負荷分散
コンピューティングにおける負荷分散の必要性は、2 つの基本的な要件に由来します。まず、レプリケーションによって高可用性を向上させることができます。 第 2 に、並列処理によってパフォーマンスを向上させることができます。 高可用性とは、クライアントからサービスにアクセスしようとしたときにほぼ 100% 利用できるサービスの特性です。 通常、特定のサービスのサービス品質 (QoS) には、スループットや待機時間の要件など、いくつかの考慮事項が含まれます。
負荷分散とは
最もよく知られている負荷分散の形式は "ラウンド ロビン DNS" であり、多数のサーバー間で要求を負荷分散するために多くの大規模な Web サービスで採用されています。 具体的には、それぞれが一意の IP アドレスを持つ複数のフロントエンド Web サーバーによって、DNS 名が共有されます。 これらの各 Web サーバー上で要求数のバランスを取るために、Google などの大企業は、単一の DNS エントリに関連付けられた IP アドレスのプールを維持および管理しています。 クライアントで要求が行われると (たとえば、ドメイン www.google.com に対し)、Google の DNS によって、プールから使用可能なアドレスの 1 つが選択されて、クライアントに送信されます。 IP アドレスのディスパッチに使用される最も簡単な方法はシンプルなラウンドロビン キューであり、各 DNS 応答の後でアドレスのリストの順序が変更されます。
クラウドが登場する前は、DNS 負荷分散が長距離接続の待機時間に対処する簡単な方法でした。 DNS サーバーのディスパッチャーは、クライアントに地理的に最も近いサーバーの IP アドレスを使用して応答するようにプログラミングされていました。 これを行う最も簡単なスキームは、クライアントの IP アドレスに数値的に最も近いプールの IP アドレスで応答を試みることでした。 もちろん、この方法は信頼性がありませんでした。IP アドレスがグローバル階層に分散されていないためです。 現在の手法はより洗練されており、インターネット サービス プロバイダー (ISP) の物理的なマップに基づく、IP アドレスから場所へのソフトウェア マッピングに依存しています。 これはコストのかかるソフトウェア参照として実装されているため、この方法では良い結果が得られますが、計算のコストがかかります。 一方、DNS 参照はクライアントがサーバーに初めて接続したときにだけ行われるため、低速参照のコストは分散されます。 それ以降のすべての通信は、クライアントと、ディスパッチされた IP アドレスを所有するサーバーとの間で、直接行われます。 DNS 負荷分散スキームの例を次の図に示します。
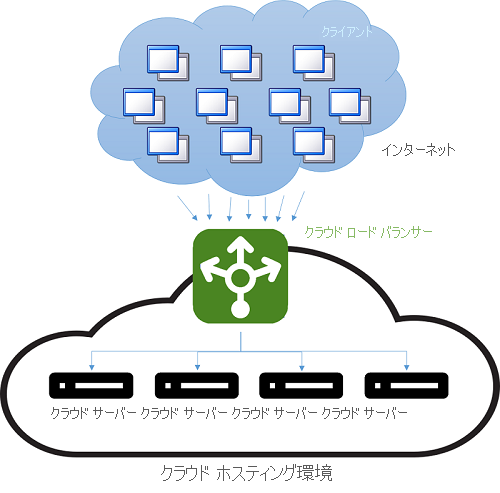
図 4: クラウド ホスティング環境での負荷分散
この方法の欠点は、サーバーに失敗が発生した場合、別の IP アドレスへの切り替えが DNS キャッシュの有効期限 (TTL) の構成に依存することです。 DNS エントリは有効期間が長く、インターネットを介した更新の伝達には 1 週間かかることがわかっています。 そのため、サーバーの障害をクライアントからすばやく "隠ぺいする" のは困難です。 これは、キャッシュ内の IP アドレスの有効期間 (TTL) を短縮することで改善できますが、その結果、パフォーマンスが犠牲になり、参照回数が増えます。
