負荷分散
トラフィックが増加したら新しい VM をオンラインにしてスケールアウトすることは、需要に合わせてスケーリングを行うための効果的な戦略です。 VM を迅速にプロビジョニングできるという事実は、弾力性を実現するために不可欠です。 ただし、それらのサーバー間でトラフィックが分散されない限り、追加のサーバーをオンラインにしても "役に立つ" ことはありません。 全体として、これはシステムで増加した負荷を処理するのに役立ちます。 弾力性にとって、タスクに割り当てられるリソースの数を動的に調整できるのと同じくらい負荷分散が重要なのは、そのためです。
負荷分散の必要性は、2 つの基本的な要件に由来します。 1 つ目として、スループットは並列処理によって向上します。 1 台のサーバーで単位時間あたり 5,000 件の要求を処理できる場合、完璧に負荷分散された 10 台のサーバーでは、単位時間あたり 5 万件の要求を処理できます。 2 つ目として、リソースが負荷分散されていると可用性が高くなります。 ロード バランサーでは、既に大きな負荷に苦労しているサーバーに要求を転送するのではなく、負荷の軽いサーバーに要求を送信することができます。 また、あるサーバーがオフラインになったことが、ロード バランサーによって認識された場合は、他のサーバーに要求を送信できます。
負荷分散とは
よく知られた負荷分散の形式は "ラウンドロビン DNS" であり、多くの大規模な Web サービスによって、複数のサーバーに要求を分散するために使用されています。 具体的には、それぞれが一意の IP アドレスを持つ複数のフロントエンド サーバーによって、DNS 名が共有されます。 各 Web サーバーで処理される要求の数を均等にするため、Google などの大企業では、DNS エントリごとに IP アドレスのプールの管理とキュレーションが行われています。 クライアントで要求が行われると (たとえば、www.google.com に対し)、Google の DNS によって、プールから使用可能なアドレスの 1 つが選択されて、クライアントに送信されます。 IP アドレスのディスパッチに使用される最も簡単な方法はラウンドロビン キューであり、各 DNS 応答の後でアドレスのリストの順序が変更されます。
クラウドが登場する前は、DNS 負荷分散が、長距離接続の待機時間を短縮するための簡単な方法でした。 DNS サーバーのディスパッチャーは、クライアントに地理的に最も近いサーバーの IP アドレスを使用して応答するようにプログラミングされていました。 これを行う最も簡単な方法は、クライアントの IP アドレスに数値として最も近い IP アドレスをプールから取得して応答することでした。 この方法は、IP アドレスがグローバル階層で分散されていないため、信頼できませんでした。 現在の手法はより洗練されており、インターネット サービス プロバイダー (ISP) の物理的なマップに基づく、IP アドレスから場所へのソフトウェア マッピングに依存しています。 このマッピングはコストのかかるソフトウェア参照として実装されているため、この方法では良い結果が得られますが、計算のコストがかかります。 一方、DNS 参照はクライアントがサーバーに初めて接続したときにだけ行われるため、低速参照のコストは分散されます。 それ以降のすべての通信は、クライアントと、ディスパッチされた IP アドレスを所有するサーバーとの間で、直接行われます。 図 9 に、DNS 負荷分散方式の例を示します。
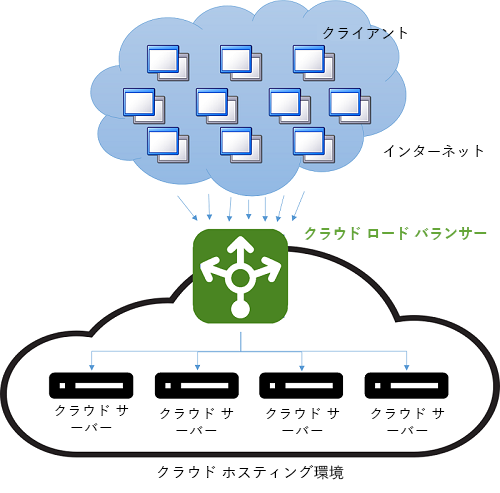
図 9: クラウド環境での負荷分散。
