テンポラル テーブルの使用シナリオ
適用対象: ![]() SQL Server
SQL Server
システム バージョン管理されたテンポラル テーブルは、データの変更履歴を追跡する必要があるシナリオに便利です。 生産性が高まるので、次の用途にテンポラル テーブルを使用することをお勧めします。
データの監査
何が変更されたか、いつ変更されたかを追跡する重要な情報が保存されている、また任意の時点のデータ フォレンジクスを実行する必要のあるテーブルには、システム バージョン管理されたテンポラル テーブルを使用できます。
テンポラル テーブルでは、開発サイクルの初期段階でデータの監査シナリオを計画したり、必要な時に既存のアプリケーションまたはソリューションにデータ監査を追加したりできます。
次の図に、現在 (青) と履歴行バージョン (グレー) のデータ サンプルを含む Employee テーブルのシナリオを示します。
図の右側部分では、時間軸の行バージョンと、テンポラル テーブルに対して (SYSTEM_TIME 句を使用した場合、または使用しない場合の) 異なる種類のクエリを実行したときに選択される行を視覚化しています。

データ監査用に新しいテーブルでシステム バージョン管理を有効にする
データの監査が必要な情報を特定したら、データベース テーブルをシステム バージョン管理されたテンポラル テーブルとして作成します。 次の例は、架空の HR データベースで Employee というテーブルがあるシナリオを示しています。
CREATE TABLE Employee (
[EmployeeID] INT NOT NULL PRIMARY KEY CLUSTERED,
[Name] NVARCHAR(100) NOT NULL,
[Position] VARCHAR(100) NOT NULL,
[Department] VARCHAR(100) NOT NULL,
[Address] NVARCHAR(1024) NOT NULL,
[AnnualSalary] DECIMAL(10, 2) NOT NULL,
[ValidFrom] DATETIME2(2) GENERATED ALWAYS AS ROW START,
[ValidTo] DATETIME2(2) GENERATED ALWAYS AS ROW END,
PERIOD FOR SYSTEM_TIME(ValidFrom, ValidTo)
)
WITH (SYSTEM_VERSIONING = ON (HISTORY_TABLE = dbo.EmployeeHistory));
システム バージョン管理されたテンポラル テーブルを作成する際のさまざまなオプションは、「システム バージョン管理されたテンポラル テーブルの作成」で説明されています。
データ監査用に既存のテーブルでシステム バージョン管理を有効にする
既存のデータベースのデータを監査する必要がある場合、ALTER TABLE を使用し、非テンポラル テーブルをシステム バージョン管理テーブルにします。 アプリケーションの破壊的変更を回避するために、「システム バージョン管理されたテンポラル テーブルを作成する」の説明に従って、期間列を HIDDEN として追加します。
次の例では、仮定の HR データベース内の既存の Employee テーブルで、システム バージョン管理を有効にする方法について説明します。 2 つの手順で、Employee テーブルのシステム バージョン管理を有効にします。 最初に、新しい期間列が HIDDEN として追加されます。 次に、既定の履歴テーブルが作成されます。
ALTER TABLE Employee ADD
ValidFrom DATETIME2(2) GENERATED ALWAYS AS ROW START HIDDEN
CONSTRAINT DF_ValidFrom DEFAULT DATEADD (SECOND, -1, SYSUTCDATETIME()),
ValidTo DATETIME2(2) GENERATED ALWAYS AS ROW END HIDDEN
CONSTRAINT DF_ValidTo DEFAULT '9999.12.31 23:59:59.99',
PERIOD FOR SYSTEM_TIME(ValidFrom, ValidTo);
ALTER TABLE Employee
SET (SYSTEM_VERSIONING = ON (HISTORY_TABLE = dbo.Employee_History));
重要
datetime2 データ型の有効桁数は、ソース テーブルとシステム バージョン管理された履歴テーブル内と同じです。
前述のスクリプトを実行すると、データに対するすべての変更は履歴テーブルに透過的に収集されます。 典型的なデータの監査シナリオでは、関心のある期間に各行に適用されたすべてのデータ変更を問い合わせます。 この用途に効果的に対応する、クラスター化された行ストア B ツリーを持つ既定の履歴テーブルが作成されます。
Note
ドキュメントでは、一般的にインデックスに関して B ツリーという用語が使用されます。 行ストア インデックスで、データベース エンジンによって B+ ツリーが実装されます。 これは、列ストア インデックスやメモリ最適化テーブルのインデックスには適用されません。 詳細については、「SQL Server と Azure SQL のインデックスのアーキテクチャとデザイン ガイド」を参照してください。
データ分析の実行
