データを分類する
オンライン小売り業では、さまざまな種類のデータがあります。 メリットのあるストレージ ソリューションは、データの種類ごとに異なる可能性があります。
アプリケーション データは、構造化、半構造化、および非構造化の 3 つの方法のいずれかに分類できます。 ここでは、データの種類に適したストレージ ソリューションを選択できるように、データを分類する方法について学習します。
クラウドにデータを格納する方法
次のビデオでは、データをクラウドに保存するためのオプションを紹介しています。
構造化データ
構造化データは "リレーショナル データ" とも呼ばれ、すべてのデータはフィールドまたはプロパティが同じです。 すべてのデータは編成と形状 (すなわち "スキーマ") が同じです。 共有スキーマを使用すると、構造化照会言語 (SQL) などのクエリ言語を使用してこの種のデータを簡単に検索できます。 この機能があるので、このデータ スタイルは、CRM システム、予約、在庫管理などのアプリケーションに最適です。
多くの場合、構造化データは、行と列を含むデータベース テーブルに保存されます。 テーブル内のキー列は、テーブル内のある行と、別のテーブルの別の行のデータの関係を示します。 次の図では、成績に関するデータを含むテーブルは、キー列を使用して、学生名のテーブルとクラス データのテーブルからデータを取得しています。
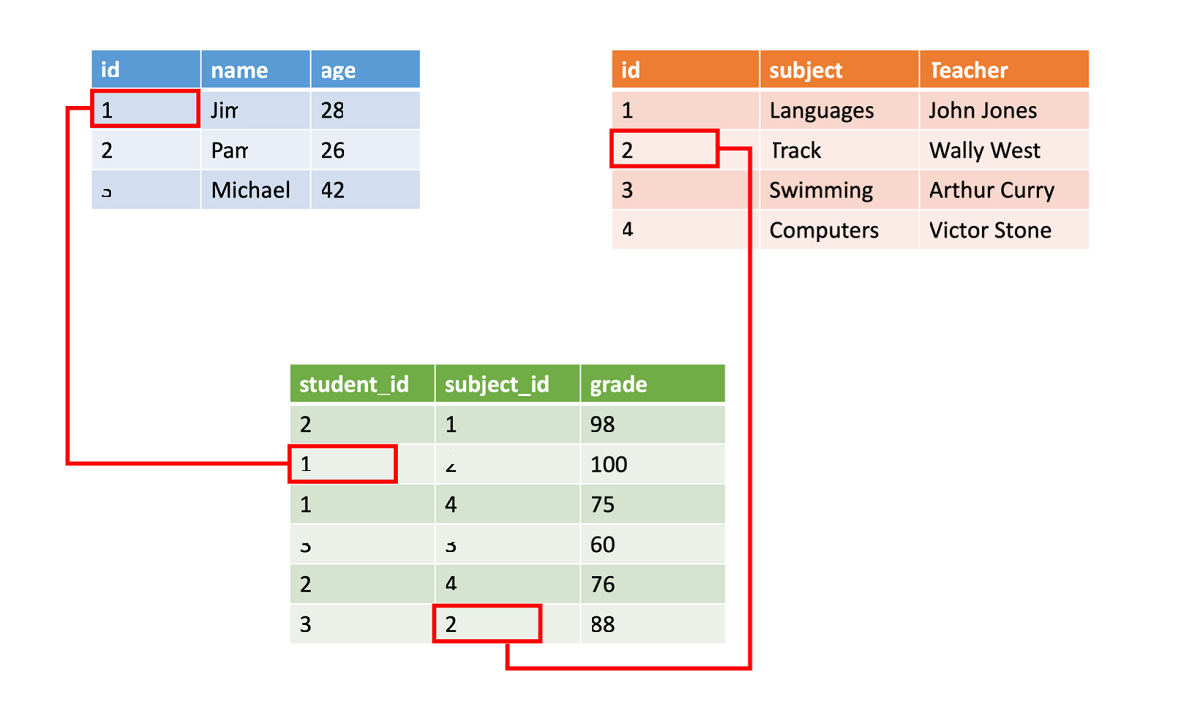
構造化データは、入力、クエリ、分析が簡単であるという点で単純です。 すべてのデータは同じ形式です。 ただし、一貫性のある構造を強制することは、データの進化がより難しくなることも意味します。 データ フィールドを追加または削除する場合、新しい構造に準拠するために、各レコードを更新する必要があります。
半構造化データ
半構造化データは構造化データよりも整理されておらず、 フィールドがテーブル、行、列にきちんと収まらないため、リレーショナル形式で保存されていません。 半構造化データには、データの編成と階層を明らかにするタグが含まれています。 一例として、キーと値のペアがあります。 半構造化データは、非リレーショナル データまたは not only SQL (NoSQL) データとも呼ばれます。
データ シリアル化言語によって半構造化データが定義されます。 データ分類では、"シリアル化" は、データを送信または保存できる形式に変換するプロセスです。
ソフトウェア開発者は、データ シリアル化言語を使用して、メモリに格納されているデータをファイルに書き込み、別のシステムに送信したり、解析したり、読み取ったりすることができます。 送信者と受信者は、他のシステムのことを詳しく知る必要はありません。 両方のシステムが同じシリアル化言語を使用していれば、そのデータを理解できます。
一般的なシリアル化言語
3 つの一般的なシリアル化言語は、XML、JSON、YAML です。
XML
"拡張マークアップ言語 (XML)" は、広く使用される最初のデータ言語の 1 つでした。 XML はテキストベースであるため、人間もコンピューターも簡単に読むことができます。 XML パーサーは、ほとんどすべての一般的な開発プラットフォームで使用できます。
XML を使用して、リレーションシップを表現することができます。 XML には、スキーマ、変換、Web での表示に関する標準があります。
ある人物の名前、年齢、趣味を XML で表現した例を次に示します。
<Person Age="23">
<FirstName>Quinn</FirstName>
<LastName>Anderson</LastName>
<Hobbies>
<Hobby Type="Sports">Golf</Hobby>
