DBCC SHOW_STATISTICS (Transact-SQL)
Applies to: ![]() SQL Server
SQL Server ![]() Azure SQL Database
Azure SQL Database ![]() Azure SQL Managed Instance
Azure SQL Managed Instance ![]() Azure Synapse Analytics
Azure Synapse Analytics ![]() Analytics Platform System (PDW)
Analytics Platform System (PDW) ![]() Microsoft Fabric の SQL 分析エンドポイント
Microsoft Fabric の SQL 分析エンドポイント ![]() Microsoft Fabric のウェアハウス
Microsoft Fabric のウェアハウス
テーブルまたはインデックス付きビューについての、現在のクエリの最適化に関する統計を表示します。 クエリ オプティマイザーでは、統計を使用してクエリ結果のカーディナリティまたは行数を推定して、Query Optimizer で高品質のクエリ プランを作成できるようにします。 たとえば、Query Optimizer では、カーディナリティの推定に基づいて、クエリ プランで Index Scan 操作ではなく Index Seek 操作が使用される場合があります。この場合、リソースを大量に消費する Index Scan 操作を使用しないようにすることでパフォーマンスが向上します。
Query Optimizer では、テーブルまたはインデックス付きビューの統計を統計オブジェクトに格納します。 テーブルの場合、インデックスまたはテーブル列のリストに関する統計オブジェクトが作成されます。 統計オブジェクトには、統計に関するメタデータが含まれるヘッダー、統計オブジェクトの最初のキー列の値の分布が含まれるヒストグラム、および列間の相関関係を測定する密度ベクトルが格納されています。 データベース エンジンでは、統計オブジェクトの任意のデータを使用してカーディナリティ推定値を計算できます。 詳細については、「統計」および「カーディナリティ推定 (SQL Server)」を参照してください。
DBCC SHOW_STATISTICS では、統計オブジェクトに格納されたデータに基づくヘッダー、ヒストグラム、および密度ベクトルを表示します。 この構文では、テーブルまたはインデックス付きビューを指定するときに、対象のインデックス名、統計名、または列名も指定することができます。
SQL Server の過去のバージョンでの重要な更新プログラム:
SQL Server 2012 (11.x) Service Pack 1 以降では、非増分統計の統計オブジェクトに含まれるヘッダー情報をプログラムで取得するために、sys.dm_db_stats_properties 動的管理ビューが使用可能です。
SQL Server 2014 (12.x) Service Pack 2 および SQL Server 2012 (11.x) Service Pack 1 以降では、増分統計の統計オブジェクトに含まれるヘッダー情報をプログラムで取得するために、sys.dm_db_incremental_stats_properties 動的管理ビューが使用可能です。
SQL Server 2016 (13.x) Service Pack 1 CU2 以降では、統計オブジェクトに含まれるヒストグラム情報をプログラムで取得するために、sys.dm_db_stats_histogram 動的管理ビューが使用可能です。
-
この構文は、Azure Synapse Analytics のサーバーレス SQL プールでサポートされていません。
Microsoft Fabric での統計について詳しくは、統計に関する記事をご覧ください。
構文
SQL Server と Azure SQL Database の構文:
DBCC SHOW_STATISTICS ( table_or_indexed_view_name , target )
[ WITH [ NO_INFOMSGS ] < option > [ , ...n ] ]
< option > ::=
STAT_HEADER | DENSITY_VECTOR | HISTOGRAM | STATS_STREAM
[ ; ]
Azure Synapse Analytics、Analytics Platform System (PDW)、Microsoft Fabric の場合の構文:
DBCC SHOW_STATISTICS ( table_name , target )
[ WITH { STAT_HEADER | DENSITY_VECTOR | HISTOGRAM } [ , ...n ] ]
[ ; ]
引数
table_or_indexed_view_name
統計情報を表示するテーブルまたはインデックス付きビューの名前。
table_name
表示する統計情報を含むテーブルの名前。 テーブルに外部テーブルを指定することはできません。
ターゲット
統計情報を表示するインデックス、統計、または列の名前。 target は、角かっこ、一重引用符、二重引用符で囲まれるか、または引用符を使用しません。
