クラウドでの自動スケーリング
需要の増加に対応するためのスケールアップまたはスケールアウトと、需要が減少したときにコストを削減するためのスケールインまたはスケールダウンは、クラウド管理者が手動で実行できます。 たとえば、注意深い管理者は、需要が増加していることを検出し、クラウド サービス プロバイダーから提供されているツールを使用して、追加の VM をオンラインにしたり (スケールアウト)、既存の VM を CPU とメモリが多い大きな VM に置き換えたり (スケールアップ) することができます。 キー ワードは "注意深い" です。需要がピークになったことに誰も気付かないと、エンド ユーザーに対してシステム全体が遅くなり、応答しなくなる可能性さえあります。 逆に、大きな負荷に対応するためにスケールアップまたはスケールアウトしたのに、負荷が減少したときのスケールバックを怠ると、必要のないリソースに対して料金が発生します。
そのため、人気のあるクラウド プラットフォームでは、ユーザーが介入しなくても需要の変動に応じてリソースがスケーリングされる "自動スケーリング" メカニズムが提供されています。 自動スケールダウンには、主に次の 2 つの方法があります。
時間ベース -- 事前に定義されたスケジュールに従ってリソースをスケーリングします。 たとえば、組織の Web サイトの負荷が勤務時間中に最大になる場合は、リソースのスケールアップまたはスケールアウトが毎朝午前 8:00 時に行われ、毎日午後 5:00 時にスケールダウンまたはスケールインされるように、自動スケーリングを構成します。 時間ベースのスケーリングは、"スケジュール スケーリング" と呼ばれることもあります。
メトリック ベース -- 負荷を予測しにくい場合は、CPU 使用率、メモリ不足、要求の平均待機時間など、定義済みのメトリックに基づいてリソースをスケーリングします。 たとえば、平均 CPU 使用率が 70% に達したら、自動的に追加の VM をオンラインにし、30% に戻ったら、余分な VM のプロビジョニングを解除します。
スケーリングの基準として時間、メトリック、またはその両方のいずれを選択した場合でも、自動スケーリングは、クラウド管理者によって構成された "スケーリング ルール" または "スケーリング ポリシー" に基づいて行われます。 最新のクラウド プラットフォームでは、広範なスケーリング ルールがサポートされています。たとえば、毎日午前 8:00 にインスタンスを 2 個から 4 個に増やし、午後 5:00 に 2 個のインスタンスに戻すといった単純なものから、最大 CPU 使用率が 70% を超えるか、要求の平均待機時間が 5 秒に達した場合は、VM の数を 1 つ増やすといった複雑なものまで、指定できます。 ルールの適切な組み合わせを見つけるには、通常、クラウド管理者が何らかの実験を行う必要があります。
Amazon、Microsoft、Google など、すべての主要クラウド サービス プロバイダーで、自動スケーリングがサポートされています。 AWS Auto Scaling は、EC2 インスタンス、DynamoDB タブレット、および選択した他の AWS クラウド サービスに適用できます。 Azure では、App Service や Virtual Machines などの主要なサービスに、自動スケーリングのオプションが用意されています。 Google では、Google Compute Engine と Google App Engine に対して同じことが行われています。
通常、自動スケーリング サービスでは、スケールアップとスケールダウンではなく、スケールインとスケールアウトが行われます。その 1 つの理由は、スケールアップとスケールダウンではインスタンスの置き換えが必要であり、新しいインスタンスを作成してオンラインにするときに、どうしてもダウンタイムが発生するためです。
時間ベースの自動スケーリング
時間ベースの自動スケーリングは、負荷の変動が予測可能な場合に適しています。 たとえば、多くの組織の IT システムでは、勤務間中に負荷が最高になり、早朝の時間帯には負荷がほとんど、またはまったくなくなることがあります。 Domino's ピザは 100 近い国/地域に 16,000 を超える店舗があるので、その Web サイトは 1 日中負荷がかかっている可能性があります。 しかし、1 年の間の特定の時期には、通常より高い負荷がかかることが予想されます。
