ディザスター リカバリー サービス
バックアップしたデータの復旧は、当然ですが、バックアップ サービスの標準機能です。 ただし、ディザスターとはデータの損失に限られません。 実際のサーバーと仮想のサーバーを問わず、また、オンプレミスとクラウドベースを問わず、組織のサーバーが故障によって利用できなくなった場合、組織にマイナスの影響が出ます。壊滅的な影響を受けることさえあります。 ディザスターリカバリー (DR) サービスの目的は、データや個々のリソースだけでなく、システム全体にバックアップを提供することです。レプリカがいつでも仕事を引き受けられるように待機しているので、システムが停止したり、オフラインになったりしても、レプリカにトラフィックをリダイレクトすることでサービスを再開できます。
ディザスター リカバリーでパブリック クラウドはその真の目的を証明します。 ただの巨大なテープ ドライブではありません。 クラウド リソースは仮想であるため、レプリカはすぐに起動し、突然なくなったリソースに取って代わることができます。 レプリカは、地域全体の障害から逃れるために正確にミラー化するシステムとは異なる、世界中のさまざまな場所にもホストできます。 物理的情報システムの物理レプリカを維持する (そして、地理的にさまざまな場所で同じことを試みる) 費用とこれを対比してみてください。そのようなシステムを継続的に維持するときのクラウドの価値が明白になります。
主要なクラウド プロバイダーは DRaaS (Disaster-Recovery-as-a-Service/サービスとしてのディザスターリカバリー) を提供していますが、顧客が求めるフェールオーバー サポートを提供するには、そのようなサービスを慎重に計画し、構成する必要があります。 そのため、まず、そのような計画に要素として含める目標やメトリクスについて調べます。
目標とメトリクス
障害イベントが発生すると、組織とその顧客はさまざまな種類のデジタル資産に一斉にアクセスできなくなることがあります。そのようなデジタル資産のうち、最も重要なものには以下があります。
データベースとデータ ストア。顧客と商品またはサービスに関する不可欠な情報をインベントリに記録するだけでなく、組織全体を対象に、ビジネスの取引やプロセスのアクティブな状態を維持します