<Hobby Type="Leisure">Reading</Hobby>
<Hobby Type="Leisure">Guitar</Hobby>
</Hobbies>
</Person>
XML では、山かっこで囲んで定義される "タグ" を使用して、データの形状を表します。 タグには、<FirstName> などの "要素" と、Age="23" のようにテキストで表現できる "属性" の 2 つの形式があります。 要素に子要素を含めて、リレーションシップを表すことができます。 たとえば、<Hobbies> タグは、Hobby 要素のコレクションを表します。
XML は柔軟性があり、複雑なデータを簡単に表現できます。 ただし、ネットワーク経由で格納、処理、または受け渡しを行うため、より冗長になり、格納するサイズが大きくなる傾向があります。 その結果、他の形式の方が人気が高まっています。
JSON
JavaScript Object Notation (JSON) は仕様が軽量で、データ構造を示すために中かっこが使用されます。 XML と比べて、JSON はそれほど冗長ではなく、人間にとって読みやすい言語です。 JSON は、Web サービスでデータを返すために頻繁に使用されます。
先ほどと同じ人物の名前、年齢、趣味を JSON で表した例を次に示します。
{
"firstName": "Quinn",
"lastName": "Anderson",
"age": "23",
"hobbies": [
{ "type": "Sports", "value": "Golf" },
{ "type": "Leisure", "value": "Reading" },
{ "type": "Leisure", "value": "Guitar" }
]
}
JSON 形式は、XML ほど形式的ではありません。 形式的なデータ表現よりもキーと値のペア モデルに近い言語です。 名前から推測できるように、JavaScript プログラミング言語には、この形式のサポートが組み込まれているため、Web 開発では一般的です。 XML と同様に、他の言語には、そのデータ形式を操作するために使用できるパーサーがあります。 JSON の欠点は、プログラマー指向になる傾向があり、テクノロジに詳しくない場合は読み取りや変更が困難になることです。
YAML
YAML Ain't Markup Language (YAML) は、さらに開発年代の新しいデータ シリアル化言語です。 YAML を使用する利点の 1 つは、人間にとって他の一部の言語よりも読みやすいことです。 行の分離とインデントによってデータ構造が定義されます。 YAML 形式を使用すると、かっこ、コンマ、角かっこなどの構造的な文字への依存が少なくなります。
先ほどと同じデータを YAML で表した例を次に示す。
firstName: Quinn
lastName: Anderson
age: 23
hobbies:
- type: Sports
value: Golf
- type: Leisure
value: Reading
- type: Leisure
value: Guitar
この形式は、読みやすさの点で JSON を上回ります。 人間が書いた構成ファイルをプログラムで解析するという場合に、一般的に使用されています。 YAML は、これらのデータ形式の中で最も新しい形式です。
構成ファイルを書くのは人間であるけれども解析するのはプログラムであるという場合に、よく使用されています。
半構造化データまたは NoSQL データとは
次のビデオでは、半構造化データおよび NoSQL データの格納オプションについて説明します。
非構造化データ