どちらのシナリオも、時間ベースの自動スケーリングの候補になります。 図 7 では、Azure でのスケジュールされた自動スケーリングの設定方法を示します。 この例のクラウド管理者は、組織の Web サイトをホストする Azure App Service を、既定では 2 個のインスタンスを実行しますが、次の時間帯にはインスタンスを 4 個にスケールアップするように構成しています: 午前 6:00 から午後 6:00 まで日曜日を除く 6 日間。 代わりに [開始/終了日の指定] オプションを選択すると、管理者は、スーパー ボウルの日曜日にはインスタンスを 10 個にスケールアウトするよう App Service を簡単に構成できます。 また、複数のスケーリング条件を定義して、他の日にスケールアウトを行うこともできます。
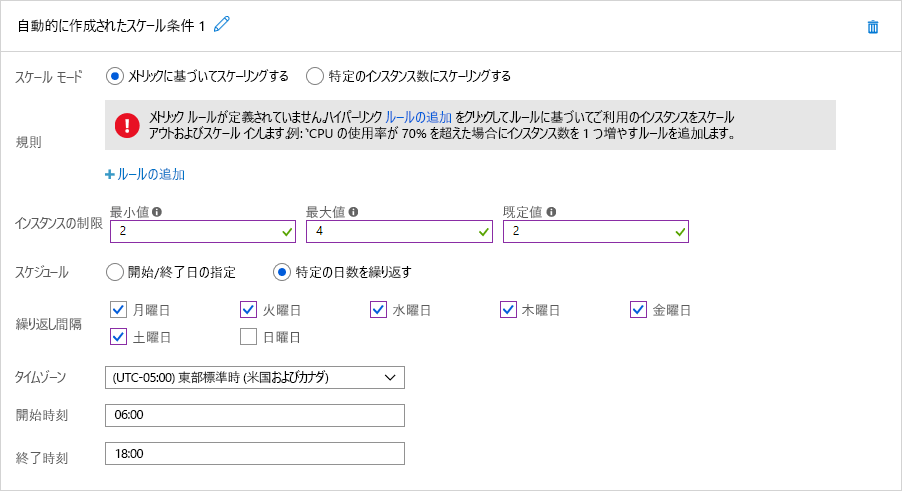
図 7: Azure でスケジュールされた自動スケーリング。
メトリック ベースの自動スケーリング
CPU 使用率や平均要求待機時間などのメトリックに基づくスケーリングは、負荷をあまり予測できない場合に適しています。 自動スケーラーは監視によってスケーリングのタイミングを知ることができるので、監視はパフォーマンス メトリックに基づくリソースの効果的な自動スケーリングのための重要な要素です。 監視によってトラフィック パターンやリソース使用率を分析できるようになり、コストを最小限に抑えながら、サービスの品質が最大限になるように、リソースをスケーリングするタイミングと量を、情報に基づいて評価できます。
リソースのスケーリングをトリガーするために監視されるリソースには、いくつかの側面があります。 最も一般的なメトリックは、リソース使用率です。 たとえば、監視サービスでは、各リソース ノードの CPU 使用率を追跡し、使用量が多すぎたり少なすぎたりする場合は、リソースをスケーリングすることができます。 たとえば、各リソースの使用率が 90% を超える場合は、システムの負荷が高いため、おそらく、リソースを追加するのが適切な対応です。 通常、サービス プロバイダーは、リソース ノードの限界点 (障害が起き始めるとき) を分析し、さまざまな負荷レベルでの動作を明らかにすることによって、これらのトリガー ポイントを決定します。 コスト上の理由から、各リソースを最大限に活用することは重要ですが、オーバーヘッド アクティビティに対応できるよう、オペレーティング システム用にある程度の余裕を残しておくことをお勧めします。 同様に、使用率がたとえば 30% 未満の場合は、すべてのリソース ノードが必要ではなく、一部をプロビジョニング解除できる可能性があります。
実際、サービス プロバイダーは、通常、リソース ノードの複数の異なるメトリックの組み合わせを監視して、リソースをスケーリングするタイミングを評価しています。 そのようなものには、CPU 使用率、メモリ消費量、スループット、待機時間などが含まれます。 AWS では、CloudWatch を使用して EC2 リソースが監視され、スケーリング メトリックが提供されます (図 8)。 CloudWatch により、スケーリング グループ内のすべての EC2 インスタンスのメトリックが追跡されて、指定したメトリックがしきい値を超えると (CPU 使用率が 70% を超えた場合など) アラームが発生します。 その後、AWS では、管理者によって構成されたスケーリング ポリシーに基づいて、EC2 インスタンスの数が増減されます。
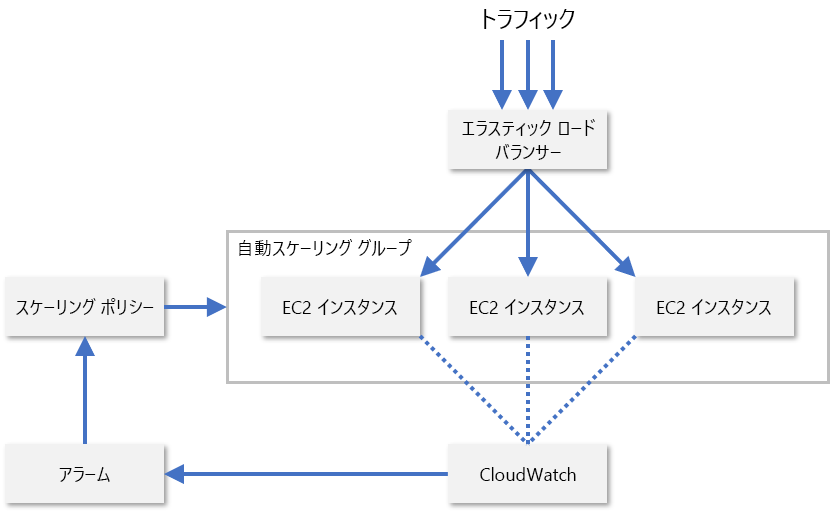
図 8: AWS での EC2 インスタンスの自動スケーリング。
AWS では、機械学習を使用してトラフィック パターンを予測し、それに応じてインスタンスの数を管理する "予測スケーリング" もサポートされています。 目標は、クラウド管理者による自動スケーリング ルールの構成を必要とせずに、クラウド リソースをインテリジェントにスケーリングすることです。 主要なクラウド サービス プロバイダーは、機械学習を使用してプラットフォームを改善するための新しい方法を常に探しています。 たとえば、Microsoft では、VM の障害を事前に予測し、軽減することで、Azure Virtual Machines の回復性を向上させるために、機械学習が使用されるようになっています1。
参考資料
- Microsoft (2018)。 予測 ML とライブ マイグレーションによる Azure 仮想マシンの回復性の向上。 https://azure.microsoft.com/blog/improving-azure-virtual-machine-resiliency-with-predictive-ml-and-live-migration/。