コンピューティング リソースのスケーリング
クラウドの重要な利点の 1 つは、需要に応じてシステムのリソースをスケーリングできることです。 スケールアップ (より大きなリソースのプロビジョニング) またはスケールアウト (追加のリソースのプロビジョニング) を使用すると、容量の増加またはワークロードの分散の拡大の結果として、使用率が低下するため、システムの負荷を軽減できます。
スケーリングは、より多くの要求の処理が可能になることによるスループットの増加のため、応答性 (およびユーザーが感じるパフォーマンス) の向上に役立ちます。 これにより、負荷がピークのときに 1 つのリソースでキューに格納される要求の数が少なくなるため、ピーク負荷発生時の待機時間を短縮することもできます。 さらに、スケーリングを行うと、リソースの使用率が低下し、限界に近づくことがなくなるので、システムの信頼性を向上させることができます。
クラウドを使用すると、新しいリソースやより優れたリソースを簡単にプロビジョニングできますが、対立要因としてコストを常に考慮しなければならないことに注意することが重要です。 そのため、スケールアップまたはスケールアウトするのが有益な場合でも、コストを節約するためにスケールインまたはスケールダウンするタイミングを認識することが重要です。
水平スケーリング (スケールインとスケールアウト)
水平スケーリングは、時間の経過と共に新しいリソースがシステムに追加されるか、余分なリソースがシステムから削除される戦略です。 この種のスケーリングは、システムの負荷の変動が一貫していない場合や予測不可能な場合に、サーバー層にとって有益です。 変動する負荷の性質上、負荷を常に処理するために適切な量のリソースをプロビジョニングすることが不可欠になります。
これを難しい作業にする考慮事項として次のようなものがあります
- インスタンスのスピンアップ時間 (例: 仮想マシン)
- クラウド サービス プロバイダーの価格モデル
- スケールアウトが遅れたためにサービスの品質 (QoS) が低下することによる収益損失の可能性。
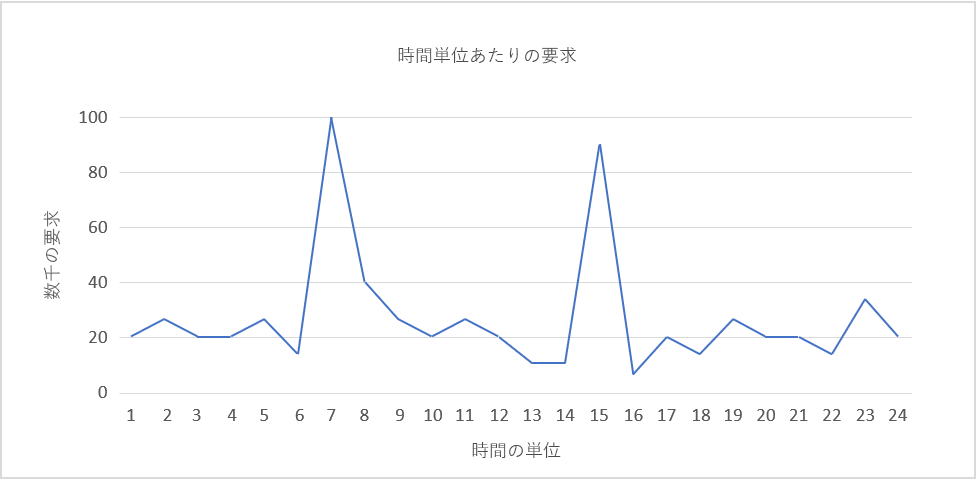
図 5: 負荷パターンの例。
例として、上の図 5 のような負荷パターンについて考えてみます。
アマゾン ウェブ サービスを使用しており、各単位時間は実際の 1 時間に相当し、5,000 件の要求を処理するのに 1 台のサーバーが必要であるとします。 需要のピークは、時間単位 6 から 8 の間と、時間単位 14 から 16 の間です。 後者を例として考えてみましょう。 時間単位 16 のあたりで需要の低下が検出され、割り当てられたリソースの数を減らし始めることができます。 3 時間の間に要求は約 9 万件から 1 万件になるため、計算上は、15 の時点でオンラインになっていた 12 個以上の追加インスタンスのコストを節約することができます。
図 6 は、負荷パターンに対応してインスタンス数を調整するスケーリング パターンを示したもので、インスタンス数が赤で示されています。 需要がピークになったとき、インスタンスの数はそれぞれ 20 および 18 にスケールアウトされ、トラフィックを処理するために必要なリソースが提供されます。 それ以外の時間は、リソース使用率を比較的一定に保つために、インスタンス数が削減 (スケールイン) されます。 各インスタンスのコストを時間あたり 20 セントと想定すると、20 個のインスタンスを 24 時間動かし続けるためのコストは 96 ドルになります。 示されているようにインスタンス数をスケーリングすると、コストは約 42 ドルに減り、年間で 15,000 ドル以上を節約できます。 それは、ほとんどの IT 予算にとってかなりの金額です。
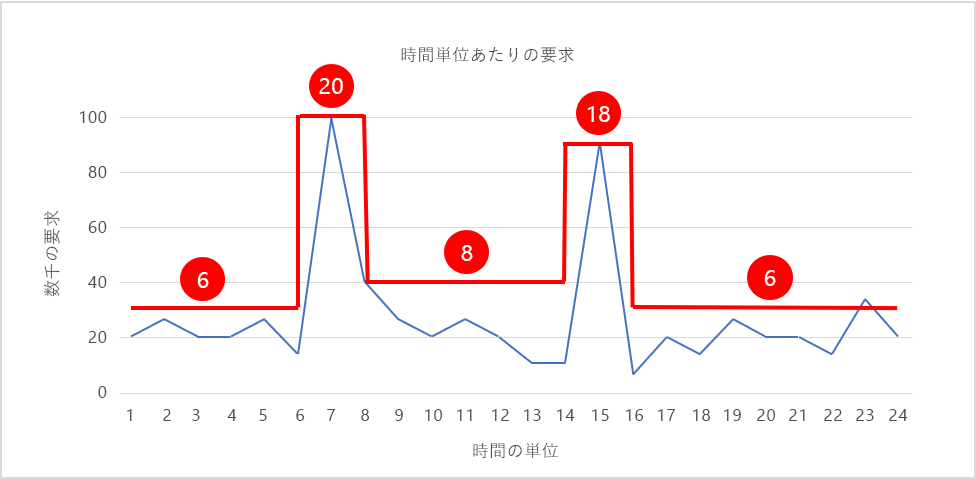
図 6: 需要に応じたスケールインとスケールアウト。