- target がテーブルまたはインデックス付きビューの既存のインデックスまたは統計の名前である場合は、その target に関する統計情報が返されます。
- target が既存の列の名前であり、自動的に作成された統計オブジェクトがその列にある場合は、その自動作成された統計に関する情報が返されます。
target 列に自動的に作成された統計が存在しない場合は、エラー メッセージ 2767 が返されます。
Azure Synapse Analytics および Analytics Platform System (PDW) では、target を列名にすることはできません。
Microsoft Fabric のウェアハウスでは、target には単一列ヒストグラム統計または列の名前を指定できます。 target に列名が使われている場合、このコマンドは、自動的に生成されるヒストグラム統計に関する分布情報のみを返します。 手動で作成したヒストグラム統計に関する情報を見るには、統計名を target として指定します。
NO_INFOMSGS
重大度レベル 0 から 10 のすべての情報メッセージを表示しないようにします。
STAT_HEADER | DENSITY_VECTOR | HISTOGRAM | STATS_STREAM [ , n ]
これらのオプションを 1 つ以上指定すると、ステートメントによって返される結果セットが、指定のオプションに合わせて制限されます。 オプションを指定しないと、すべての統計情報が返されます。
STATS_STREAM は、単に情報を示すためだけに特定されます。 サポートされていません。 将来の互換性は保証されません。
結果セット
次の表は、STAT_HEADER を指定した場合に結果セットに返される列を示しています。
| 列名 | 説明 |
|---|---|
| 名前 | 統計オブジェクトの名前。 |
| [更新] | 統計情報が最後に更新された日付と時刻。 STATS_DATE 関数でこの情報を取得することもできます。 詳細については、このページの「解説」セクションを参照してください。 |
| [行] | 統計情報が最後に更新された時点のテーブルまたはインデックス付きビューの行の総数。 統計がフィルター選択されている場合、またはフィルター選択されたインデックスに対応している場合は、行数がテーブルの行数よりも少なくなることがあります。 詳細については、統計に関する記事を参照してください。 |
| [サンプリングされた行数] | 統計の計算時にサンプリングされた行の合計数。 [サンプリングされた行数] < [行] の場合、表示されるヒストグラムおよび密度の結果は、サンプリングされた行に基づいて推定されます。 |
| 手順 | ヒストグラムの区間の数。 各区間の範囲には、上限の列値までの列値の範囲が含まれます。 ヒストグラムの区間は、統計の最初のキー列に基づいて定義されます。 区間の最大数は 200 です。 |
| 密度 | ヒストグラムの境界値を除く、統計オブジェクトの最初のキー列のすべての値について、"1 / distinct values " として計算されます。 この密度の値はクエリ オプティマイザーでは使用されません。SQL Server 2008 (10.0.x) より前のバージョンとの下位互換性を維持するために表示されます。 |
| [キーの平均の長さ] | 統計オブジェクトのすべてのキー列の、値ごとの平均バイト数。 |
| String Index | Yes の場合は、統計オブジェクトに文字列の統計概要が含まれています。これにより、LIKE 演算子を使用するクエリ述語 (WHERE ProductName LIKE '%Bike' など) に対するカーディナリティの推定が向上します。 文字列の統計概要は、ヒストグラムとは別に格納されます。この統計は、統計オブジェクトの最初のキー列について、その型が char、varchar、nchar、nvarchar、varchar(max) 、nvarchar(max) 、text、ntext である場合に作成されます。 |
| [フィルター式] | 統計オブジェクトに含まれるテーブル行のサブセットの述語。 NULL = フィルター選択されていない統計情報。 フィルター選択された述語の詳細については、「フィルター選択されたインデックスの作成」を参照してください。 フィルター選択された統計情報の詳細については、「統計情報」を参照してください。 |
| [フィルター処理なしの行数] | フィルター式を適用する前のテーブル内の行の合計数。 フィルター式が NULL の場合、Unfiltered Rows と Rows は等しいです。 |
| 永続化されたサンプルのパーセンテージ | サンプリングの割合を明示的に指定しない統計情報の更新に使用される永続化されたサンプルのパーセンテージです。 値がゼロの場合、永続化されたサンプルのパーセンテージがこの統計に設定されていません。 適用対象: SQL Server 2016 (13.x) Service Pack 1 CU 4 |
次の表は、DENSITY_VECTOR を指定した場合に結果セットに返される列を示しています。
| 列名 | 説明 |
|---|---|