この方法の欠点はサーバーで障害が発生した場合であり、異なる IP アドレスへの切り替えは、DNS キャッシュの有効期限 (TTL) の構成に依存します。 DNS エントリは有効期間が長く、更新の伝達には 1 週間かかることがわかっています。 つまり、サーバーの障害をクライアントからすばやく "隠ぺいする" のは困難です。 キャッシュ内の IP アドレスの有効性 (TTL) を低下させると、このことは向上しますが、パフォーマンスが低下し、参照の数が増えます。
最新の負荷分散では、多くの場合、専用インスタンス (またはインスタンスのペア) を使用して、受信要求がバックエンド サーバーにディスパッチされます。 指定されたポートに着信した要求ごとに、ロード バランサーにより、分散戦略に基づいて、いずれかのバックエンド サーバーにトラフィックがリダイレクトされます。 そのため、ロード バランサーでは、アプリケーション プロトコル ヘッダー (たとえば HTTP ヘッダー) などの情報を含む要求メタデータが保持されています。 このような状況では、すべての要求がロード バランサーを通過するため、古い情報は考慮されません。
すべての種類のネットワーク ロード バランサーにより、要求はコンテキストと共にバックエンド サーバーに転送されますが、クライアントへの応答の提供に関しては、2 つの基本的な方法のいずれかを使用できます1。
プロキシ化 - この方法では、ロード バランサーがバックエンドから応答を受信し、それを中継してクライアントに戻します。 ロード バランサーは、標準の Web プロキシとして動作し、ネットワーク トランザクションの両方の半分、つまりクライアントへの要求の転送と、応答の返信に関係しています。
TCP ハンドオフ - この方法では、クライアントとの TCP 接続はバックエンド サーバーに引き継がれ、サーバーはロード バランサーを経由せずに直接クライアントに応答を送信します。
後者の戦略を図 10 に示します。
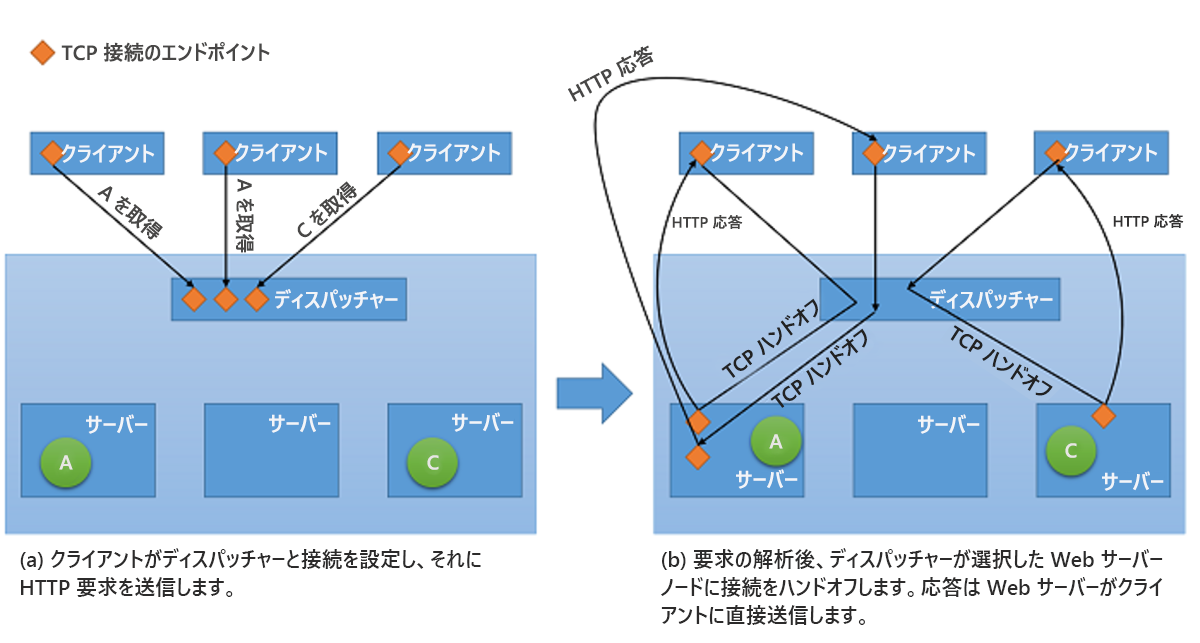
図 10: ディスパッチャーからバックエンド サーバーへの TCP ハンドオフのメカニズム。
負荷分散の利点
負荷分散の利点の 1 つは、システムでの障害を隠すのに役立つことです。 クライアントが複数のリソースを表す単一のエンドポイントに公開されている限り、個々のリソースでの障害は、他のリソースを使用して要求を処理することで、クライアントに認識されなくなります。 ただし、今度は、ロード バランサー自体が単一障害点になります。 何らかの理由で障害が発生すると、すべてのバックエンド サーバーがまだ機能していても、クライアントの要求は処理されません。 したがって、高可用性を実現するため、多くの場合、ロード バランサーはペアで実装されます。
さらに重要なことは、負荷分散を行うと、クラウド内の複数のコンピューティング リソースにワークロードが分散されることで、応答性が向上します。 クラウド内のコンピューティング インスタンスが 1 つだけの場合は、いくつかの制限があります。 以前のモジュールでは、パフォーマンスに関する物理的な制限が検討され、ワークロードを増やすためにはより多くのリソースが必要になります。 負荷分散を使用すると、大きなワークロードは複数のリソースに分散されるため、各リソースは個別に要求を並行して処理でき、アプリケーションのスループットが向上します。 また、負荷分散では、ワークロードを処理するサーバーが増えるため、平均応答時間も短縮されます。
負荷分散戦略を適切に実装するには、正常性チェックが重要です。 ロード バランサーでは、使用できなくなったリソースへのトラフィックの転送を回避できるよう、そのようなリソースを認識する必要があります。 特定のリソースの正常性を確認するために使用される最も一般的な戦術の 1 つは ping エコー監視であり、ロード バランサーはインターネット制御メッセージプロトコル (ICMP) 要求を使用してサーバーに ping を送信します。 トラフィックを転送するときに、リソースの正常性を考慮するだけでなく、一部の負荷分散戦略では、スループット、待機時間、CPU 使用率などの他のメトリックも考慮されます。
