フォールトトレラント クラウド サービスを構築する
データセンターとクラウド サービスの管理の大部分は、信頼性の低いパーツに基づく信頼性の高いサービスの設計と保守に関係しています。 次の図は、新規採用者向けのトレーニングの一部です。この図を見れば、大規模なデータセンターで定期的に発生する多数の (そして多様な) 失敗がわかります。

図 2: トレーニング プレゼンテーションで示された信頼性の問題
システムの失敗は、失敗が原因でシステムに無効な状態が生じた結果として起こります。 通常、システムでは、次のいずれかの種類の障害が発生します。
- 一時的な障害: 時間の経過と共に自動的に解決するシステムの一時的な障害。
- 永続的な障害: 復旧できず、通常はリソースの交換が必要な障害。
- 断続的な障害: システムで定期的に発生する障害。
障害は、システム機能のサービスやパフォーマンスを低下させることで、システムの可用性に影響を与える可能性があります。 フォールトトレラント システムには、システムに失敗が発生した場合でも機能を実行する機能があります。 多くの場合、クラウドにおけるフォールトトレラント システムとは、サービス レベル アグリーメント (SLA) の許容限度よりも短いダウンタイムで、一貫した方法でサービスを提供するシステムと考えられています。
フォールト トレランスが重要な理由
大規模なミッションクリティカル システムで失敗が発生すると、関係するすべての関係者に重大な金銭的損失が発生する可能性があります。 クラウド コンピューティング システムには、階層型アーキテクチャを持つという特性があります。 そのため、クラウド リソースのあるレイヤーで障害が発生すると、他の上位のレイヤーで失敗がトリガーされたり、下位のレイヤーへのアクセスが非表示になったりする可能性があります。
たとえば、システムのいずれかのハードウェア コンポーネントで障害が発生すると、障害のあるリソースを使用する仮想マシン上で実行されている SaaS (サービスとしてのソフトウェア) アプリケーションの通常の実行に影響する可能性があります。 どのレイヤーで発生したとしても、システムの障害は各レベルのプロバイダー間の SLA と直接的な関係があります。
プロアクティブな対策
サービス プロバイダーは、特定の方法でシステムを設計して既知の問題や予測可能な失敗を回避するために、いくつかの対策を講じています。
プロファイリングとテスト
サービスの可用性を確保するには、考えられる失敗の原因を把握するためにクラウド リソースの負荷テストとストレス テストを行うことが不可欠です。 これらのメトリックをプロファイリングすると、予期しない動作が発生しない、想定された負荷に耐えられるシステムを設計する際に役立ちます。
オーバープロビジョニング
オーバープロビジョニングとは、ある時点のリソースの一般的な予想使用率を超えるボリュームでリソースをデプロイすることです。 システムの正確なニーズが必ずしも予測できない状況では、リソースのオーバープロビジョニングは予期しない負荷の急増に対応するために許容できる戦略です。
一例として、サーバーに平均して一貫した負荷がかかり、ホリデー シーズン中は負荷パターンが急上昇すると予想される eコマース プラットフォームを考えてみましょう。 このようなピーク時には、ピーク使用量の履歴データに基づいて追加のリソースをプロビジョニングすることをお勧めします。 通常、トラフィックの急激な増加に短期間で対応することは困難です。 後のセクションで説明するように、動的なスケーリングに関連する時間コストがあります。これには、負荷パターンの変化を検出し、新しい負荷に対応するために追加のリソースをプロビジョニングするという時間のかかる手順が含まれます。 このどちらの手順にも時間がかかります。 この調整の待機時間によって、システムが過負荷になる可能性が高く、最悪の場合はクラッシュし、よくてもシステムのサービス品質は低下します。