| [すべての密度] | 密度は "1 / distinct values" です。 結果には、統計オブジェクトの列の各プレフィックスに対する密度が、密度ごとに 1 行表示されます。 個別の値は、行および列プレフィックスごとの列値の個別のリストです。 たとえば、統計オブジェクトにキー列 (A, B, C) が含まれる場合、結果では列プレフィックス (A)、(A, B)、(A, B, C) ごとに個別の値リストの密度が報告されます。 プレフィックス (A、B、C) を使用すると、これらの各リストは次の個別の値リストになります。(3, 5, 6)、(4, 4, 6)、(4, 5, 6)、(4, 5, 7)。 プレフィックス (A、B) を使用すると、同じ列値に次の個別の値リストが含まれます。(3, 5)、(4, 4) および (4, 5) |
| [平均の長さ] | 列プレフィックスの列値のリストを格納する平均の長さ (バイト単位)。 たとえば、リスト (3, 5, 6) の値ごとに 4 バイト必要な場合は、長さは 12 バイトになります。 |
| [列] | [すべての密度] および [平均の長さ] を表示するプレフィックスの列の名前。 |
次の表は、HISTOGRAM オプションを指定した場合に結果セットに返される列を示しています。
| 列名 | 説明 |
|---|---|
| [RANGE_HI_KEY] | ヒストグラム区間の上限の列値。 この列値はキー値とも呼ばれます。 |
| RANGE_ROWS | ヒストグラム区間内 (上限は除く) に列値がある行の予測数。 |
| EQ_ROWS | ヒストグラム区間の上限と列値が等しい行の予測数。 |
| DISTINCT_RANGE_ROWS | ヒストグラム区間内 (上限は除く) にある個別の列値を持つ行の予測数。 |
| AVG_RANGE_ROWS | 上限を除く、ヒストグラムのステップ内で重複する列の値を持つ行の数の平均値。 DISTINCT_RANGE_ROWS が 0 より大きいとき、RANGE_ROWS を DISTINCT_RANGE で割ることで AVG_RANGE_ROWS が計算されます。 DISTINCT_RANGE_ROWS が 0 のとき、AVG_RANGE_ROWS はヒストグラムのステップに対して 1 を返します。 |
解説
統計の更新日付は、メタデータではなく統計 BLOB オブジェクトにヒストグラムおよび密度ベクトルと共に格納されます。 統計データを生成するためのデータが読み取られていない場合、統計 BLOB は作成されず、日付は使用できず、updated 列は NULL になります。 これは、述語が行を返さないフィルター選択された統計情報や、新しい空のテーブルの場合です。
ヒストグラム
ヒストグラムでは、データセットの個別の値ごとに出現頻度を測定します。 クエリ オプティマイザーでは、統計オブジェクトの最初のキー列の列値に基づいてヒストグラムを計算し、行を統計的にサンプリングするかテーブルまたはビュー内のすべての行でフル スキャンを実行することによって列値を選択します。 サンプリングされた行のセットからヒストグラムを作成する場合、格納される行の総数および個別の値の数は推定値であり、必ずしも整数にはなりません。
ヒストグラムを作成するには、クエリ オプティマイザーで列値を並べ替え、個別の列値ごとに一致する値の数を計算し、列値を最大 200 の連続したヒストグラム区間に集計します。 各区間には、上限の列値までの列値の範囲が含まれます。 この範囲には、境界値の間 (境界値自体は除く) のすべての有効な列値が含まれます。 格納される最小の列値は、最初のヒストグラム区間の上限境界値になります。
次の図は、6 つの区間があるヒストグラムを示しています。 最初の上限境界値の左側にある領域が最初の区間です。

ヒストグラムの各区間は、以下のように表されます。
- 太線は、上限境界値 (RANGE_HI_KEY) およびその出現回数 (EQ_ROWS) を表します。
- RANGE_HI_KEY の左にある領域は、列値の範囲、およびそれぞれの列値の平均出現回数 (AVG_RANGE_ROWS) を表します。 最初のヒストグラム区間の AVG_RANGE_ROWS は常に 0 です。
- 点線は、範囲内にある個別の値の総数 (DISTINCT_RANGE_ROWS) および範囲内の値の総数 (RANGE_ROWS) を推定するために使用されるサンプリングされた値を表します。 クエリ オプティマイザーでは、RANGE_ROWS および DISTINCT_RANGE_ROWS を使用して AVG_RANGE_ROWS を計算します。サンプリングされた値は格納されません。
クエリ オプティマイザーでは、統計的有意性に応じてヒストグラム区間を定義します。 区間幅を最大にするアルゴリズムを使用して境界値の差を最大にし、ヒストグラムの区間の数を最小限に抑えます。 区間の最大数は 200 です。 ヒストグラムの区間の数は、境界点が 200 より少ない列でも、個別の値の数より少なくなることがあります。 たとえば、個別の値が 100 個ある列のヒストグラムの境界点が 100 より少なくなる場合もあります。
密度ベクトル
クエリ オプティマイザーでは、同一のテーブルまたはインデックス付きビューから複数の列を返すクエリに対するカーディナリティの推定を向上させるために密度を使用します。 密度ベクトルには、統計オブジェクトの列のプレフィックスごとに 1 つの密度が格納されます。 たとえば、統計オブジェクトに CustomerId、ItemId、Price というキー列がある場合、以下の列プレフィックスごとに密度が計算されます。
