Power BI モデルの基本について説明する
このユニットでは、Power BI モデルの用語を紹介します。 ご自身のプロジェクトに適したモデル フレームワークを選択するには、これらの用語を理解しておくことが重要です。 このユニットでは、次の用語について説明します。
- データ モデル
- Power BI データセット
- 分析クエリ
- テーブル モデル
- スター スキーマの設計
- テーブル ストレージ モード
- モデル フレームワーク
データ モデル
Power BI データ モデルは、分析用に最適化されたクエリ可能なデータ リソースです。 レポートでは、Data Analysis Expressions (DAX) または多次元式 (MDX) という、2 つの分析言語のいずれかを使用してデータ モデルに対するクエリを実行できます。 Power BI では DAX を使用しますが、改ページ対応レポートでは DAX または MDX を使用できます。 Excel で分析機能では、MDX を使用します。
ヒント
データ モデルは、(特にエンタープライズ シナリオでは) セマンティック モデルとも呼ばれます。 一般に、データに関する議論のコンテキストやこのモジュールでは、データ モデルは単にモデルと呼ばれます。
Power BI データセット
Power BI Desktop で Power BI モデルを開発し、Power BI サービスのワークスペースに発行すると、それはデータセットと呼ばれます。 データセットは、Power BI レポートとダッシュボードの視覚化のためのデータ ソースである Power BI 成果物です。
注意
すべてのデータセットが Power BI Desktop で開発されたモデルから生成されるわけではありません。 データセットは、AAS または SSAS の外部ホスト型モデルへの接続を表す場合があります。 プッシュ データセット、ストリーミング データセット、ハイブリッド データセットなどのリアルタイム データ構造を表す場合もあります。 このモジュールでは、Power BI Desktop で開発されたモデルのみを扱います。
分析クエリ
Power BI レポートとダッシュボードは、データセットに対してクエリを実行する必要があります。 Power BI でデータセットのデータが視覚化される際に、分析クエリが準備されて送信されます。 分析クエリによって、(特に視覚化された場合に) ユーザーが理解しやすいクエリ結果がモデルから生成されます。
分析クエリには、次の順序で実行される 3 つのフェーズがあります。
- フィルター処理
- グループ化
- 集計
フィルター処理 (スライスとも呼ばれます) により、モデル データのサブセットに絞り込まれます。 フィルター値はクエリ結果に表示されません。 ほとんどの分析クエリではフィルターが適用されます。ある期間と、通常は他の属性でフィルター処理するのが一般的だからです。 フィルター処理はさまざまな方法で行われます。 Power BI レポートでは、レポート、ページ、または視覚化レベルでフィルターを設定できます。 多くの場合、レポートのレイアウトには、レポート ページ上の視覚化をフィルター処理するためのスライサー視覚エフェクトが含まれます。 モデルで行レベルのセキュリティ (RLS) が適用されると、モデル テーブルにフィルターが適用され、特定のデータへのアクセスが制限されます。 モデル データを集計するメジャーでも、フィルターを適用することができます。
グループ化 (ダイスとも呼ばれます) では、クエリ結果をグループに分割します。 各グループもまたフィルターですが、フィルター処理フェーズとは異なり、フィルター値はクエリ結果に表示されます。 たとえば、顧客別にグループ化すると、各グループが顧客別にフィルター処理されます。
集計では、単一値の結果が生成されます。 通常、レポートの視覚化では集計関数を使用して数値フィールドを集計します。 集計関数には、合計、カウント、最小値、最大値などがあります。 列を集計してシンプルな集計を行ったり、DAX 数式を使ってメジャーを作成することで複雑な集計を行ったりできます。
