KEDA によるスケーリング
Kubernetes イベント駆動型自動スケーリング
Kubernetes Event-driven Autoscaling (KEDA) は、アプリケーションの自動スケーリングを簡素化する単一目的の軽量コンポーネントです。 KEDA を任意の Kubernetes クラスターに追加し、それを標準の Kubernetes コンポーネント (ポッドの水平オートスケーラー (HPA) やクラスター オートスケーラーなど) と共に使用して、機能を拡張できます。 KEDA を利用すると、特定のアプリをイベント駆動型スケーリングの活用の対象にして、他のアプリでは異なるスケーリング方法を利用するようにできます。 KEDA は、任意の数の Kubernetes アプリケーションまたはフレームワークと共に実行できる、柔軟で安全なオプションです。
主な機能と特徴
- ゼロへのスケーリング機能を備えた、持続可能でコスト効率の高いアプリケーションを構築する
- KEDA スケーラーを使い、需要に合わせてアプリケーションのワークロードをスケーリングする
ScaledObjectsによるアプリケーションの自動スケーリングScaledJobsによるジョブの自動スケーリング- 自動スケーリングと認証をワークロードから切り離して、運用環境グレードのセキュリティを使う
- 独自の外部スケーラーで、カスタマイズされた自動スケーリング構成を使う
Architecture
KEDA には、次の 2 つの主要コンポーネントが用意されています。
- KEDA オペレーター:エンド ユーザーは、Kubernetes の Deployment、Job、StatefulSet や、
/scaleサブリソースを定義する任意の顧客リソースをサポートする、"ゼロから N 個" のインスタンスにワークロードをスケーリングできます。 - メトリック サーバー:Kafka トピック内のメッセージや Azure Event Hubs 内のイベントといった外部メトリックを HPA に公開し、自動スケーリング アクションを駆動します。 アップストリームの制限により、KEDA メトリック サーバーのクラスターにはメトリック アダプターのみインストールされている必要があります。
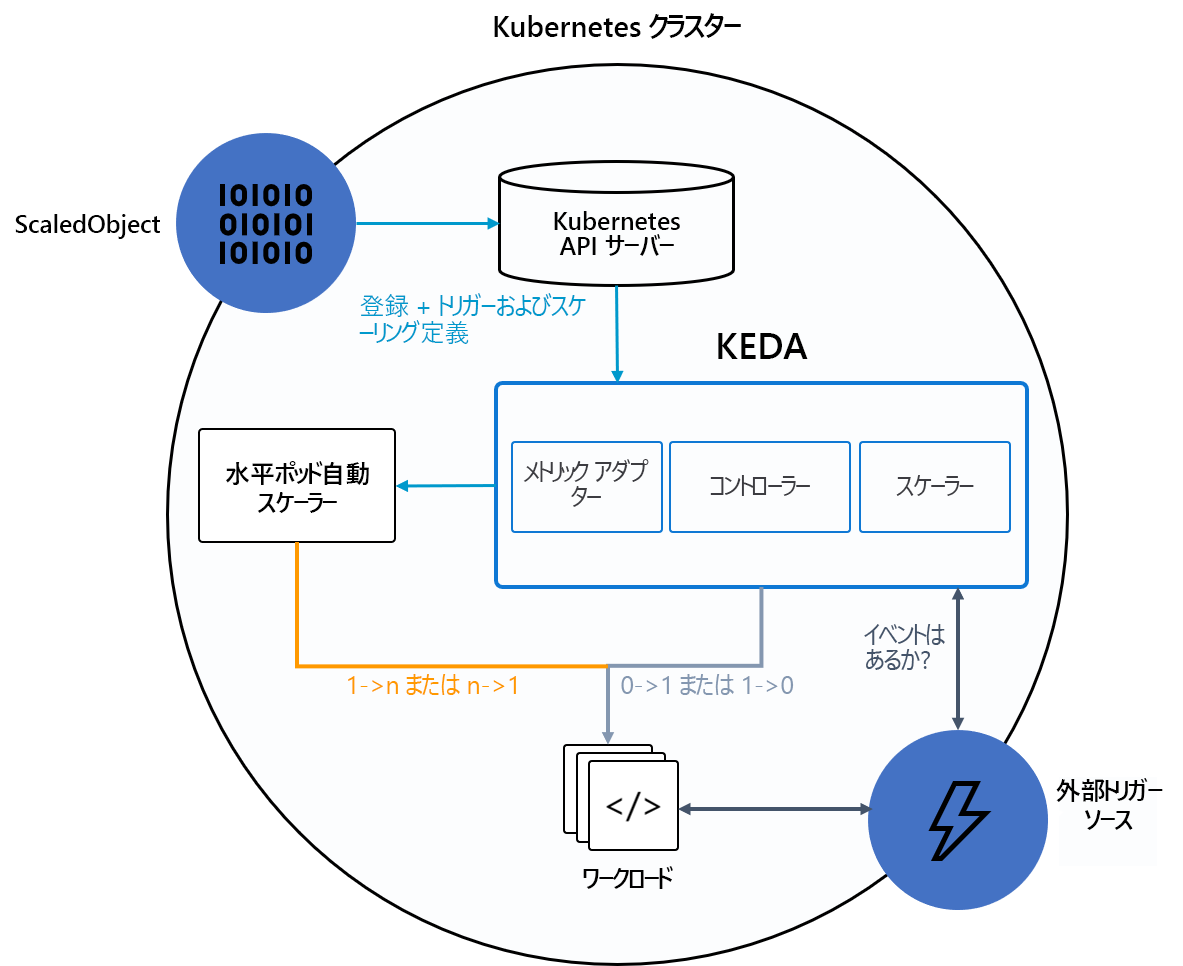
次の図は、KEDA がどのように Kubernetes HPA、外部イベント ソース、Kubernetes API サーバーと統合して自動スケーリング機能を提供するかを示しています。
ヒント
詳細については、KEDA の公式ドキュメントを参照してください。
イベント ソースとスケーラー
KEDA スケーラーでは、Deployment をアクティブ化するか非アクティブ化する必要があるかを検出することも、特定のイベント ソースのカスタム メトリックをフィードすることもできます。 Deployment と StatefulSet は、KEDA を使用してワークロードをスケーリングする最も一般的な方法です。 また、/scale サブリソースを実装するカスタム リソースをスケーリングすることも可能です。 これにより、KEDA でスケール トリガーに基づいてスケーリングする Kubernetes Deployment または StatefulSet を定義できます。 KEDA はこれらのサービスを監視し、発生したイベントに基づいて自動的にスケーリングします。
KEDA はバックグラウンドでイベント ソースを監視し、そのデータを Kubernetes と HPA にフィードして、リソースのスケーリングを迅速に実行します。 リソースの各レプリカでは、イベント ソースから項目をアクティブにプルします。 KEDA と Deployments/StatefulSets を使用すると、イベント ソースとの豊富な接続と処理セマンティクスを維持しながら、イベントに基づいてスケーリングできます (たとえば、順序付けされた処理、再試行、配信不能、チェックポイント処理)。
スケーリングされたオブジェクトの仕様
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: {scaled-object-name}
spec:
scaleTargetRef:
apiVersion: {api-version-of-target-resource} # Optional. Default: apps/v1
kind: {kind-of-target-resource} # Optional. Default: Deployment
name: {name-of-target-resource} # Mandatory. Must be in the same namespace as the ScaledObject
envSourceContainerName: {container-name} # Optional. Default: .spec.template.spec.containers[0]
pollingInterval: 30 # Optional. Default: 30 seconds
cooldownPeriod: 300 # Optional. Default: 300 seconds