多くの場合、最新の負荷分散とは、着信トラフィックをバックエンド サーバーに転送する専用インスタンス (またはインスタンスのペア) を使用することを指します。 指定されたポートに着信した要求ごとに、ロード バランサーにより、分散戦略に基づいて、いずれかのバックエンド サーバーにトラフィックがリダイレクトされます。 これにより、ロード バランサーでは、アプリケーション プロトコル ヘッダー (HTTP ヘッダーなど) などの情報を含む要求メタデータを維持できます。 このような状況では、すべての要求がロード バランサーを経由するため、情報が失効する問題は起こりません。
ネットワーク ロード バランサーのすべての種類において、ユーザーの情報はコンテキストと共にバックエンド サーバーに転送されるだけですが、クライアントへの応答に関しては、2 つの基本的な方法のいずれかを使用できます。1
- プロキシ処理: この方法では、ロード バランサーがバックエンドから応答を受信し、それを中継してクライアントに戻します。 ロード バランサーは、標準の Web プロキシとして動作し、ネットワーク トランザクションの両方の半分、つまりクライアントへの要求の転送と、応答の返信に関係しています。
- TCP ハンドオフ この方法では、クライアントとの TCP 接続がバックエンド サーバーに渡されます。 そのため、サーバーからは、ロード バランサーを経由せずに、クライアントに応答が直接送信されます。
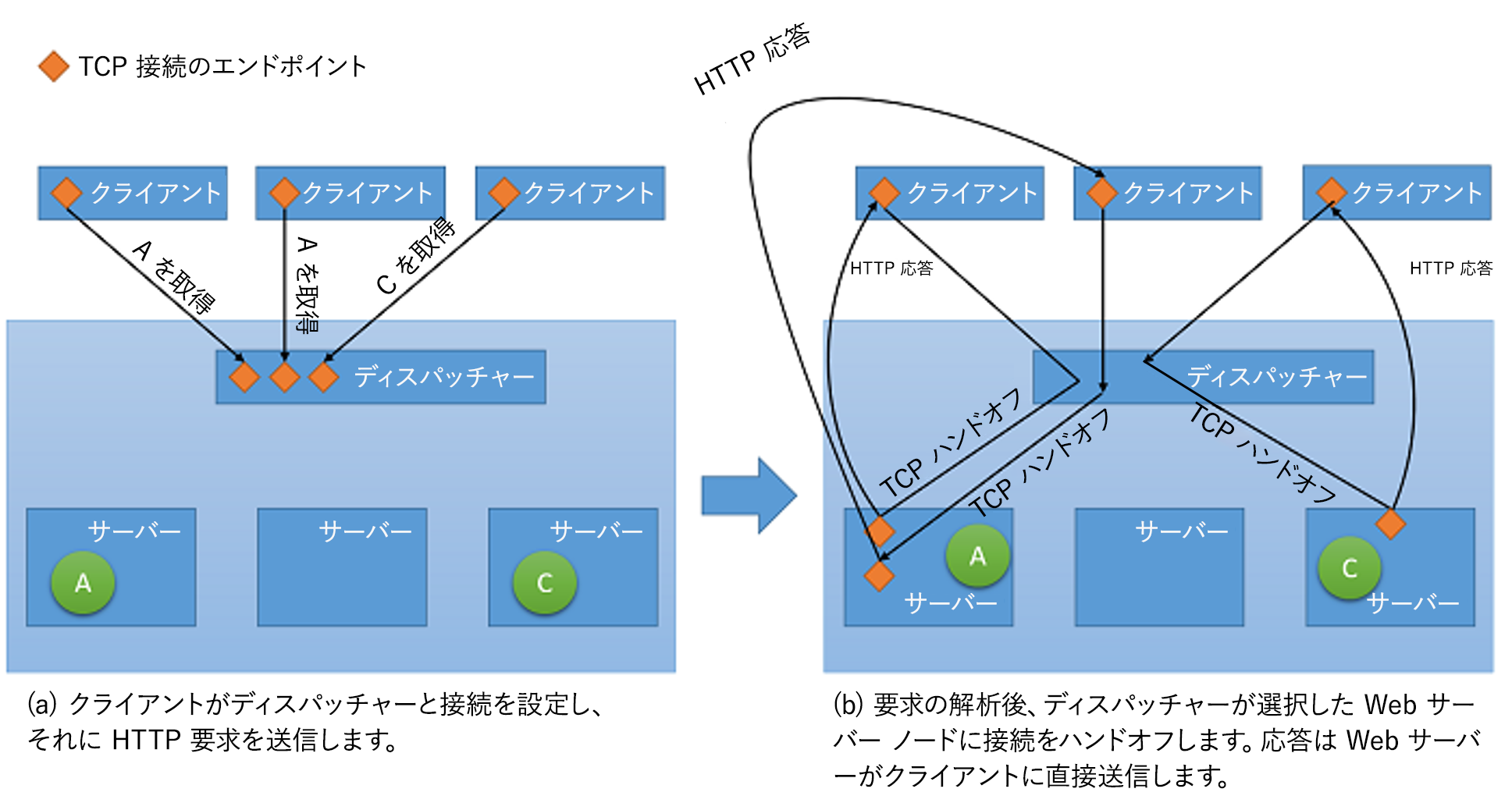
図 5: ディスパッチャーからバックエンド サーバーへの TCP ハンドオフのメカニズム
可用性とパフォーマンスへの影響
負荷分散は、システムの失敗をマスクするための重要な戦略です。 複数のリソース間で負荷を分散している単一のエンドポイントに対してシステムのクライアントが公開されていれば、別のリソースで要求を処理するだけで、個々のリソースの失敗をクライアントからマスクできます。 ただし、ロード バランサーがサービスの単一障害点となったことに注意する必要があります。 何らかの理由で障害が発生すると、すべてのバックエンド サーバーがまだ機能していても、クライアントの要求は処理されません。 そのため、高可用性を実現するため、多くの場合、ロード バランサーはペアで実装されます。
負荷分散により、サービスではクラウド内の複数のコンピューティング リソースにワークロードを分散できます。 クラウド内のコンピューティング インスタンスが 1 つだけの場合は、いくつかの制限があります。 パフォーマンスに関する物理的な制限について前述したように、ワークロードを増やすためにはより多くのリソースが必要になります。 負荷分散を使用することにより、より多くのワークロードを複数のリソースに分散させることができます。それにより、各リソースが独立して要求を並行処理できるため、アプリケーションのスループットが向上します。 また、ワークロードを処理するサーバーが増えるため、平均サービス時間が改善されます。
負荷分散戦略を成功させるには、サービスの確認と監視が重要です。 ロード バランサーでは、各リソース ノードが使用可能であることを確認することで、すべての要求を確実に満たす必要があります。 そうしないと、トラフィックはその特定のノードに送信されません。 ping エコー監視は、特定のリソース ノードの状態を確認するための最も一般的な方法の 1 つです。 一部の負荷分散戦略では、ノードの正常性に加えて、トラフィックを転送するうえで最適なリソースを評価するために、スループット、待機時間、CPU 使用率などの追加情報が必要です。