バルク データ。人が使用するアプリケーションの生成物であるドキュメント、メディア ファイル、保存されるその他のレコードなど
人やビジネス サービスとの通信と接続。このようにして、行われている可能性のある何らかのビジネス アクティビティの内容が構成されます
アプリケーション。顧客、後援者、それ自体の利害関係者向けの組織の Web ネットショップを表すアプリケーション
DR は 1 つのサービスとして顧客に提示されますが、各クラスの復旧プロセスは他とは別になります。 クライアント/サーバーの時代、多くの組織が PC で日常業務を行いました。 PC が故障したとき、バックアップ イメージがその PC のローカル ストレージにあれば、理論的には新しい PC に復旧し、仕事を続行できました。 PC が LAN オペレーティング システムとイーサネット ケーブルによって初めてネットワークに接続されたとき、そのネットワーク内にあるすべての PC をバックアップ イメージから復旧できました。その後、ネットワーク自体を再開できました。
クラウドの場合、しくみが異なります。 組織のアプリケーション用のサーバーとして機能する仮想マシンであっても、その仮想マシンが担う作業のどの部分もそのままカプセル化することはありません。 バックアップ サービスはバルク データにとって安全網になります。そして範囲は限られますが、トランザクション データやデータベースにとっても安全網となります。 ただし、そうしたエンティティはそれぞれ独自のコンポーネントです。そのため、障害発生時のビジネス機能の復旧では、そのような各コンポーネントの機能のすべてではなくても、多くを安全な場所から再確立する必要があります。
したがって、ディザスターリカバリー プロセスでは、組織を完全操業に戻すための手続き間での調整が必要になります。 また、障害自体の存在により、この期間中に行われるビジネスの性質が一層重要になります。 極めて重要なインフラストラクチャを停止させるような災害なら、会社のその他の機能、つまり、倉庫保管、出荷、製造、配達におそらく損害を与えます。 同様に、復旧中のビジネスも、障害イベント前に行われていたビジネスを継ぎ目なく再開することができません。
こうした手続きをひとまとめにするのが、明確に定義された共通のサービスレベル目標の存在です。 AWS、Azure、および Google Cloud を基盤に構築されたサードパーティ サービスの DR サービスには、次の要素が取り入れられています。