1 つ例を考えてみましょう。Power BI レポート ページに、ある 1 年間でフィルター処理するスライサーが含まれています。 また、フィルター処理された年の四半期売上を示す縦棒グラフの視覚エフェクトもあります。
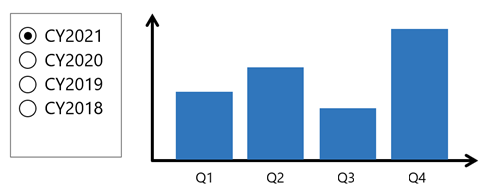
この例では、スライサーによって、2021 という暦年で視覚エフェクトがフィルター処理されます。 縦棒グラフでは、(フィルター処理された年の) 四半期ごとにグループ化されます。 各縦棒が、表示されるフィルターを表すグループです。 縦棒の高さは、フィルター処理された年の四半期ごとの集計された売上の値を表します。
テーブル モデル
Power BI モデルは表形式モデルです。 表形式モデルは、1 つ以上の列のテーブルで構成されます。 リレーションシップ、階層、計算を含めることもできます。
スター スキーマの設計
最適化された使いやすい表形式モデルを生成するには、スター スキーマ設計を生成することをお勧めします。 スター スキーマ設計は、リレーショナル データ ウェアハウスで広く採用されている成熟したモデリング手法です。 モデル テーブルをディメンションまたはファクトとして分類する必要があります。
ディメンション テーブルでは、ビジネス エンティティ (モデル化の対象) について説明します。 エンティティには、時間自体を含め、製品、人、場所および概念を含めることができます。 ファクト テーブルには観測値やイベントが格納されます。たとえば、販売注文、在庫量、為替レート、気温の測定値などです。 ファクト テーブルには、ディメンション テーブルに関連するディメンション キー列と、数値メジャー列が含まれています。 ファクト テーブルが星の中心を形成し、関連するディメンション テーブルはその星の点を形成します。
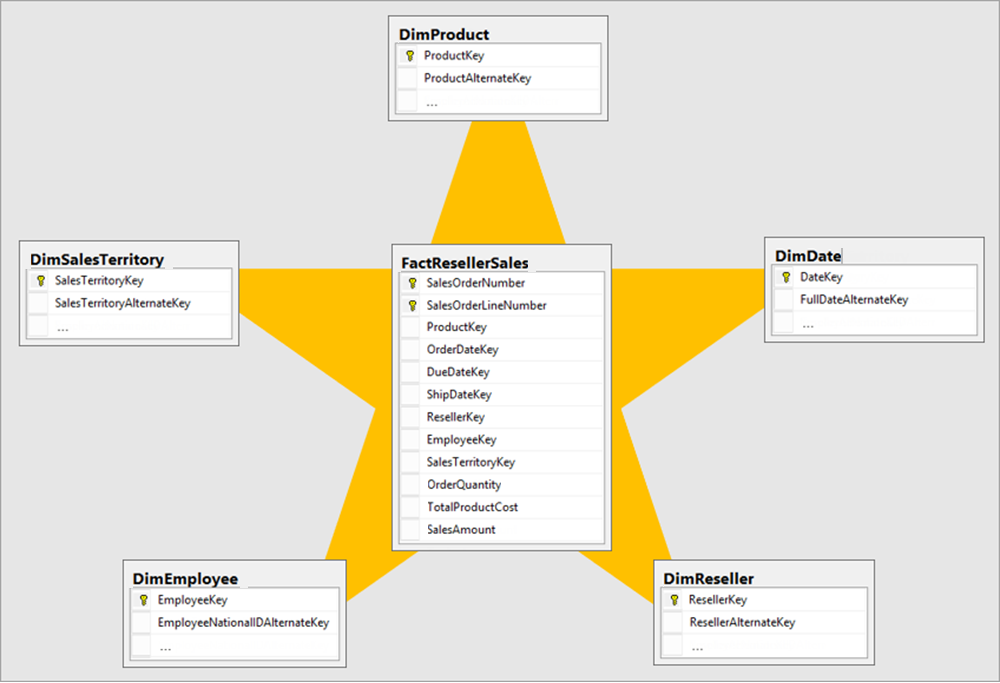
分析クエリでは、ディメンション テーブルの列はフィルター処理またはグループ化されます。 ファクト テーブルの列は集計されます。
詳細については、「スター スキーマと Power BI での重要性を理解する」を参照してください。
テーブル ストレージ モード
それぞれの Power BI モデル テーブル (計算テーブルを除く) には、ストレージ モード プロパティがあります。 ストレージ モード プロパティには Import、DirectQuery、Dual のいずれかを指定でき、それによってテーブル データをモデルに格納するかどうかが決定されます。
- Import – クエリは、モデルに格納 (またはキャッシュ) されているデータを取得します。
- DirectQuery – クエリはデータ ソースにパススルーされます。
- Dual – クエリは格納されたデータを取得するか、データ ソースにパススルーされます。 Power BI によって最も効率的な計画が判断されます。可能な場合は常にキャッシュされたデータを使用しようとします。
モデル フレームワーク
テーブルのストレージ モード設定によってモデル フレームワークが決定されます。それはインポート、DirectQuery、または複合のいずれかです。 このモジュールの後続のユニットでは、これらの各フレームワークについて説明し、その使用方法に関するガイダンスを提供します。
- インポート モデルは、ストレージ モード プロパティが Import に設定されているテーブルで構成されます。
- DirectQuery モデルは、ストレージ モード プロパティが DirectQuery に設定されているテーブルで構成され、それらは同じソース グループに属しています。 ソース グループについては、このモジュールで後ほど説明します。
- 複合モデルは、複数のソース グループで構成されます。