オーバープロビジョニングは、DoS (サービス拒否) 攻撃または DDoS (分散型 DoS) 攻撃に対して防御するために使用される戦術でもあります。これは、システム障害を発生させる目的で大量のトラフィックをスローすることで、システムを過負荷にするように設計された要求を攻撃者が生成する攻撃です。 どのような攻撃であっても、システムで検出して是正措置を講じるには常にある程度の時間がかかります。 このような要求パターンの分析が行われている間も、システムは既に攻撃を受けているため、軽減戦略を実装できるようになるまでは増加したトラフィックに対応できる必要があります。
レプリケーション
重要なシステム コンポーネントを複製するには、追加のハードウェアおよびソフトウェア コンポーネントを使用し、システム全体で障害が発生しないようにシステムの一部の失敗をサイレント モードで処理します。 レプリケーションには、次の 2 つの基本的な方法があります。
- アクティブなレプリケーション。レプリケートされたすべてのリソースが同時に動作し、すべての要求に対する応答と処理が行われます。 つまり、どのクライアント要求でも、すべてのリソースが同じ要求を受け取り、すべてのリソースが同じ要求に応答し、要求の順序によってすべてのリソースの状態が維持されます。
- パッシブ レプリケーション。要求を処理するのはプライマリ ユニットのみで、セカンダリ ユニットでは状態が維持され、プライマリ ユニットに障害が発生すると引き継がれます。 クライアントはプライマリ リソースとのみ接続され、すべてのセカンダリ リソースに状態の変更が中継されます。 パッシブ レプリケーションの欠点は、プライマリ インスタンスからセカンダリ インスタンスへの切り替え時に、要求がドロップされたり、QoS が低下したりする可能性があることです。
セミアクティブと呼ばれるハイブリッド戦略もあります。これはアクティブ戦略とよく似ています。 違いは、プライマリ リソースの出力のみがクライアントに公開されることです。 セカンダリ リソースの出力は抑制され、ログに記録されて、プライマリ リソースで失敗が発生するとすぐに切り替えることができます。 次の図は、レプリケーション戦略の違いを示しています。
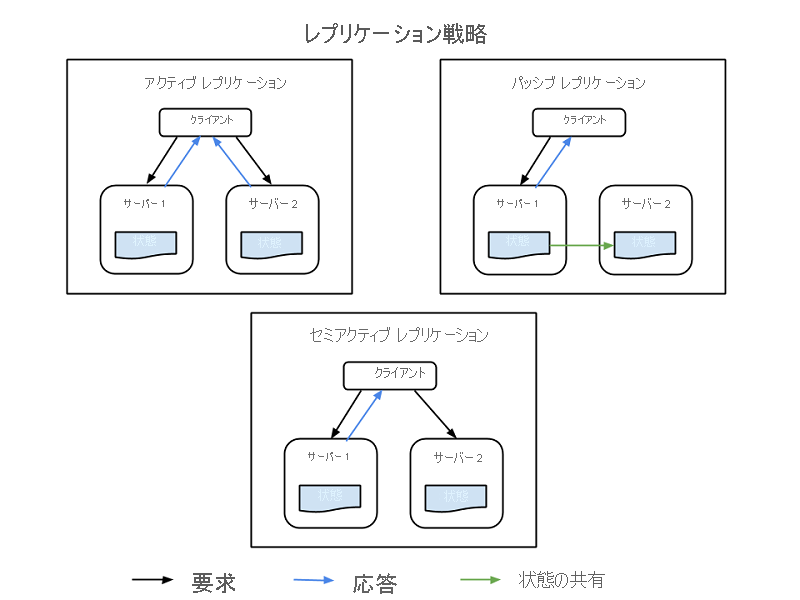
図 3: レプリケーション戦略
レプリケーションで考慮すべき重要な要素は、使用するセカンダリ リソースの数です。 これはシステムの重要性に基づいてアプリケーションごとに異なりますが、レプリケーションには 3 つの正式なレベルがあります。
- N+1: これは、基本的に、適切に機能するには N 個のノードが必要なアプリケーションの場合、1 つの追加リソースをフェールセーフとしてプロビジョニングすることを意味します。
- 2N: このレベルでは、通常の機能に必要なノードごとに 1 つの追加ノードをフェールセーフとしてプロビジョニングします。
- 2N+1: このレベルでは、通常の機能に必要なノードごとに 1 つの追加ノードと、全体で 1 つの追加ノードをフェールセーフとしてプロビジョニングします。
事後対策
予測的対策に加えて、システムで事後対策を講じて、失敗が発生したときに処理することができます。
確認と監視
予測できない動作やリソースの損失を確認するために、すべてのリソースが常時監視されます。 監視情報に基づいて、リソースの再起動や新しいリソースの起動のための回復または再構成の戦略が設計されています。 監視は、システムの障害を特定するために役立ちます。 サービスが使用できなくなる障害はクラッシュ障害と呼ばれ、システムの動作が不規則または不適切になる障害はビザンチン障害と呼ばれます。
システム内のクラッシュ障害を確認するために使用される監視戦術はいくつかあります。 次の 2 つの戦術があります。
- ping エコー: 監視サービスから各リソースにその状態が確認され、応答する時間枠が与えられます。
- ハートビート: トリガーなしで、各インスタンスから監視サービスに定期的に状態が送信されます。
通常、ビザンチン障害の監視は、提供されるサービスの特性によって変わります。 監視システムを使用すると、待機時間、CPU 使用率、メモリ使用率などの基本的なメトリックを確認し、予想値と照合して、サービスの品質が低下しているかどうかを確認できます。 さらに、通常、アプリケーション固有の監視ログは重要な各サービス実行ポイントに保持され、定期的に分析されて、サービスが常に適切に機能していること (またはシステムに挿入された失敗があるかどうか) が確認されます。