目標復旧時点 (RPO) - 復旧されると見なされる、バックアップされる資産をベースとするサービスのために、クライアントに配信する必要のある最小許容データ量。 逆に言えば、この量は許容される最大データ損失量であると見なされます。100 から差し引いたパーセンテージで表されます。
目標復旧時間 (RTO) - 復旧プロセスに許される最大の時間枠。これはまた、組織が耐えられるダウンタイムの尺度であると見なされます。
保持期間 - この最大許容期間を過ぎたら、バックアップ セットを更新し、置き換える必要があります。
RTO と RPO は、互いにバランスを取るものと見なされることがあります。そのため、顧客は復旧時間を長くして、復旧時点の値を上げることがあります。 利用できる帯域幅やダウンタイム リスクのために、復旧時間が顧客にとって問題となる場合、その顧客は RPO 値を高く設定できないかもしれません。
プロフェッショナル リスク アドバイザーや事業継続性アドバイザーは、ディザスター リカバリー ポリシーを作る際に、この 3 つの変数を使用するように力説する場合がよくあります。 ほとんどのビジネス インパクト分析 (BIA) レポートでは、RTO と RPO が最大の関心事です。 この 2 つは、障害イベントから生じた可能性がある損害をアドバイザーが評価するときに非常に重要な変数となります。 サービスレベル目標 (SLO) と呼ばれている集計変数を使用するアドバイザーもいますが、SLO を得るための数式はまだ 1 つも現れていません。 CSP は、リスク アドバイザーが既に認め、正しく理解している用語を使用してサービス レベルを指定できるので、2 つの連携を簡単にします。多くの場合、組織はこのように DR プロバイダーを最終決定します。
手法と手順
前のレッスンでは、関連ファイルのバックアップ、ストレージ ボリューム、仮想マシン イメージなど、情報システム復旧の最も基本的な形態を取り上げました。 これは引き続き DR サービス オプションとして提示されますが、実際のところ、これに当てはまる組織がますます少なくなっています。その理由は主に、RTO 目標が適切に維持できないことにあります。