多くの場合、ロードバランサーでは高可用性を保証する必要があります。 これを行う最も簡単な方法は、(それぞれが一意の IP アドレスを持つ) 複数の負荷分散インスタンスを作成し、それを単一の DNS アドレスにリンクすることです。 何らかの理由で障害が発生したロード バランサーは常に、新しいものに置き換えられ、すべてのトラフィックは、パフォーマンスへの影響を最小限に抑えてフェールオーバー インスタンスに渡されます。 同時に、新しいロード バランサー インスタンスは障害が発生したものを置き換えるように構成することができ、DNS レコードを直ちに更新する必要があります。
ロード バランサーでは、バックエンド サーバー間への要求の分散だけでなく、多くの場合、サーバーの負荷を軽減し、全体的なスループットを向上させるメカニズムが使用されます。 これらのメカニズムには次のようなものがあります。
SSL オフロード -- HTTPS 接続では、トラフィックが暗号化されるため、パフォーマンス コストが増加します。 すべての要求を Secure Sockets Layer (SSL) 経由で提供するのではなく、ロード バランサーへのクライアント接続は SSL で行うことができますが、サーバーへのリダイレクト要求は暗号化されない HTTP で行われます。 この手法を使うと、サーバーの負荷が大幅に軽減されます。 また、リダイレクト要求が公開されたネットワーク経由で行われない限り、セキュリティが維持されます。
TCP バッファーリング -- 接続の遅いクライアントをロード バランサーにオフロードして、これらのクライアントに応答を提供するサーバーを軽減する方法です。
キャッシュ -- 特定のシナリオでは、最も一般的な要求 (または、静的コンテンツなど、サーバーに移動せずに処理できる要求) のキャッシュをロード バランサーで保持して、サーバーの負荷を軽減できます。
トラフィックのシェイプ -- ロード バランサーでこの手法を使用し、パケットのフローを遅延させたり、パケットのフローの優先順位を変更したりして、トラフィックをサーバー構成に最適化できます。 これにより、一部の要求の QoS は影響を受けますが、受信負荷は確実に処理できます。
負荷分散は、ロード バランサー自体に過剰な負荷がかかっていない場合にのみ機能することに注意してください。 そうでない場合、ロード バランサーがボトルネックになります。 幸いなことに、ロード バランサーでは受信した要求の処理はほとんど行われず、代わりに、要求を応答に変換する実際の作業はバックエンド サーバーで行われます。
公平なディスパッチ
クラウドでは、いくつかの負荷分散戦略が使用されます。 最も一般的なものの 1 つである "公平なディスパッチ" では、単純なラウンドロビン アルゴリズムを使用して、すべてのノード間にトラフィックが均等に分散されます。 システム内の個々のリソースの使用率や、要求の実行時間が考慮されることはありません。 この方法では、システムのすべてのノードをビジー状態にすることが試みられ、実装が最も簡単な方法の 1 つです。
AWS の Elastic Load Balancer (ELB) オファリングでは、この方法が使用されています。 ELB によってプロビジョニングされるロード バランサーは、接続されている EC2 インスタンス間にトラフィックを分散します。 ロード バランサー自体が、基本的に、トラフィックのルーティングに特化したサービスを備えた EC2 インスタンスです。 ロード バランサーの内側にあるリソースがスケールアウトされると、ロード バランサーの DNS レコードで、新しいリソースの IP アドレスが更新されます。 このプロセスは、監視とプロビジョニング両方の時間が必要になるため、完了までに数分かかります。 ロード バランサーが高い負荷を処理する準備が整うまでの待機時間であるこのスケーリングの期間は、ロード バランサーの "ウォームアップ" と呼ばれます。