上記のいずれかの方法を使用してシステム バージョン管理を有効にすれば、データの監査はクエリを 1 回のみ実行すればできます。 次のクエリでは、Employee テーブルのうち、少なくとも 2021 年 1 月 1 日から 2022 年 1 月 1 日 (上限の境界を含む) の間にアクティブであった EmployeeID = 1000 を含むレコードの行バージョンが検索されます。
SELECT * FROM Employee
FOR SYSTEM_TIME BETWEEN '2021-01-01 00:00:00.0000000'
AND '2022-01-01 00:00:00.0000000'
WHERE EmployeeID = 1000
ORDER BY ValidFrom;
FOR SYSTEM_TIME BETWEEN...AND を FOR SYSTEM_TIME ALL で置換すると、その特定の従業員について、データ変更の履歴全体が分析されます。
SELECT * FROM Employee
FOR SYSTEM_TIME ALL
WHERE EmployeeID = 1000
ORDER BY ValidFrom;
その期間のみアクティブであった行バージョンを探す場合 (それ以外は含みません)、CONTAINED IN を使用します。 このクエリは履歴テーブルのみに対してクエリを行うので、効率的です。
SELECT * FROM Employee
FOR SYSTEM_TIME CONTAINED IN (
'2021-01-01 00:00:00.0000000', '2022-01-01 00:00:00.0000000'
)
WHERE EmployeeID = 1000
ORDER BY ValidFrom;
最後に、過去の任意の時点でテーブル全体がどのようであったか確認したい監査シナリオでは、次のように実行します。
SELECT * FROM Employee
FOR SYSTEM_TIME AS OF '2021-01-01 00:00:00.0000000';
システム バージョン管理されたテンポラル テーブルでは、期間列の値は UTC タイム ゾーンで格納されますが、データのフィルター処理と結果の表示の両方については、ローカルのタイム ゾーンで作業する方がより便利な場合があります。 次のコード サンプルは、SQL Server 2016 (13.x) で導入された AT TIME ZONE を使用し、ローカルのタイム ゾーンで指定されてから UTC に変換される、フィルター条件を適用する方法を示しています。
/* Add offset of the local time zone to current time*/
DECLARE @asOf DATETIMEOFFSET = GETDATE() AT TIME ZONE 'Pacific Standard Time';
/* Convert AS OF filter to UTC*/
SET @asOf = DATEADD(HOUR, - 9, @asOf) AT TIME ZONE 'UTC';
SELECT EmployeeID,
[Name],
Position,
Department,
[Address],
[AnnualSalary],
ValidFrom AT TIME ZONE 'Pacific Standard Time' AS ValidFromPT,
ValidTo AT TIME ZONE 'Pacific Standard Time' AS ValidToPT
FROM Employee
FOR SYSTEM_TIME AS OF @asOf
WHERE EmployeeId = 1000;
AT TIME ZONE は、システム バージョン管理されたテーブルを使用するすべてのシナリオで役立ちます。
FOR SYSTEM_TIME のテンポラル句に指定されたフィルタリング条件は SARG-able です。 SARG は search 引数を意味し、SARG-able は、SQL Server が基になるクラスター化インデックスを使用してスキャン操作の代わりにシークを実行できることを意味します。 詳細については、「SQL Server インデックス アーキテクチャとデザイン ガイド」に関するページを参照してください。
履歴テーブルに直接クエリを実行する場合、フィルター条件も、<period column> { < | > | =, ... } date_condition AT TIME ZONE 'UTC' の形式でフィルターを指定し、必ずフィルタリング条件も SARG-able になるようにしてください。
AT TIME ZONE を期間列に適用すると、SQL Server はテーブルまたはインデックス スキャンを実行しますが、これは非常にコストがかかることがあります。 また、
<period column> AT TIME ZONE '<your time zone>' > {< | > | =, ...} date_condition=
詳細については、「システム バージョン管理されたテンポラル テーブル内のデータに対してクエリを実行する」を参照してください。
特定の時点の分析 (タイム トラベル)
タイム トラベル シナリオでは、個々のレコードの変更に重点を置く代わりに、時間の経過と同時にデータ セット全体がどのように変化するかを示します。 タイム トラベルには、それぞれが別のペースで変更される、次に示すような分析すべき関連するテンポラル テーブルが含まれることがあります。
- 重要な指標の過去および現在のデータでの傾向
- (昨日や 1 か月前など) 過去の任意の "時点" のデータ全体の正確なスナップショット