プロフェッショナル DR サービスからは、展開と管理のためのさまざまな手法が提供されています。そのうちの一部には、障害イベント前のサービス メンテナンスが含まれます。 そうした手法を以下でまとめています。 3 つすべては前のレッスンで説明したさまざまなバックアップ オプションに基づいており、あらゆるサービス プロバイダーに等しく該当します。 いずれかの復旧モードを有効にすることを希望する顧客は、そのモードに最適なレプリケーション クラス、位置情報クラス、ストレージ クラスを選択することになります。
パイロット ライト
この手法 (図 5) では、完全なスタンバイ データ センターのための場所が用意されます。 特定の中心的なサービスとアプリケーションがそれを支えるデータと共にフェールオーバー クラスターで維持されます。このフェールオーバー クラスターは、障害イベントが発生した瞬間、多くの場合は自動的に "点灯" します。 その間、呼び出された場合にアクティブな状態を維持する目的で必要な基本機能だけを備えた仮想サーバーが配備されます。 このような機能を減らしたサーバーには電子メールと Web 機能を与え、顧客との通信や組織内での通信を可能にすることがあります。 パイロット ライトという復旧モードを有効にするには、トランザクション データベースや電子メール ボリュームなど、揮発性データ ストアを連続的に同期しなければならないことがあります。
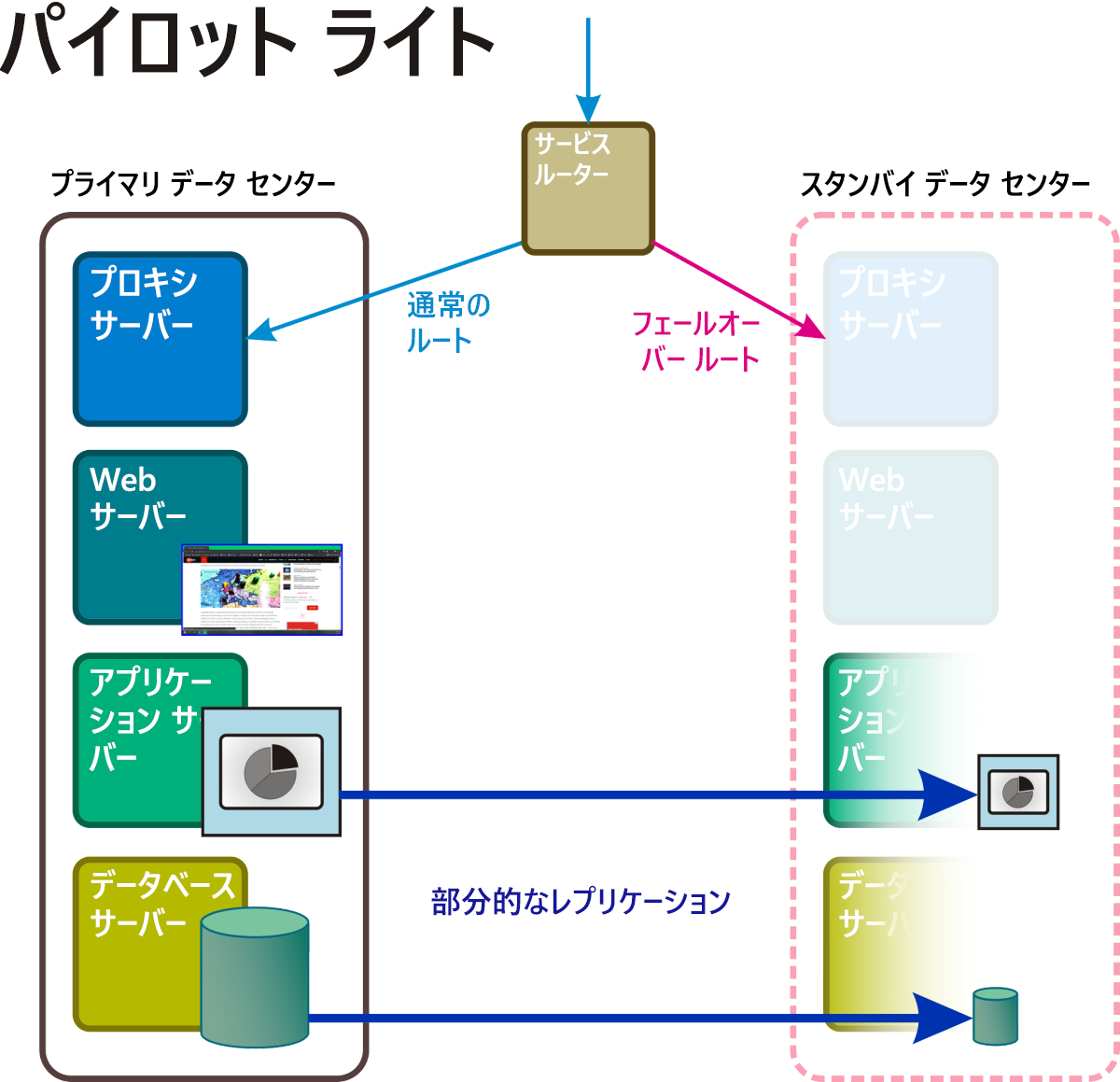
図 5: パイロット ライト復旧シナリオのアクティブ コンポーネントとパッシブ コンポーネント。
ウォーム スタンバイ
図 6 に示すこの回復モードでは、すべてのシステム サービスおよびアプリケーションとすべての重要なビジネス データの継続的に実行されるレプリカが少なくとも 1 つの個別の位置情報で維持されます。 アクティブなネットワークのアドレスをバイパス ルート上のものに置き換える規則が障害イベントによってトリガーされるまで、この完全なレプリカへのアクセスはアクティブなルーターによってバイパスされます。
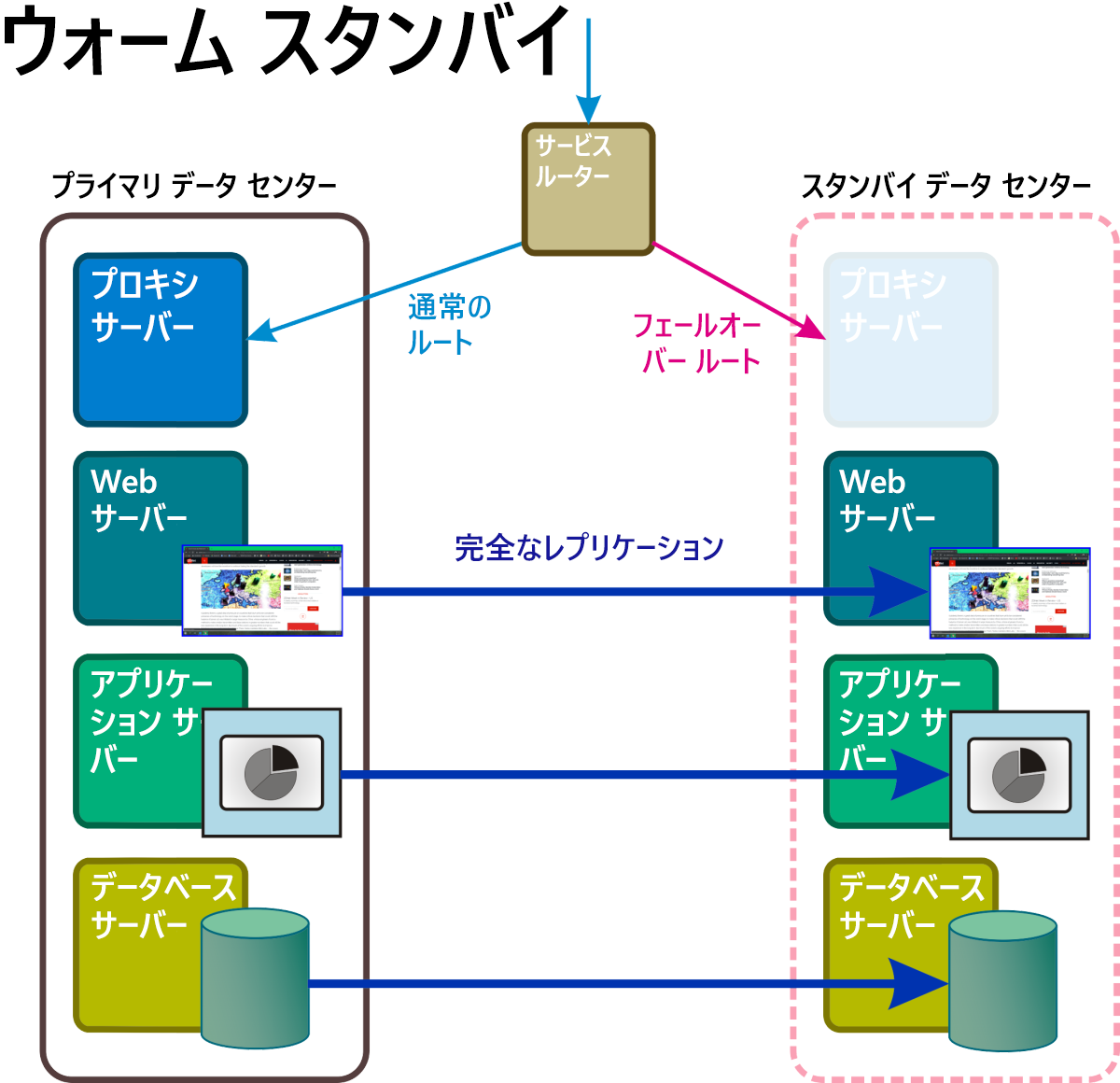
図 6: スタンバイ名前空間内の一部のコンポーネントが完全な動作状態にあるウォーム スタンバイ回復シナリオ。
ホット スタンバイ