スケーリングは、トラフィックの特性と、その後に Web サービスで生成される負荷によって異なります。 トラフィックが予測可能なパターンに従っている場合 (たとえば、夜間に Web サービスから映画をストリーミングするといった人間の行動に基づく場合)、QoS を維持するために 予測 に基づいてスケーリングを行うことができます。 しかしながら、多くの場合はトラフィックを予測できず、さまざまな条件に基づいて "対応" するスケーリング システムにする必要があります。
スケールインとスケールアウトは、コンテナー インスタンス数と VM インスタンス数について実行できることに注意してください。 ワークロードは、従来は VM のクラウドで実行されていましたが、コンテナーで実行することがますます一般的になっています。 VM ベースのワークロードでは、VM 数を増減させることでスケーリングを実現できます。 同様に、コンテナー ベースのワークロードは、コンテナーの数を変更することでスケーリングできます。 VM よりコンテナーの方がすばやく開始できる傾向があり、新しいコンテナー インスタンスの方が VM インスタンスより短時間でオンラインにできるため、弾力性が若干向上します。
垂直スケーリング (スケールアップとスケールダウン)
水平スケーリングは弾力性を実現するための 1 つの方法ですが、唯一の方法ではありません。 たとえば、Web サイトへのトラフィックが単位時間あたり 15,000 要求を超えることはめったになく、2 万件を処理できる単一の大きいインスタンスをプロビジョニングするものとします。これは、通常のトラフィックに適切に対応するのに十分であり、小規模なピークも考慮されています。 Web サイトの負荷が増加した場合、CPU コアの数と RAM の量がそれぞれ 2 倍のサーバー インスタンスに置き換えることで、トラフィックの増加に十分に対応できます。 これは、"スケールアップ" と呼ばれる方法です。
垂直スケーリングの主な課題は、一般に、ダウンタイムと見なされる切り替え時間が発生することです。 これは、小さいインスタンスから大きいインスタンスにすべての操作を移動するためであり、切り替え時間がわずか数分であっても、その間はサービスの品質が低下します。
垂直スケーリングのもう 1 つの制限は、細分性が低くなることです。 10 個のサーバー インスタンスがオンラインになっていて、一時的に容量を 10% 増やす必要がある場合、インスタンスの数を 10 から 11 にスケールアウトすることで、目的の結果を達成できます。 しかし、垂直スケーリングでは、次に大きいインスタンス サイズは、前のサイズの 2 倍の容量になるのが普通です。これは、水平スケーリングで、10% のトラフィック増加に対応するためだけに、インスタンスを 10 個から 20 個にするのに相当します。 これでは、水平スケーリングよりコスト効率が悪くなります。
垂直スケーリングについて必要な最後の考慮事項は、可用性です。 1 つの大きいインスタンスで Web サイトのすべてのお客様にサービスを提供している場合、そのインスタンスがダウンすると、Web サイトもダウンします。 これに対し、同じ負荷を処理するために 10 個の小さいインスタンスをプロビジョニングしている場合は、そのうちの 1 つがダウンしても、パフォーマンスがわずかに低下する可能性はありますが、サイトには引き続きアクセスできます。 そのため、負荷が予測可能であり、サービスの人気が増すにつれて負荷が着実に増加する場合であっても、多くのクラウド管理者は、垂直スケーリングではなく水平スケーリングを選択しています。
サーバー層のスケーリング
