演習 - ワークロードのパフォーマンスをスケーリングする
この演習では、Azure SQL Database に対してより多くの CPU をスケーリングすることで、最初の演習で発生した問題を解決し、パフォーマンスを向上させます。 前の演習でデプロイしたデータベースを使用します。
この演習のすべてのスクリプトは、クローンした GitHub リポジトリまたはダウンロードした ZIP ファイルの 04-Performance\monitor_and_scale フォルダーにあります。
Azure SQL のパフォーマンスのスケールアップ
CPU 容量に原因があると思われる問題に対してパフォーマンスをスケーリングするには、オプションを決定し、Azure SQL 用に提供されているインターフェイスを使用して CPU のスケーリングを進める必要があります。
パフォーマンスのスケーリング方法を決定します。 ワークロードが CPU "バウンド" になっているため、パフォーマンスを向上させる方法の 1 つとして、CPU の容量を増やす、または速度を上げる方法があります。 SQL Server のユーザーは、別のコンピューターに移行するか、VM を再構成して CPU 容量を増やす必要があります。 場合によっては、SQL Server 管理者でも、これらのスケーリング変更を行うためのアクセス許可を持っていない可能性があります。 プロセスに時間がかかったり、データベースの移行も必要になったりする場合があります。
Azure では、
ALTER DATABASE、Azure CLI、または Azure portal を使用して、ユーザーの側でデータベースを移行せずに CPU 容量を増やすことができます。Azure portal を使用すると、CPU リソースを増やすためのスケーリング方法のオプションを確認できます。 データベースの [概要] ペインで、現在のデプロイの [価格レベル] を選択します。 [価格レベル] では、サービス レベルと仮想コアの数を変更できます。
