はじめに
言語モデルは、ユーザーの質問に対して一貫性のある優れた回答が作成されることから人気が高まっています。 特に、ユーザーがチャットで言語モデルを使用すると、必要な情報を直感的に取得することができます。
チャットで言語モデルを実装する際の一般的な課題の 1 つが、いわゆるグラウンディングです。これは、応答が現実または特定のコンテキストに根ざしているか、結びついているか、あるいは裏付けられているかを指すものです。 つまり、グラウンディングとは、言語モデルの応答が事実に基づいているかどうかを意味します。
グラウンディングされていないプロンプトと応答
言語モデルを使ってプロンプトへの応答を生成する場合、応答を生成するためにモデルが利用できる情報は、それがトレーニングされたデータの情報しかありません。多くの場合、それはインターネットやその他のソースから取得された、コンテキストのない大量のテキストに過ぎません。
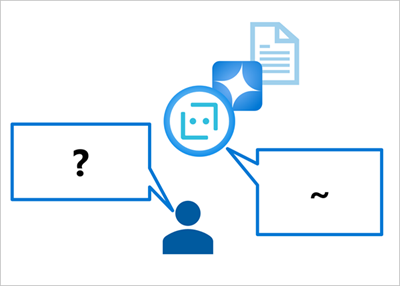
プロンプトに対して、おそらく文法的に正しく、論理的な応答が生成されますが、プロンプトが関連する事実のデータにグラウンディングされていないため、コンテキストに沿わないものになります。それどころか、不正確な情報や "捏造された" 情報が含まれるおそれもあります。 たとえば、「X を行うためにはどの製品を使用すればよいですか?」という質問には、架空の製品の詳細が含まれる可能性があります。
グラウンディングされているプロンプトと応答
それに対し、データ ソースを使って、関連する事実のコンテキストでプロンプトを "グラウンディング" することができます。 その後、(グラウンディング データを含めて) プロンプトを言語モデルに送信し、コンテキストに沿った関連性のある正確な応答を生成できます。
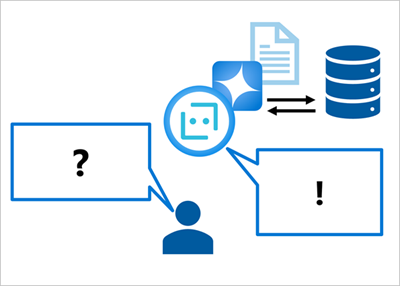
データ ソースには、関連するデータの任意のリポジトリを使用できます。 たとえば、製品カタログ データベースのデータを使って「X を行うためにはどの製品を使用すればよいですか?」というプロンプトをグラウンディングし、カタログ内に存在している製品に関連する詳細を応答に含めることができます。
このモジュールでは、独自のデータを使用してコパイロットを構築することで、グラウンディングされた独自のチャットベースの言語モデル アプリケーションを作成する方法について説明します。