なく迅速にデプロイされる可能性があるという事実により、予期しない歓迎すべき副作用があります。つまり、はるかに回復力のある情報システムがもたらされます。
CI/CD デプロイ モデルでは、完全に冗長なサーバー クラスターがプロビジョニングされます。これは、多くの場合、パブリック クラウド インフラストラクチャ上で、新しく生成されたソフトウェア コンポーネントでバグを見つけるためのテストを行い、シミュレーションされた作業環境でそれらのコンポーネントをステージングして潜在的な障害を明らかにする手段としてのみ保持されます。 このようにして、修復が適用され、テストされて、デプロイの承認を得るまで、顧客対応またはユーザー対応のサービスレベルに直接的な影響を与えない安全な環境で修復プロセスを実行することができます。
Google Container Engine (GKE。"K" は "Kubernetes" の略) は、VM ベースのアプリケーションではなく、コンテナーベースのアプリケーションとサービスをデプロイする顧客向けの Google Cloud Platform の環境です。 完全にコンテナー化されたデプロイには、マイクロサービス ("µサービス")、ワークロードとは別個に独立して動作するように設計されたデータベース ("ステートフル データセット")、依存コードラ イブラリ、アプリケーション コードがコンテナー自体のファイル システムを利用する必要がある場合に使用される小さなオペレーティング システムが含まれる場合があります。 図 9.12 は、このようなデプロイを、Google が実際に GKE 顧客に提示するスタイルで示しています。
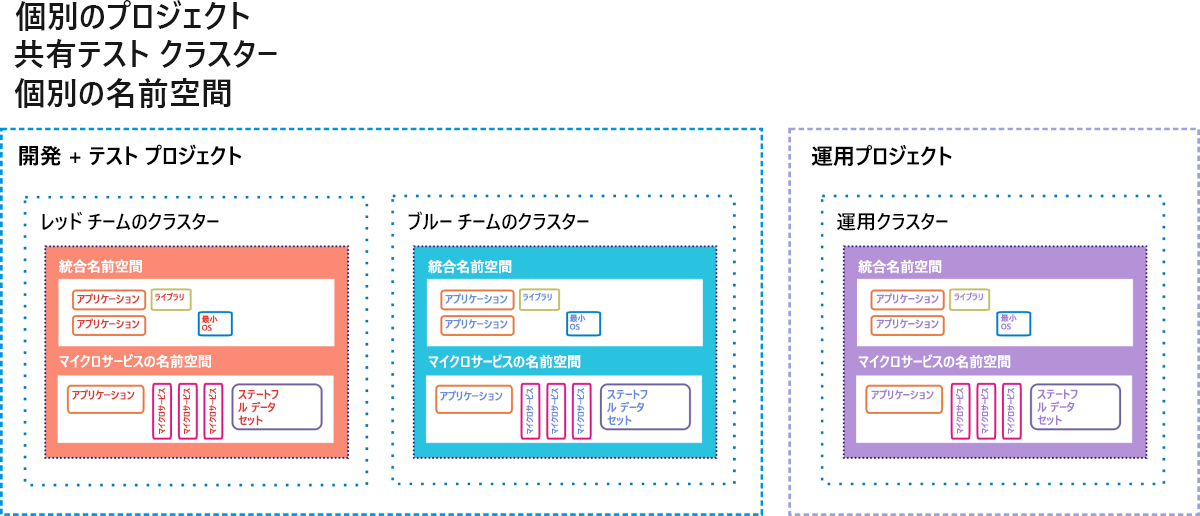
図 12: Google Container Engine の CI/CD ステージング環境としてのホット スタンバイ オプション。
GKE の "プロジェクト" は、データ センターに似ており、データセンターに通常あるすべてのリソースを仮想形式で持っていると見なされています。 プロジェクトには、1 つ以上のサーバー クラスターが割り当てられる可能性があります。 コンテナー化されたコンポーネントは、それ自身の "名前空間" に存在します。これは、コンポーネントのホーム ユニバースのようなものです。 各名前空間は、メンバー コンテナーがアクセスを許可されているすべてのアドレス可能なコンポーネントで構成され、名前空間の外部にあるものにはすべて、リモート IP アドレスを使用してアドレス指定する必要があります。 Google のエンジニアは、古いスタイルのクライアント/サーバー アプリケーション (コンテナー開発者からは "モノリス" と呼ばれています) は、コンテナー化されたアプリケーションと共存できることを示唆しています。ただし、各クラスが自身の名前空間をセキュリティに利用しながら、同じプロジェクトを共有する必要があります。
この提案された配置ダイアグラムには、3 つのアクティブなクラスターがあり、それぞれ 2 つの名前空間を操作しています。1 つは古いソフトウェア用で、もう 1 つは新しいソフトウェア用です。 これらのクラスターのうち 2 つは、テストのために委任されます。1 つは初期開発テスト用で、もう 1 つは最終ステージング用です。 CI/CD の "パイプライン" では、新しいコード コンテナーがいずれかのテスト クラスターに挿入されます。 そこで、コードは、ステージングに転送される前に、一連の自動化されたテストを通過し、バグがないことを証明する必要があります。 2 番目の一連のテストが、新しいソフトウェア コンテナーの到着を待ちます。 エンド ユーザーが使用するライブ運用クラスターに挿入できるのは、2 層のステージング テストを通過したコードのみです。
しかし、そこにもフェールセーフはあります。 A/B デプロイ シナリオでは、指定された時間、新しいコードと古いコードが共存します。 新しいコードが仕様どおりの実行できなかった場合、または新しいコードによってシステムに障害が発生した場合、それを取り消して古いコードを残しておくことができます。 執行猶予期間が過ぎ、新しいコードが適切に機能する場合、古いコードは取り消されます。
このプロセスは、情報システムが障害の原因となるエラーを回避するための半自動化された体系的な方法です。 しかし、運用クラスター自体がホット スタンバイ モードでレプリケートされない限り、それ自体は災害に強い設定ではありません。 このレプリケーション スキームは確実に、クラウドベースのリソースを大量に消費します。 しかし、必要なコストは、組織がシステム停止から無防備な状態のままであるために負担するコストよりもはるかに少ない可能性があります。
関連項目
Sterbenz, James P.G., et al.『ResiliNets: Multilevel Resilient and Survivable Networking Initiative』 (ResiliNets: マルチレベルの回復性と存続可能なネットワーキング イニシアチブ)https://resilinets.org/main_page.html。
Patterson, David, "他"。*Recovery Oriented Computing: Motivation, Definition, Principles, and Examples.* Microsoft Research, March 2002 (復旧指向コンピューティング: 同期機、定義、原則、例)。 https://www.microsoft.com/research/publication/recovery-oriented-computing-motivation-definition-principles-and-examples/。
ISO。 『Security and resilience - Business continuity management systems - Requirements』 (セキュリティと回復性 - ビジネス継続性管理システム - 要件)https://dri.ca/docs/ISO_DIS_22301_(E).pdf。