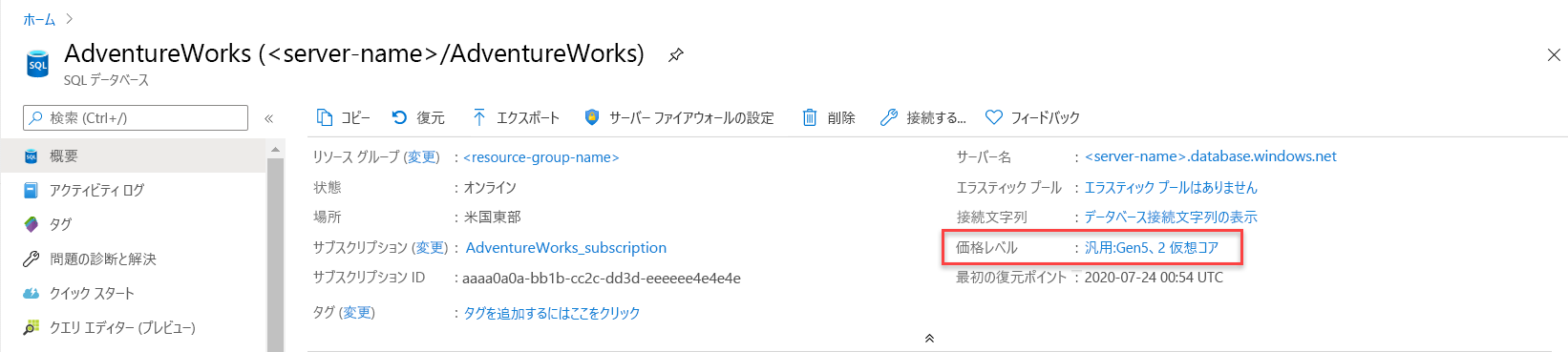
ここでは、コンピューティング リソースを変更またはスケーリングするためのオプションを確認できます。 General Purpose では、8 個の仮想コアなどに簡単にスケールアップできます。
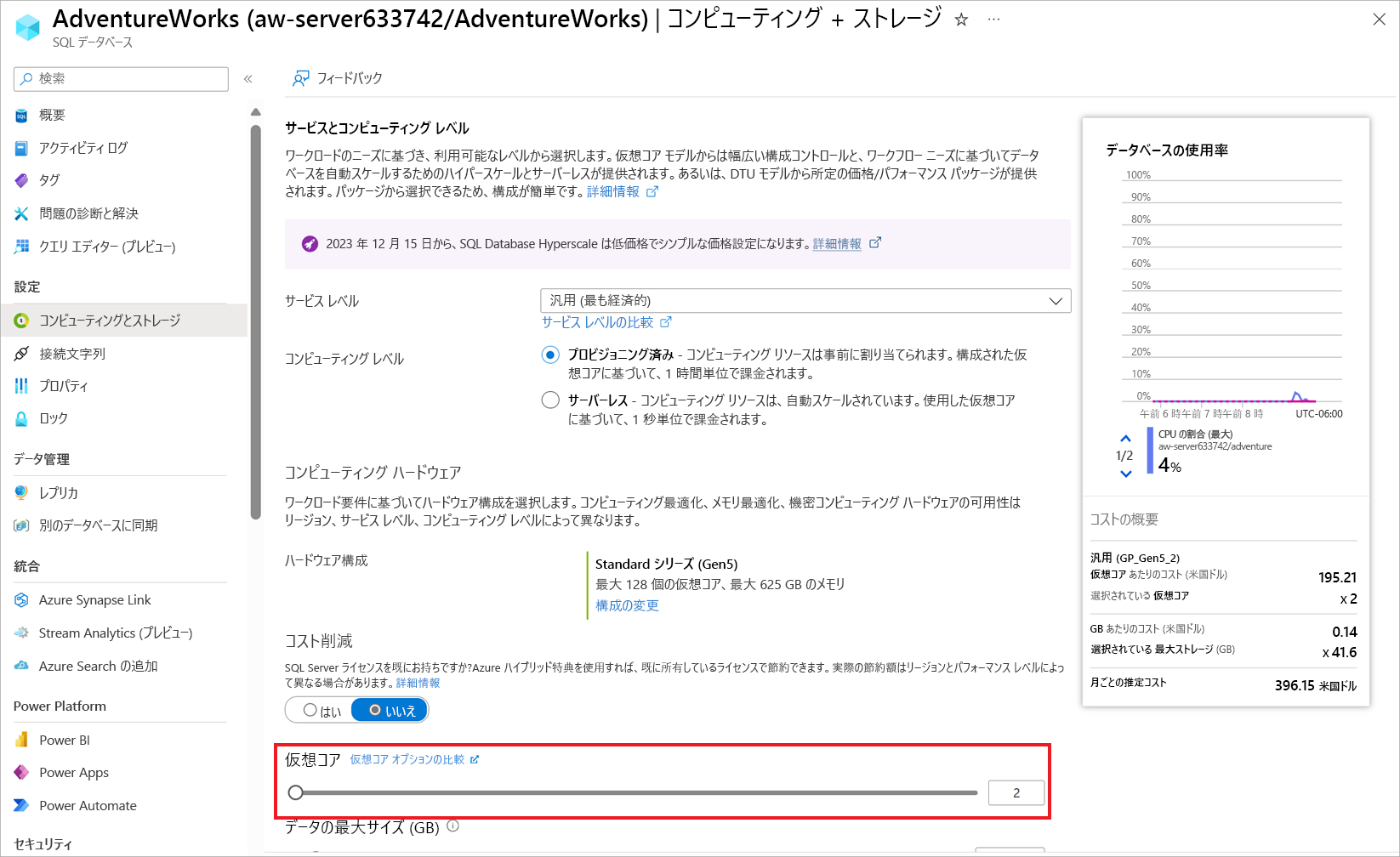
別の方法を使用してワークロードをスケーリングすることもできます。
この演習では、レポートで適切な違いを確認できるように、まずクエリ ストアをフラッシュする必要があります。 SQL Server Management Studio (SSMS) で [AdventureWorks] データベースを選択し、[ファイル]>[開く]>[ファイル] メニューを使用します。 AdventureWorks データベースのコンテキストで、SSMS で flushhquerystore.sql スクリプトを開きます。 クエリ エディター ウィンドウは、次のテキストのようになるはずです。
EXEC sp_query_store_flush_db;[実行] を選択して、この T-SQL バッチを実行します。
Note
上記のクエリを実行すると、クエリ ストア データのインメモリ分がディスクにフラッシュされます。
SSMS でスクリプト get_service_objective.sql を開きます。 クエリ エディター ウィンドウは、次のテキストのようになるはずです。