多くの場合、ロードバランサーでは高可用性を保証する必要があります。 これを行う最も簡単な方法は、(それぞれが一意の IP アドレスを持つ) 複数の負荷分散インスタンスを作成し、各インスタンスを単一の DNS アドレスにリンクすることです。 何らかの理由で障害が発生したロード バランサー インスタンスは常に、新しいものに置き換えられ、すべてのトラフィックは、パフォーマンスへの影響を小規模に抑えてフェールオーバー インスタンスに渡されます。 同時に、新しいロード バランサー インスタンスは障害が発生したものを置き換えるように構成することができます。また、DNS レコードは直ちに更新するようにします。
負荷分散の戦略
クラウドには、いくつかの負荷分散戦略があります。
公平なディスパッチ
これは負荷分散に対する静的な方法です。単純なラウンドロビン アルゴリズムを使用してすべてのノード間でトラフィックが均等に分割され、システム内の個々のリソース ノードの使用率や要求の実行時間は考慮されません。 この方法では、システムのすべてのノードをビジー状態にすることが試みられ、実装が最も簡単な方法の 1 つです。 この方法の重大な欠点は、大量のクライアント要求が同じデータ センターに集中し、一部のノードが過負荷になり、残りは十分に利用されない可能性があることです。 ただし、これには非常に限定された負荷パターンが必要であり、接続の分散と容量が非常に均一な多数のクライアントとサーバーでは実際に発生する可能性は低くなります。 ただし、この戦略では、空間的な局所性 (現在フェッチされているデータの近くのデータをプリフェッチしてキャッシュする) などの考慮事項を考慮したキャッシュ戦略をデータセンターに実装することが困難になります。これは、同じクライアントが作成した次の要求が別のサーバー上で処理が完了する可能性があるためです。
AWS の ELB (Elastic Load Balancer) オファリングでは、この方法が使用されています。 AWS ELB を使用すると、接続された EC2 インスタンス間でトラフィックを分散するロード バランサーをプロビジョニングできます。 ロード バランサー自体が、基本的に、トラフィックのルーティングに特化したサービスを備えた EC2 インスタンスです。 ロード バランサーの内側にあるリソースがスケールアウトされると、ロード バランサーの DNS レコードで、新しいリソースの IP アドレスが更新されます。 このプロセスは、監視とプロビジョニング両方の時間が必要になるため、完了までに数分かかります。 このスケーリングの期間 (ロード バランサーが高い負荷を処理する準備が整うまでの時間) は、ロード バランサーの "ウォームアップ" と呼ばれます。
AWS の ELB ロード バランサーでは、正常性チェックを維持するために、ワークロード分散のために接続されている各リソースも監視されます。 すべてのリソースが正常であることを確認するためには、ping エコー メカニズムが使用されます。 ELB のユーザーは、遅延と再試行回数を指定することによって、正常性チェックのパラメーターを構成できます。
ハッシュベースの分散
この方法では、同じ接続を介してクライアントから行われた要求が、常に同じサーバー上で処理が完了するように試行されます。 さらに、要求のトラフィック分散のバランスを取るために、ランダムな順序で行われます。 これはラウンドロビン方法に比べていくつかの利点があります。状態の永続化とキャッシング戦略がはるかに簡単になるセッション対応アプリケーションで役立つためです。 また、分布がランダムであるため、単一サーバーで輻輳が発生するようなトラフィック パターンの影響を受けにくくなりますが、リスクは依然として存在します。 ただし、関連するサーバーにルーティングするために、すべての要求の接続メタデータを評価する必要があるため、すべての要求にわずかな待機時間が生じます。