このシナリオ (図 7) では、すべてのサービスおよびアプリケーションの少なくとも 2 つの完全なレプリカが常に実行されていて、それらの間ではデータが完全かつ継続的に同期されています。 マスター ルーターが一種のグランド ロード バランサーとして機能し、すべてのサーバーの場所にほぼ均等な比率で要求を分散します。 障害イベントが発生すると、ファイアウォールのようなプロセスがトリガーされ、影響を受けたシステムのアドレスがルーティング テーブルから削除されます。
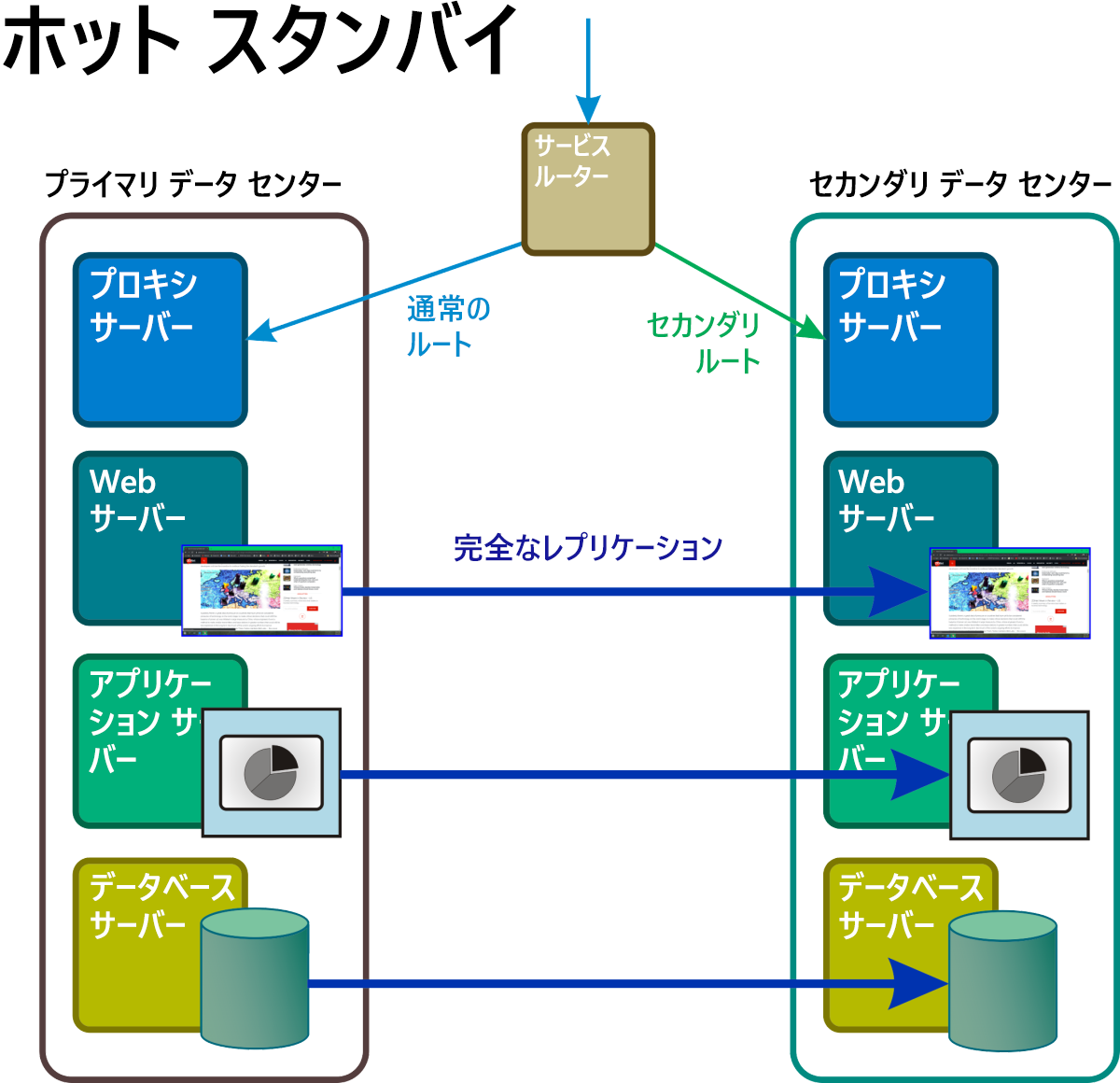
図 7: ホット スタンバイでは、通常予備のスタンバイ スペースであったものの名前空間にあるすべてのコンポーネントがアクティブで、完全な動作状態にあり、プライマリ データのレプリカをリアルタイムで処理します。
クラウド ネイティブ アプリケーション
あるプロバイダーのディザスター リカバリー サービスを、別のプロバイダーによってホストされるサービスのセーフティ ネットとして、組織が選択することは理論的に可能です。 言い換えると、IT 担当者が適切なレベルの注意を払っていれば、ある CSP のインフラストラクチャ (たとえば、Google) が、別の CSP のインフラストラクチャ (Azure など) でホストされているウォーム スタンバイ プロシージャのフェールオーバー先として機能する可能性があります。 この種のセットアップは、会計上の理由から必要な場合もあれば、企業内のコンピューティング リソースが世界各地の別々の部門によって管理されている場合に必要となる場合もあります。
現時点では、クラウドと同様に、オンプレミスのデータ センター内にコンテナー化されたインフラストラクチャが存在すると、このような DR 手法のすべてに大きな影響を与える可能性があります。 パブリック クラウド プラットフォーム、またはそれと同じように機能するプラットフォーム (Microsoft Azure Stack など) で使用するために専用に開発されたいわゆる "クラウドネイティブ アプリケーション" では、複数のレプリカ コンテナーに機能が分散され、その一部またはすべてが同時に機能することができます。 その理由は、新しいクラスの DR シナリオを有効にすることよりもむしろ、プロセッサ間でワークロードを分散させることにあります。