SELECT database_name,slo_name,cpu_limit,max_db_memory, max_db_max_size_in_mb, primary_max_log_rate,primary_group_max_io, volume_local_iops,volume_pfs_iops FROM sys.dm_user_db_resource_governance; GO SELECT DATABASEPROPERTYEX('AdventureWorks', 'ServiceObjective'); GOこれは、T-SQL を使用してサービス レベルを検索する方法です。 価格レベルまたはサービス レベルは、"サービス目標" とも呼ばれます。 [実行] を選択して T-SQL バッチを実行します。
現在の Azure SQL Database デプロイでは、結果は次の図のようになります。
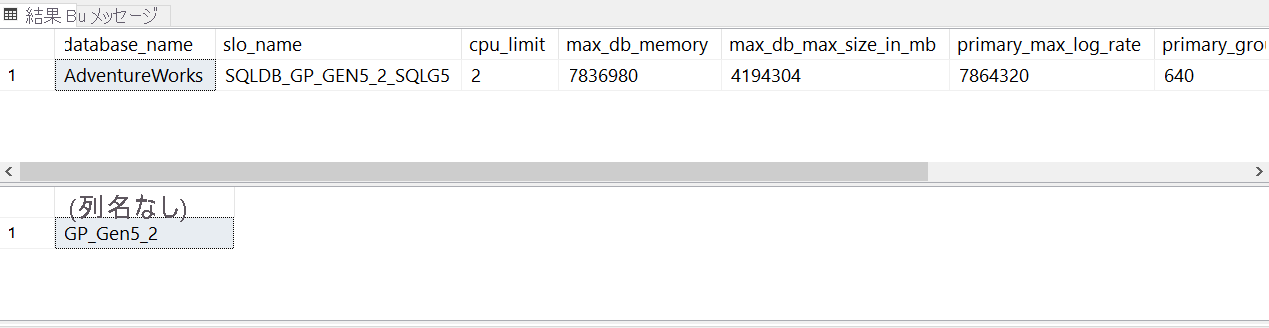
サービス目標に slo_name という用語が使用されていることに注目してください。 slo は、"サービス レベル目標" の略です。
さまざまな
slo_name値は記載されていませんが、文字列値から、このデータベースでは 2 個の仮想コアを持つ General Purpose サービス レベルが使用されていることがわかります。Note
SQLDB_OP_...は、Business Critical に使用される文字列です。ALTER DATABASE ドキュメントを表示して、ターゲット SQL Server デプロイを選択すると、適切な構文オプションを取得できることを確認してください。 [SQL Database single database/elastic pool](SQL Database 単一データベース/エラスティック プール) を選択して、Azure SQL Database のオプションを表示します。 ポータルで見つかったコンピューティング スケールと一致させるには、サービス目標