チェックポイントと再起動
クラウドの一部のプログラミング モデルでは、チェックポイント戦略が実装されています。これにより、最後に保存されたチェックポイントに復旧できるように、複数の実行段階で状態が保存されます。 データ分析アプリケーションには、情報を抽出するためにテラバイト単位のデータ セットに対して長時間実行される並列分散タスクがよくあります。 こうしたタスクはいくつかの小さな実行チャンクで実行されるため、プログラムの実行の各手順で、実行の全体的な状態をチェックポイントとして保存できます。 個々のノードが作業を完了できない失敗が発生した場合、前のチェックポイントから実行を再開できます。 ロールバックする有効なチェックポイントを特定する際の最大の課題は、並列プロセスが情報を共有している場合です。 いずれかのプロセスで失敗が発生すると、別のプロセスで連鎖的にロールバックが発生する可能性があります。そのプロセスで作成されたチェックポイントは、失敗したプロセスが共有するデータの障害の結果である可能性があるためです。 プログラミング モデルのフォールト トレランスについては、後のモジュールでさらに詳しく学習します。
回復性テストのケース スタディ
大規模な分散システムの単一のコンポーネントでは 100% の可用性または稼働時間を保証できないため、クラウド サービスは冗長性とフォールト トレランスを考慮して構築する必要があります。
すべての失敗 (同じノード、ラック、データセンター、またはリージョン的に冗長なデプロイでの依存関係の失敗を含む) は、システム全体に影響を与えることなく適切に処理する必要があります。 致命的な失敗を処理するシステムの能力をテストすることは重要です。数秒のダウンタイムやサービスの低下であっても、数百万ドルまではないにしても数十万ドル規模の収益損失を引き起こす可能性があるためです。
システムが強化され、計画外の停止が発生した場合に対処できるように、実際のトラフィックによる失敗のテストを定期的に行う必要があります。 回復性をテストするために構築されたさまざまなシステムがあります。 このようなテスト スイートの 1 つとして、Netflix が構築した Simian Army があります。
Simian Army は、さまざまな種類の失敗を生成し、異常な状態を検出し、それらに耐えるシステムの能力をテストするためのクラウド内のサービス (モンキーと呼ばれます) で構成されます。 その目標は、クラウドの安全性、セキュリティ、高可用性を維持することです。 Simian Army には次のようなモンキーがあります。
- Chaos Monkey: 運用インスタンスをランダムに選択して無効にし、顧客に影響を与えることなくクラウドが一般的な種類の失敗に耐えられるようにするツールです。 Netflix は、Chaos Monkey のことを "データセンター (またはクラウド リージョン) に武器を持った野生の猿を解き放ってランダムにインスタンスを撃たせ、ケーブルを噛み切らせながら、中断なくお客様にサービスを提供し続けるという考え方" であると説明しています。詳細な監視を伴うこの種のテストでは、システムのさまざまな弱点が明らかになります。また、その結果に基づいて自動復旧戦略を構築できます。
- Latency Monkey: さまざまなクライアントとサーバーの RESTful 通信の間で待機時間を誘発し、サービスの低下とダウンタイムをシミュレートするサービスです。
- Doctor Monkey: 異常な動作を示すインスタンス (CPU 負荷など) を検出してサービスから削除するサービスです。 サービス所有者はこれを使用して問題の理由を特定し、最終的にインスタンスを終了させることができます。
- Chaos Gorilla: AWS 可用性ゾーン全体の損失をシミュレートできるサービスです。 これを使用すると、ユーザーの目に見える影響や手動の介入なしで、サービスによって残りのゾーン間で機能を自動的に再調整することをテストできます。