Azure Load Balancer では、負荷を分散するために、このようなハッシュベースの分散メカニズムが使用されます。 このメカニズムでは、接続元 IP、接続元ポート、接続先 IP、接続先ポート、およびプロトコルの種類に基づいて、すべての要求のハッシュが作成されます。これは、同じ接続からのすべてのパケットが常に同じサーバーに到達するようにするためです。 サーバーへの接続の分散が非常にランダムになるようにハッシュ関数が選択されます。
Azure には、3 種類のプローブを使用する正常性チェックが用意されています。ゲスト エージェント プローブ (PaaS VM 上)、HTTP カスタム プローブ、TCP カスタム プローブです。 3 つのプローブには、いずれも ping エコー メカニズムを介したリソース ノードの正常性チェックが用意されています。
その他の一般的な戦略
複数のリソース間で負荷を分散するために使用される他の戦略があります。 特定の要求に最適なリソース ノードを測定するために、それぞれが異なるメトリックを使用します。
- 要求の実行時間に基づく戦略: これらの戦略では、優先順位スケジューリング アルゴリズムが使用され、負荷分散の最適な順序を判断するために要求の実行時間が使用されます。 この方法を使用する際の主な課題は、特定の要求の実行時間を正確に予測することです。
- リソース使用率に基づく戦略: これらの戦略では、各リソース ノードの CPU 使用率を使用して、各ノード間で使用率のバランスを取ります。 ロード バランサーでは、使用率に基づいてリソースの順序付きリストが維持され、最も負荷の少ないノードに要求が送信されます。
その他の利点
一元化されたロード バランサーを使用すると、サービスのパフォーマンスを向上させるいくつかの戦略に役立ちます。 ただし、これらの戦略が機能するのは、ロード バランサーで対応不能な負荷が発生していない場合のみであることに注意してください。 そうしないと、ロード バランサー自体がボトルネックになります。 これらの戦略の一部を以下に示します。
- SSL オフロード: SSL を介したネットワーク トランザクションには、暗号化と認証の処理が必要なため、追加のコストがかかります。 SSL 経由ですべての要求を処理するのではなく、ロード バランサーへのクライアント接続を SSL 経由で行い、さらに個々の各サーバーへのリダイレクト要求を HTTP 経由で行うことができます。 これにより、サーバーの負荷が大幅に軽減されます。 また、リダイレクト要求が公開されたネットワーク経由で行われない限り、セキュリティが維持されます。
- TCP バッファーリング: これは、接続の遅いクライアントに応答を提供するサーバーの負荷を軽減するために、このようなクライアントをロード バランサーにオフロードする戦略です。
- キャッシュ: 特定のシナリオでは、最も一般的な要求 (または、静的コンテンツなど、サーバーに移動せずに処理できる要求) のキャッシュをロード バランサーで保持して、サーバーの負荷を軽減できます。
- トラフィック シェーピング: アプリケーションによっては、ロード バランサーを使用してパケットのフローを遅延させるか優先順位を設定し、サーバー構成に合わせてトラフィックを形成することができます。 これにより、一部の要求の QoS は影響を受けますが、受信負荷は確実に処理できます。
関連項目
- Aron、Mohit および Sanders、Darren および Druschel、Peter および Zwaenepoel、Willy (2000)。 「クラスターベースのネットワーク サーバーでのスケーラブルなコンテンツ対応要求の分散」(2000 Annual USENIX technical Conference の議事録)