'GP_Gen5_8'が必要です。データベースのサービス目標を変更して、より多くの CPU をスケーリングします。 SSMS で modify_service_objective.sql スクリプトを開き、T-SQL バッチを実行します。 クエリ エディター ウィンドウは、次のテキストのようになるはずです。
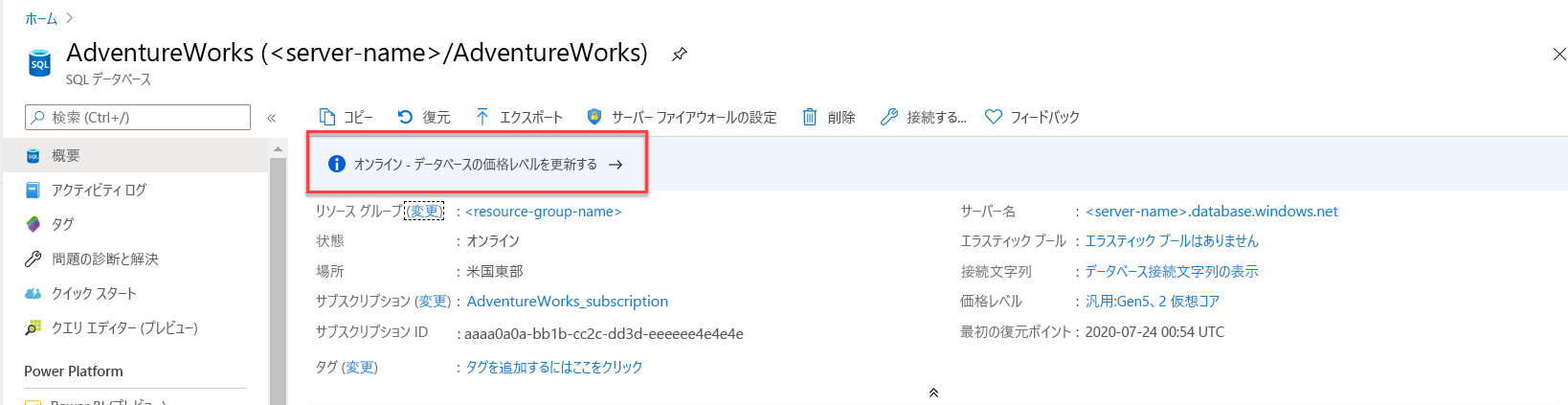
ALTER DATABASE AdventureWorks MODIFY (SERVICE_OBJECTIVE = 'GP_Gen5_8');このステートメントは即座に返されますが、コンピューティング リソースのスケーリングはバックグラウンドで行われます。 この小規模なスケーリングには 1 分もかかりませんが、変更を有効にするために、データベースが短時間オフラインになります。 このスケーリング アクティビティの進行状況は、Azure portal を使用して監視することができます。
オブジェクト エクスプローラーで、[システム データベース] フォルダーの下の master データベースを右クリックし、[新しいクエリ] を選択します。 SSMS クエリ エディター ウィンドウで、次のクエリを実行します。
SELECT * FROM sys.dm_operation_status;これは、Azure SQL Database のサービス目標に対する変更の進行状況を監視するもう 1 つの方法です。 この動的管理ビュー (DMV) では、ALTER DATABASE でデータベースに加えられた変更の履歴をサービス目標に公開し、 変更のアクティブな進行状況を表示します。