| 列プレフィックス | 密度の計算対象 |
|---|---|
(CustomerId) |
CustomerId の値が一致する行 |
(CustomerId, ItemId) |
CustomerId および ItemId 値が一致する行 |
(CustomerId, ItemId, Price) |
CustomerId、ItemId、および Price の値が一致する行 |
制限事項
DBCC SHOW_STATISTICS では、空間インデックスおよびメモリ最適化列ストア インデックスの統計情報は提供されません。
SQL Server および SQL Database のアクセス許可
統計オブジェクトを表示するには、ユーザーがテーブルに対する SELECT 権限を持っている必要があります。
SELECT 権限でコマンドを実行するには、次の要件があります。
- 統計オブジェクトのすべての列に対する権限が必要です。
- フィルター条件がある場合は、そのすべての列に対する権限が必要です。
- テーブルには、行レベルのセキュリティ ポリシーを持つことはできません。
- 統計オブジェクト内のいずれかの列が動的データ マスク ルールでマスクされている場合、ユーザーは
SELECT権限に加えて、UNMASK権限をもっているか、db_ddladmin ロールのメンバーである必要があります。
SQL Server 2012 (11.x) Service Pack 1 より前のバージョンでは、ユーザーはテーブルを所有しているか、sysadmin 固定サーバー ロール、db_owner 固定データベース ロール、または db_ddladmin 固定データベース ロールのメンバーである必要があります。
Note
動作を SQL Server 2012 (11.x) Service Pack 1 より前の動作に戻すには、トレース フラグ 9485 を使用します。
Azure Synapse Analytics および Analytics Platform System (PDW) のアクセス許可
DBCC SHOW_STATISTICS には、テーブルに対する SELECT アクセス許可か、sysadmin 固定サーバー ロール、db_owner 固定データベース ロール、または db_ddladmin 固定データベース ロールのメンバーシップが必要です。
Azure Synapse Analytics および Analytics Platform System (PDW) の制限事項と制約事項
DBCC SHOW_STATISTICS を使用すると、コントロール ノード レベルでの Shell データベースに格納されている統計情報が表示されます。 計算ノード上で SQL Server によって自動的に作成される統計情報は表示されません。
外部テーブルで DBCC SHOW_STATISTICS はサポートされていません。
Microsoft Fabric の DBCC SHOW_STATISTICS では、ACE-* 統計ではなく、ヒストグラム統計の結果のみが表示されます。
例: SQL Server と Azure SQL Database
A. すべての統計情報を返す
次の例では、AdventureWorks2022 データベースの Person.Address テーブルの AK_Address_rowguid インデックスに関するすべての統計情報を表示します。
DBCC SHOW_STATISTICS ("Person.Address", AK_Address_rowguid);
GO
B. HISTOGRAM オプションを指定する
これにより、Customer_LastName について表示される統計情報は HISTOGRAM データに制限されます。
DBCC SHOW_STATISTICS ("dbo.DimCustomer", Customer_LastName) WITH HISTOGRAM;
GO
例: Azure Synapse Analytics、Analytics Platform System (PDW)
C. 1 つの統計オブジェクトの内容を表示します。
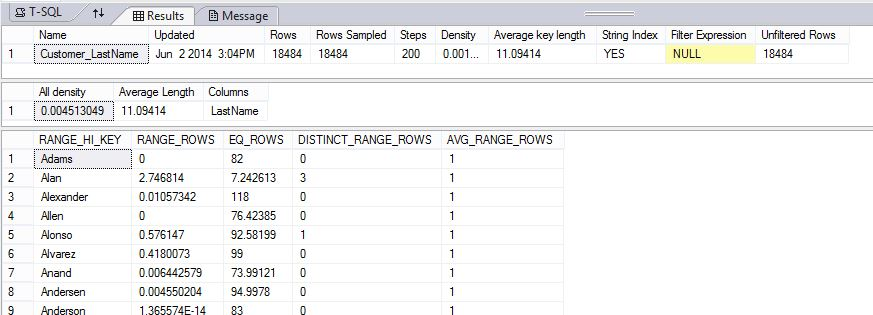
次の例では、統計オブジェクトを作成し、AdventureWorksPDW2022 サンプル データベースの DimCustomer テーブルに Customer_LastName 統計の内容を表示します。
-- Uses AdventureWorksPDW
--First, create a statistics object
CREATE STATISTICS Customer_LastName
ON AdventureWorksPDW2012.dbo.DimCustomer (LastName);
GO
DBCC SHOW_STATISTICS ("dbo.DimCustomer", Customer_LastName);
GO
結果は、ヘッダー、密度ベクトル、およびヒストグラムの一部を示します。
関連項目
- 統計
- Microsoft Fabric の統計
- sys.dm_db_stats_properties (Transact-SQL)
- sys.dm_db_stats_histogram (Transact-SQL)
- sys.dm_db_incremental_stats_properties (Transact-SQL)