また、AWS のロード バランサーでは、正常性チェックを維持するため、接続されているリソースでのワークロードの分散も監視されます。 すべてのリソースが正常であることを確認するためには、ping エコー メカニズムが使用されます。 ELB のユーザーは、遅延と再試行回数を指定することによって、正常性チェックのパラメーターを構成できます。
ハッシュ ベースの分散
この方法では、各要求を定義するメタデータのハッシュを作成し、ハッシュを使用してサーバーを選択することにより、セッションの期間中は、同じクライアントからの要求が毎回同じサーバーに送信されます。 ハッシュが適切に行われると、要求はサーバー間に比較的均等に分散されます。 この方法の利点の 1 つは、それがセッション対応のアプリケーションに適していることであり、セッション データを、データベースや Redis キャッシュなどの共有データ ストアに書き込むのではなく、メモリに格納できます。 欠点は、すべての要求をハッシュする必要があることであり、これによりわずかな待機時間が発生します。
Azure Load Balancer では、ハッシュ ベースのメカニズムを使用して負荷が分散されます。 このメカニズムでは、送信元 IP、送信元ポート、送信先 IP、送信先ポート、プロトコルの種類に基づいて、すべての要求に対してハッシュが作成されます。これにより、通常の状況では、同じセッションからのすべてのパケットが、同じバックエンドサーバーに送られます。 ハッシュ機能が選択されているのは、サーバーへの接続の分散がランダムなためです。
その他の負荷分散戦略
ラウンドロビン アルゴリズムまたはハッシュ ベースのディスパッチ アルゴリズムを使用するロード バランサーでは、特定のサーバーで要求 (または一連の要求) の処理が滞った場合でも、そのサーバーに要求が転送されます。 容量を考慮して複数のリソース間に負荷を分散する、さらに高度な戦略が他にあります。 容量を計測するために最もよく使用されるメトリックは、次の 2 つです。
要求実行時間 - このメトリックに基づく戦略では、優先スケジュール アルゴリズムが使用され、要求の実行時間を使用して、個々の要求の送信先が選択されます。 この方法を使用するときの主な課題は、実行時間を正確に測定することです。 ロード バランサーでは、要求が各サーバーに転送されてから戻ってくるまでの時間差を格納するメモリ内のテーブルを使用 (および絶えず更新) することで、実行時間を推測できます。
リソース使用率 - このメトリックに基づく戦略では、CPU 使用率を使用してノード間の使用率のバランスが取られます。 ロード バランサーでは、使用率に基づくリソースの順序付きリストが保持され、受信した各要求は負荷が最も少ないリソースに送信されます。
負荷分散は、スケーラブルなクラウド サービスを実装するうえで非常に重要です。 バックエンド リソース間にトラフィックを分散させるための効果的な手段がなければ、必要なときにリソースを作成し、不要になったらプロビジョニング解除することによって実現される弾力性は、非常に制限されたものになります。
参考資料
- Aron、Mohit および Sanders、Darren および Druschel、Peter および Zwaenepoel、Willy (2000)。 「クラスターベースのネットワーク サーバーでのスケーラブルなコンテンツ対応要求の分散」(2000 Annual USENIX technical Conference の議事録)