上記の ALTER DATABASE ステートメントを実行した後に表示される、この DMV の出力例を表形式で次に示します。
項目 値 session_activity_id 97F9474C-0334-4FC5-BFD5-337CDD1F9A21 resource_type 0 resource_type_desc データベース major_resource_id AdventureWorks minor_resource_id 操作 ALTER DATABASE 状態 1 state_desc InProgress percent_complete 0 error_code 0 error_desc error_severity 0 error_state 0 start_time [日付と時刻] LastModifyTime [日付と時刻] サービス目標の変更中は、最終的な変更が実装されるまで、データベースに対してクエリを実行できます。 アプリケーションが接続できない時間は、非常に短時間です。 Azure SQL Managed Instance では、レベルの変更中、クエリの実行と接続はできますが、データベースの新規作成などのデータベース操作はすべて実行できません。 このような場合、次のメッセージが表示されます。"The operation could not be completed because a service tier change is in progress for managed instance '[server]'. (マネージド インスタンス '[サーバー]' のサービス レベル変更が進行中のため、操作を完了できませんでした。) Please wait for the operation in progress to complete and try again." (進行中の操作が完了するまでしばらく待ってから、やり直してください。)
この処理が完了したら、SSMS の get_service_objective.sql にリストされている上記のクエリを使用して、8 個の仮想コアの新しいサービス目標またはサービス レベルが有効になっていることを確認します。
スケールアップ後にワークロードを実行する
データベースの CPU 容量が増えたので、前の演習で実行したワークロードを実行して、パフォーマンスが向上しているかどうかを確認してみましょう。
スケーリングが完了したので、ワークロードの実行時間が短くなり、CPU リソースの待機時間が短くなったかどうかを確認します。 前の演習で実行した sqlworkload.cmd コマンドを使用して、ワークロードを再度実行します。
SSMS を使用して、このモジュールの最初の演習と同じクエリを実行し、スクリプト dmdbresourcestats.sql の結果を観察します。
SELECT * FROM sys.dm_db_resource_stats;前の演習ではほぼ 100% だった CPU リソースの平均使用率が低下していることがわかります。 通常、
sys.dm_db_resource_statsで 1 時間分のアクティビティが表示されます。 データベースのサイズを変更すると、sys.dm_db_resource_statsがリセットされます。SSMS を使用して、このモジュールの最初の演習と同じクエリを実行し、スクリプト dmexecrequests.sql の結果を観察します。
SELECT er.session_id, er.status, er.command, er.wait_type, er.last_wait_type, er.wait_resource, er.wait_time FROM sys.dm_exec_requests