クラウドネイティブ アーキテクチャのもう 1 つの側面は、データが既に自動的にレプリケートされているデータベースが手元のアプリケーション専用のマップを持つネットワーク アドレスを使用して接続される機能です (つまり、インターネット プロトコルが使用されますが、そのアドレスは広範なパブリック インターネット上の場所ではありません)。これにより、障害イベント時には、データベースに接続されているノードの一部はダウンしますが多くは存続するので、他のものが、使用できなくなったノードの代わりとなります。 これは、組み込みのディザスター リカバリーとはまだ見なせないかもしれませんが、障害への耐性と言うことはできます。
サービスとしてのディザスターリカバリー (DRaaS)
パブリック クラウドサービス プロバイダーにおけるディザスター リカバリーとは、そのコア バックアップおよびデータ転送のサービスを使用する手段です。 主要な各 CPS では、そのバックアップ サービスに基づいて DR を円滑に進めるためにそれぞれ異なる戦略が実装されます。
AWS CloudEndure
"サービスの移行" とは、プライベートのオンプレミス インフラストラクチャからパブリック クラウド インフラストラクチャに仮想ワークロードを再配置することを意味しています。 この再配置は、パブリック クラウドで動作する一部のディザスター リカバリー サービスが障害イベントから数分以内にフェールオーバーおよび復旧というそのミッション目標を達成できるようにするために必要です。
2019 年 1 月、Amazon はプライベート サービスの移行サービス CloudEndure を獲得しました。CloudEndure ではインフラストラクチャ プロバイダーとして AWS が既に使用されていました。 それ以降、CloudEndure はメインのサービス ラインに統合され、Amazon の顧客に対してサービスの移行が無料で提供されるようになりました。 現在、AWS では、ウォームまたはホット スタンバイ プロセスを迅速に有効にする手段としてサービスの移行が実装されています。 AWS では、移行プロセスの料金は顧客に請求していませんが、DR シナリオごとにプロビジョニングされる冗長リソースについては料金を請求しています。 それでも、追加料金がないため、CloudEndure は多数のサードパーティ DR サービスに対して即座に競争力を発揮しています。