スケーラビリティは、より多くのリソース (スケールアウト) またはより大きいリソース (スケールアップ) の単なるプロビジョニングより微妙になることがあります。 サーバー層では、需要の増加により、CPU、メモリ、ネットワーク帯域幅などの特定の種類のリソースの競合が増える可能性があります。 クラウド サービス プロバイダーでは、通常、コンピューティング集中型ワークロード、メモリ集中型ワークロード、およびネットワーク集中型ワークロード用に最適化された VM が提供されています。 ワークロードを理解し、適切な種類の VM を選択することは、問題に対して VM を増やしたり大きくしたりするのと同じように重要なことです。 CPU 集中型ワークロード用に最適化された VM のコストが、汎用的な VM より 20% 高い場合でも、コンピューティング集中型ワークロードを処理する 5 個の VM の方が、10 個の汎用 VM より優れています。
ハードウェア リソースを増やすことが、サービスのパフォーマンスを向上させるための常に最適なソリューションであるとは限りません。 サービスによって使用されるアルゴリズムの効率を上げることでも、リソースの競合が減り、使用率が向上して、物理リソースのスケーリングの必要がなくなる場合があります。
スケーリングに関して重要な考慮事項は、ステートフル性 (またはその欠如) です。 ステートレス サービスの設計は、スケーラブルなアーキテクチャに適しています。 ステートレス サービスは基本的に、サーバーで要求を処理するために必要なすべての情報が、クライアント要求に含まれていることを意味します。 サーバーでは、クライアント関連の情報はインスタンスに格納されず、サーバー インスタンスにはセッション関連の情報が格納されます。
ステートレス サービスを使用すると、リソースを自由に切り替えることができ、後続の要求のためにクライアント接続のコンテキスト (状態) を維持するように構成する必要はありません。 ステートフルなサービスでリソースをスケーリングする場合は、既存の構成から新しい構成にコンテキストを転送する戦略が必要です。 ステートフル サービスを実装する複数の手法があることに注意してください。たとえば、サーバー間でコンテキストを共有できるように、ネットワーク キャッシュを維持します。
データ層のスケーリング
データベースやストレージ システムに対する読み取りと書き込み (またはその両方) が多いデータ指向アプリケーションでは、各要求のラウンドトリップ時間が、ハード ディスクの読み取りと書き込みの時間によって制限されることがよくあります。 インスタンスを大きくすると I/O パフォーマンスが向上し、ハード ディスクのシーク時間が短縮されて、サービスの待機時間が短縮されます。 データ層に複数のデータインスタンスがあると、フェールオーバーの冗長性が提供されるため、アプリケーションの信頼性と可用性が向上しますが、複数のインスタンス間でデータをレプリケートすると、クライアントが物理的に近いデータセンターによってサービスを提供される場合は、ネットワーク待機時間が減ってさらにメリットがあります。 "シャーディング" (複数のリソースにまたがるデータのパーティション分割) は、もう 1 つの水平データ スケーリング戦略であり、データを複数のインスタンスに単にレプリケートするのではなく、データは複数のインスタンスにパーティション分割されて、複数のデータ サーバーに格納されます。
データ層のスケーリングに関する固有の課題は、整合性 (読み取り操作がすべてのレプリカで同じであること)、可用性 (読み取りと書き込みが常に成功すること)、パーティションの許容性 (障害によってノード間の通信が妨げられたときに、システムで保証された特性が維持されること) の維持です。 これは、"CAP 法則" と呼ばれることがよくあり、分散データベース システムでは、3 つの特性すべてが完全に達成されることは非常に困難であり、特性のうちの 2 つの組み合わせが実現されればよい方であることを示します1。
参考資料
- Wikipedia。 CAP 法則。 https://en.wikipedia.org/wiki/CAP_theorem。