er INNER JOIN sys.dm_exec_sessions es ON er.session_id = es.session_id AND es.is_user_process = 1;RUNNING 状態のクエリが増えたことがわかります。 これは、ワーカーで実行できる CPU 容量が増えていることを意味します。
新しいワークロードの実行時間について観察します。 sqlworkload.cmd から得られるワークロードの実行時間は、はるかに短くなり、約 25 から 30 秒になりました。
クエリ ストア レポートの観察
前の演習で行ったのと同じクエリ ストア レポートを見てみましょう。
このモジュールの最初の演習と同じ手法を使用して、SSMS からのレポート [Top Resource Consuming Queries] (リソースを消費する上位のリソース) を見てみましょう。
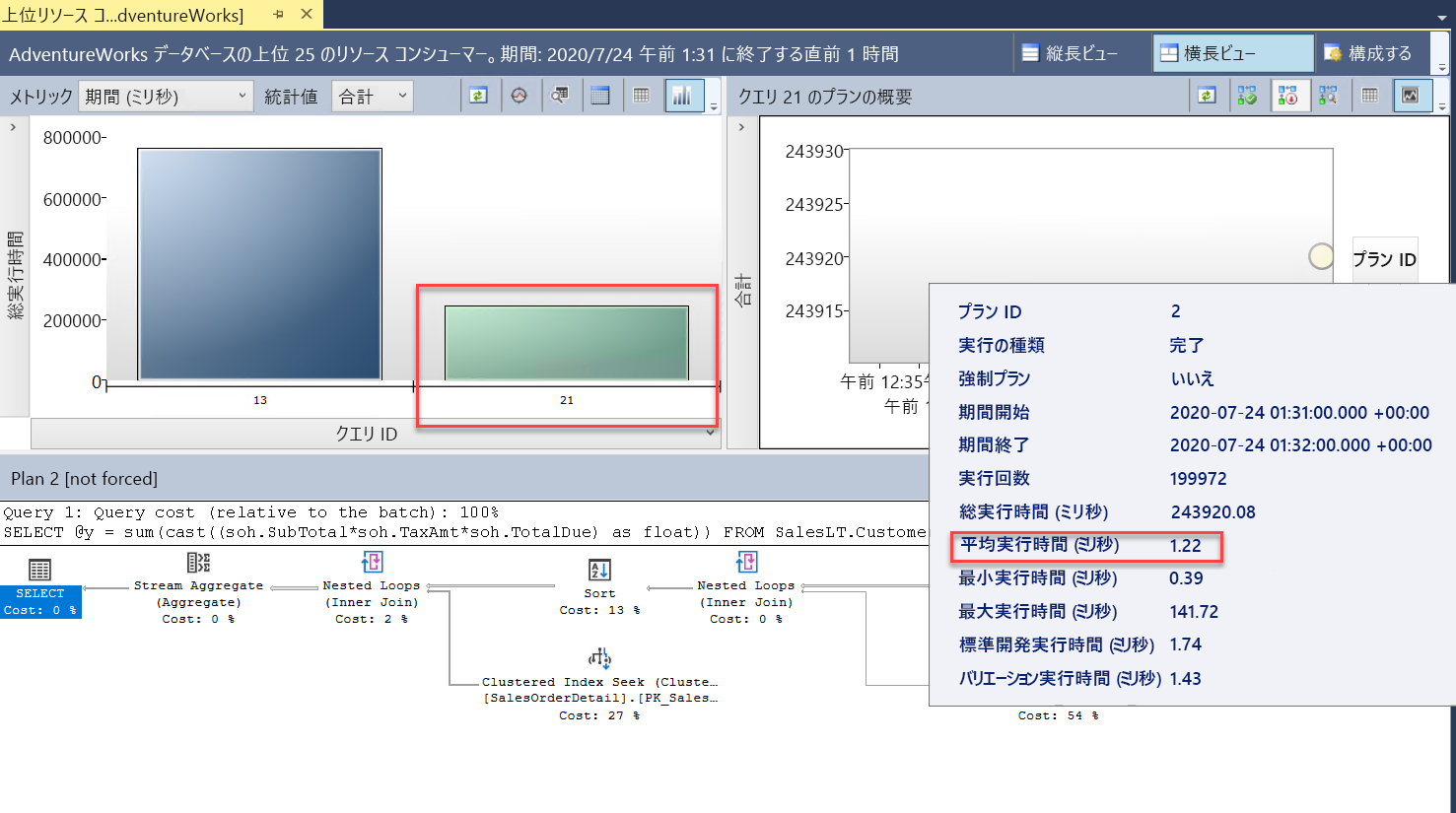
2 つのクエリ (
query_id) が表示されるようになります。 これらは同じクエリですが、スケーリング操作には再起動が必要であり、クエリを再コンパイルする必要があるため、クエリ ストアでは異なるquery_id値として表示されます。 レポートでは、全体と平均の時間が大幅に減少したことを確認できます。クエリ待機統計レポートも参照し、CPU 待機バーを選択します。 クエリの全体的な平均待機時間は短縮され、全体の時間に占める割合は低くなります。 これは、データベースの仮想コア数が少ない場合に、CPU がリソースのボトルネックになる可能性は低いという良い兆候を示しています。
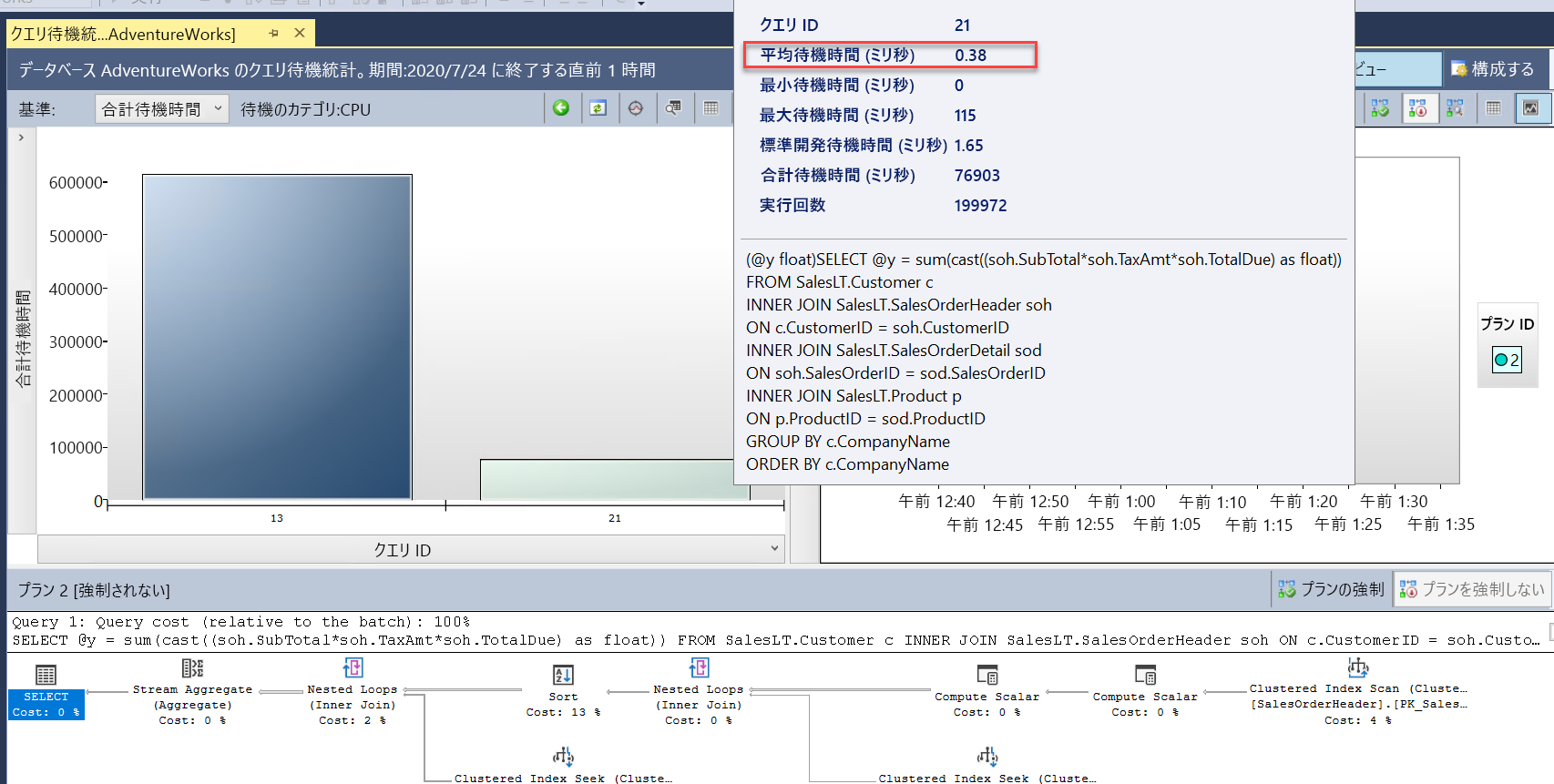