Azure Site Recovery
Microsoft の DR サービスである Azure Site Recovery は、VM ベースの環境や、Linux または Windows を実行している物理 (オンプレミス) サーバーを対象にしたウォーム スタンバイ回復手段のマネージド デプロイです。 VM はセカンダリ リージョンにアクティブにレプリケートされ (図 9.8)、ボタンをクリックするだけでそこへのフェールオーバーを開始できます。 Azure Site Recovery によって保護されているサーバーまたは VM ごとに月額料金 (現在、約 25 ドル) を顧客は請求されます。
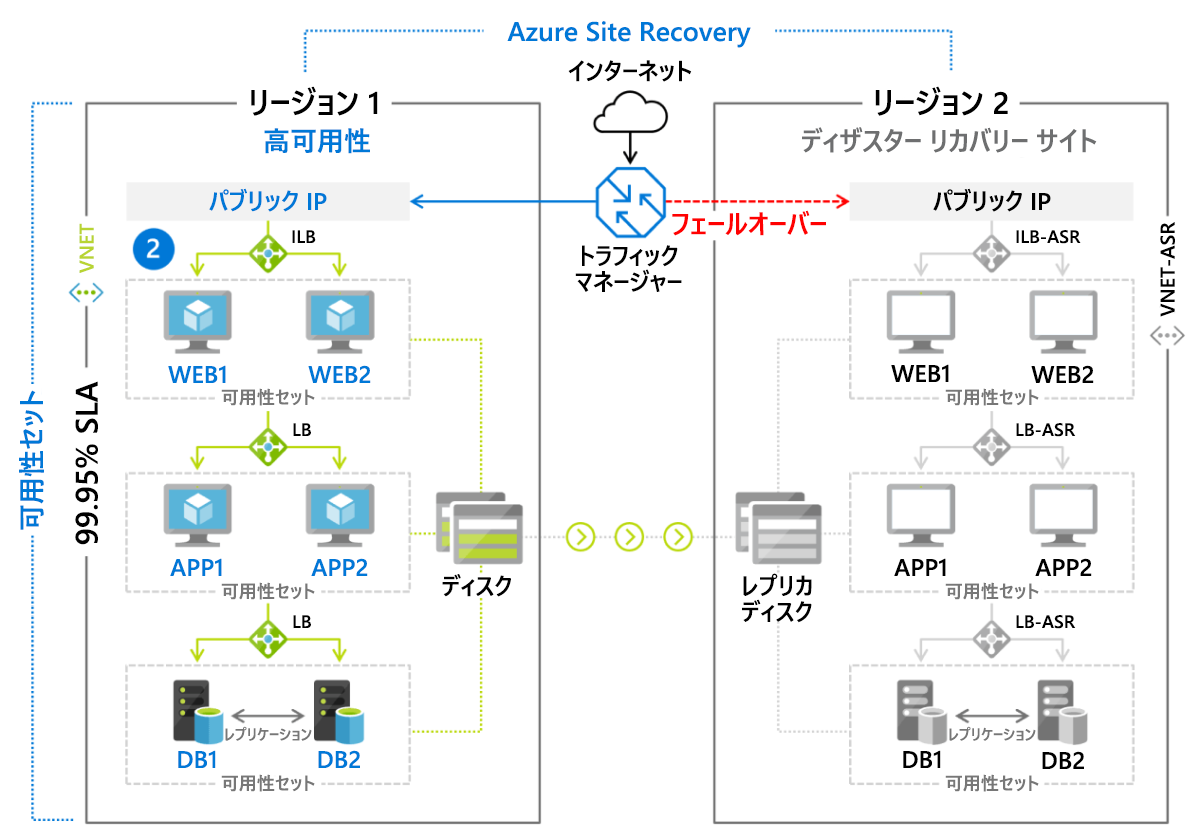
図 8: Azure Site Recovery を使用して実装されたフェールオーバー シナリオ。
Google Cloud DR
バックアップの場合と同様に、Google ではディザスター リカバリー専用のブランド化されたサービスを提供していません。 代わりに、データ ストレージとデータ転送に必要なツールとリソースを提供すると共に、それらをさまざまな DR シナリオに使用する場合の最適な方法について顧客にガイダンスを提供しています。
Google では Coldline ストレージ オプションを提供し、それに対する割引を適用しているため、幅広いシナリオに GCP が適用可能です。 Coldline は、大量の一括データを維持している組織にとって魅力的な選択肢です。 回転する磁気ディスクは、平均的なサイズが数十 GB に達するメディア ファイルの場合、非実用的な入れ物となります。 ネットワーク接続ストレージ (NAS) コンポーネントでは、メディアを作成する組織用向けのアクセシビリティおよび管理容易性のソリューションが提供されていますが、ローカル レベルに限定されています。 内部冗長性はありますが、障害に対する耐性はありません。 さらに、上に図示した 3 つのいずれかのような DR シナリオの場合、このクラスの顧客にとって現実的なものではありません (たぶん手頃な価格でもありません)。 Coldline では、ある程度のビジネス継続性保証を実現できるように、この顧客に対して少なくとも 1 つの実行可能な手段が提示されます。