非構造化データの編成は未定義です。 多くの場合、非構造化データは、写真やビデオ ファイルなどのファイル形式で提供されます。 ビデオ ファイル自体は全体的な構造を持ち、半構造化メタデータを含む場合がありますが、ビデオ自体を形成するデータは非構造化です。 写真やビデオおよび他の類似ファイルは非構造化データとして分類されます。
非構造化データには次のような例があります。
- メディア ファイル (写真、ビデオ、オーディオ ファイルなど)。
- Microsoft 365 ファイル (Word 文書など)。
- テキスト ファイル。
- ログ ファイル。
データ分類: データ型を評価する
データは、構造化、半構造化、非構造化の 3 つの方法のいずれかに分類できます。 これらの違いを理解してお使いのデータを分類できるようになると、適切な格納ソリューションの選択に役立ちます。
構造化データは、データのテーブルまたは列にきちんと収まるように編成されたデータです。 半構造化データは、引き続き編成されており、明確なプロパティと値を持ちますが、データに多様性があります。 非構造化データは、テーブルまたは列にきちんと収まらないため、スキーマが統一されていません。
オンライン小売りビジネスで使用されるデータセットを調べて分類してみましょう。
製品カタログ データ
オンライン小売りビジネスの製品カタログ データは、本質的に半構造化です。 各製品には、製品 SKU、説明、数量、価格、サイズ オプション、色のオプション、写真、場合によってはビデオが含まれています。 最初のうちは、すべてが同じ構造を持っているため、このデータはリレーショナルであるように見えます。 しかし、新製品または異なる種類の製品が発表されると、データ フィールドを追加することが必要になる可能性があります。 たとえば、新たに掲載するテニス シューズは Bluetooth 対応で、センサー データを靴からユーザーのスマートフォンのフィットネス アプリに中継できます。 この機能は成長路線にあると思われるため、あなたは顧客が "Bluetooth 対応" のシューズでフィルター処理するためのオプションを提供したいと考えています。 既存のすべてのシューズ データを Bluetooth 対応プロパティで更新せずに、 この新しいプロパティを新しいシューズにのみ追加したいと考えています。
Bluetooth 対応プロパティを追加すると、シューズ データは同種ではなくなります。 スキーマに違いを取り入れました。 発生する例外はこの変更だけであると考えられる場合は、構造化されたリレーショナル編成を維持するために、すべての製品に "Bluetooth 対応" フィールドが含まれるように、既存のデータを正規化することができます。 ただし、これが将来的にサポートすることを想定している多くの特別なフィールドの 1 つに過ぎない場合は、データの分類は半構造化です。 タグによってデータが整理されますが、カタログ内の各商品に固有のフィールドを持たせることができます。
製品カタログ データの分類は、"半構造化" です。
写真とビデオ
製品ページに表示される写真やビデオは、非構造化データです。 メディア ファイルはメタデータを含む場合がありますが、メディア ファイルの本体は非構造化です。
写真およびビデオのデータ分類は、"非構造化" です。
ビジネス データ
ビジネス アナリストは、ビジネス インテリジェンスを実装して、在庫パイプライン評価と売上データ レビューを実行しようと考えています。 これらの操作を実行するには、複数の月のデータを集計してから、クエリを実行する必要があります。 同様のデータを集計する必要があるため、ある月を次の月と比較できるようにこのデータを構造化する必要があります。
ビジネス データの分類は、"構造化" です。