すべてのレポートとクエリ エディター ウィンドウを閉じることができます。 SSMS は、次の演習で必要になるため、接続したままにしてください。
Azure メトリックでの変更について観察する
Azure portal で [AdventureWorks] データベースに移動し、[概要] ペインの [監視] タブで [コンピューティング使用率] を再度確認します。
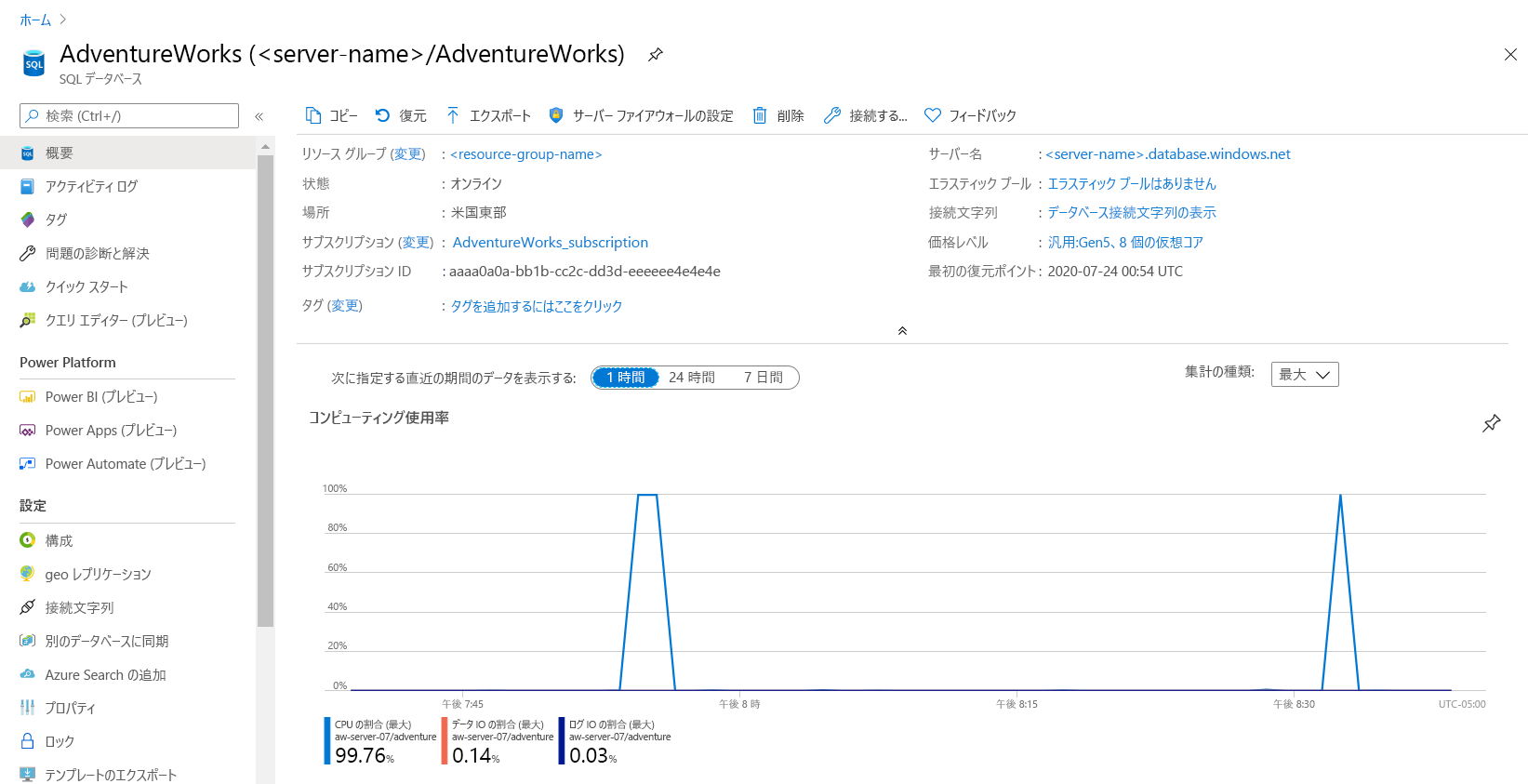
CPU 使用率が高いほど、継続時間は短くなることに注意してください。これは、ワークロードを実行するために必要な CPU リソースの全体的な減少を意味します。
このグラフは、多少誤解を招く可能性があります。 [監視] メニューから [メトリック] を使用し、メトリックを [CPU の制限] に設定します。 CPU 比較チャートは、次のようになります。
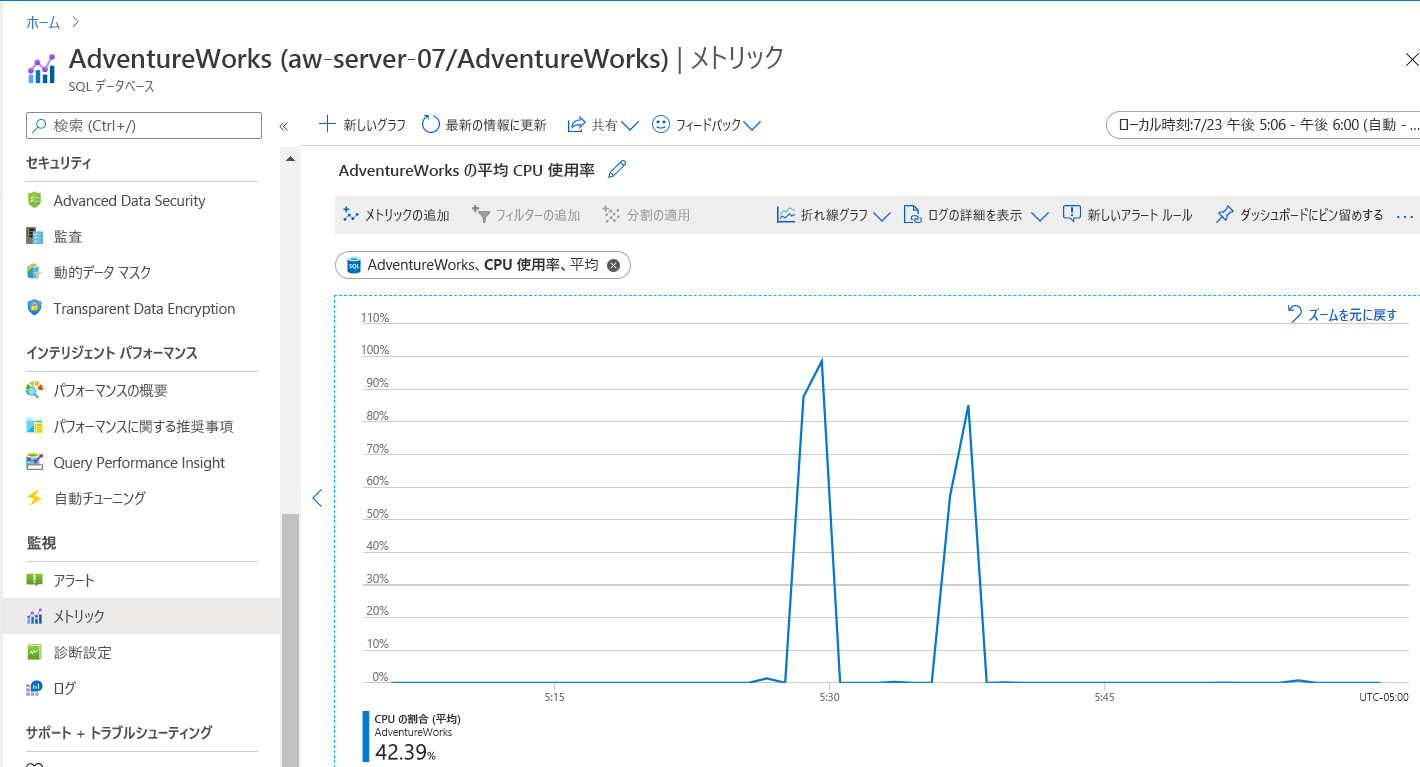
ヒント
このデータベースに対して仮想コアの数を増やし続けると、すべてのクエリに十分な CPU リソースが割り当てられるしきい値までパフォーマンスを向上させることができます。 これは、仮想コアの数をワークロードの同時ユーザー数と一致させる必要があるという意味ではありません。 また、価格レベルをプロビジョニング済みではなく、サーバーレス コンピューティング レベルを使用するように変更することもできます。 これは、ワークロードに対する自動スケール アプローチをさらに実現するのに役立ちます。 たとえば、このワークロードでは、仮想コアの最小値として 2、仮想コアの最大値として 8 を選択した場合、このワークロードはすぐに 8 個の仮想コアにスケーリングされます。
次の演習では、パフォーマンスの問題を観察し、アプリケーションのパフォーマンスに関するベスト プラクティスを適用して解決します。