minReplicaCount: 0 # Optional. Default: 0
maxReplicaCount: 100 # Optional. Default: 100
advanced: # Optional. Section to specify advanced options
restoreToOriginalReplicaCount: true/false # Optional. Default: false
horizontalPodAutoscalerConfig: # Optional. Section to specify HPA related options
behavior: # Optional. Use to modify HPA's scaling behavior
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 100
periodSeconds: 15
triggers:
# {list of triggers to activate scaling of the target resource}
スケーリングされたジョブの仕様
イベント駆動型コードを Deployment としてスケーリングする代替方法として、Kubernetes ジョブとしてコードを実行およびスケーリングすることもできます。 このオプションを検討する主な理由は、長時間の実行を処理する必要がある場合です。 Deployment 内で複数のイベントを処理するのではなく、検出されたイベントごとに独自の Kubernetes ジョブをスケジュールします。 この方法によって、各イベントを別個に処理し、キュー内のイベント数に基づいて同時実行する数をスケーリングできます。
apiVersion: keda.sh/v1alpha1
kind: ScaledJob
metadata:
name: {scaled-job-name}
spec:
jobTargetRef:
parallelism: 1 # [max number of desired pods](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/#controlling-parallelism)
completions: 1 # [desired number of successfully finished pods](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/#controlling-parallelism)
activeDeadlineSeconds: 600 # Specifies the duration in seconds relative to the startTime that the job may be active before the system tries to terminate it; value must be positive integer
backoffLimit: 6 # Specifies the number of retries before marking this job failed. Defaults to 6
template:
# describes the [job template](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/)
pollingInterval: 30 # Optional. Default: 30 seconds
successfulJobsHistoryLimit: 5 # Optional. Default: 100. How many completed jobs should be kept.
failedJobsHistoryLimit: 5 # Optional. Default: 100. How many failed jobs should be kept.
envSourceContainerName: {container-name} # Optional. Default: .spec.JobTargetRef.template.spec.containers[0]
maxReplicaCount: 100 # Optional. Default: 100
scalingStrategy:
strategy: "custom" # Optional. Default: default. Which Scaling Strategy to use.
customScalingQueueLengthDeduction: 1 # Optional. A parameter to optimize custom ScalingStrategy.
customScalingRunningJobPercentage: "0.5" # Optional. A parameter to optimize custom ScalingStrategy.
triggers:
# {list of triggers to create jobs}