- (1 か月前対 3 か月前など) 関心のある 2 つの時点の違い
タイム トラベル分析が必要な実世界のシナリオが多数あります。 この使用シナリオを示すために、履歴が自動生成される OLTP で見てみましょう。
自動生成されたデータ履歴を使用する OLTP
トランザクション処理システムでは、時間の経過とともに重要なメトリックがどのように変わるかを分析できます。 理想的には、履歴の分析で OLTP アプリケーションのパフォーマンスが損なわれないようにする必要があります。最新状態のデータに、最小限の遅延とデータ ロックでアクセスできる必要があるためです。 システム バージョン管理されたテンポラル テーブルを使用して、現在のデータとは別に、メインの OLTP ワークロードへの影響を最小限に抑えながら、後で分析するために変更の完全な履歴を透過的に保持することができます。
トランザクション処理の多いワークロードでは、コスト効率の高い方法で現在のデータをメモリ内に保存し、変更の完全な履歴をディスクに保存できる、メモリ最適化テーブルでのシステム バージョン管理されたテンポラル テーブルを使用することをお勧めします。
履歴テーブルには、次の理由から、クラスター化列ストア インデックスを使用することお勧めします。
クラスター化列ストア インデックスのクエリのパフォーマンスは、典型的な傾向の分析に有効です。
履歴テーブルにクラスター化列ストア インデックスがあり、OLTP のワークロードが高い場合、メモリが最適化されたテーブルでのデータのフラッシュ タスクは、最も高いパフォーマンスを発揮します。
クラスター化列ストア インデックスは、特にすべての列が同時に変更されるとは限らないシナリオで優れた圧縮を提供します。
インメモリ OLTP でテンポラル テーブルを使用すると、データ セット全体をメモリ内に保持する必要が減り、ホット データとコールド データを簡単に区別できるようになります。
このカテゴリに適合する実際のシナリオの例は、特に在庫管理や為替取引です。
次の図では、在庫管理に使用される単純なデータ モデルを示します。

次のコード例では、ProductInventory は、(既定で作成される行ストア インデックスを実際に置き換える) クラスター化列ストア インデックスが履歴テーブルにある、システム バージョン管理されたテンポラル テーブルがメモリ内に作成されます。
Note
データベースでメモリ最適化テーブルの作成が許可されていることを確認します。 「 メモリ最適化テーブルおよびネイティブ コンパイル ストアド プロシージャの作成」を参照してください。
USE TemporalProductInventory;
GO
BEGIN
--If table is system-versioned, SYSTEM_VERSIONING must be set to OFF first
IF ((SELECT temporal_type
FROM SYS.TABLES
WHERE object_id = OBJECT_ID('dbo.ProductInventory', 'U')) = 2)
BEGIN
ALTER TABLE [dbo].[ProductInventory]
SET (SYSTEM_VERSIONING = OFF);
END
DROP TABLE IF EXISTS [dbo].[ProductInventory];
DROP TABLE IF EXISTS [dbo].[ProductInventoryHistory];
END
GO
CREATE TABLE [dbo].[ProductInventory] (
ProductId INT NOT NULL,
LocationID INT NOT NULL,
Quantity INT NOT NULL CHECK (Quantity >= 0),
ValidFrom DATETIME2 GENERATED ALWAYS AS ROW START NOT NULL,
ValidTo DATETIME2 GENERATED ALWAYS AS ROW END NOT NULL,
PERIOD FOR SYSTEM_TIME(ValidFrom, ValidTo),
--Primary key definition
CONSTRAINT PK_ProductInventory PRIMARY KEY NONCLUSTERED (
ProductId,
LocationId
)
)
WITH (
MEMORY_OPTIMIZED = ON,
SYSTEM_VERSIONING = ON (
HISTORY_TABLE = [dbo].[ProductInventoryHistory],
DATA_CONSISTENCY_CHECK = ON
)
);
CREATE CLUSTERED COLUMNSTORE INDEX IX_ProductInventoryHistory
ON [ProductInventoryHistory] WITH (DROP_EXISTING = ON);
前述のモデルでは、在庫を管理する手順は次のようになります。
CREATE PROCEDURE [dbo].[spUpdateInventory]
@productId INT,
@locationId INT,
@quantityIncrement INT
WITH NATIVE_COMPILATION, SCHEMABINDING
AS
BEGIN ATOMIC
WITH (
TRANSACTION ISOLATION LEVEL = SNAPSHOT,
LANGUAGE = N'English'
)
UPDATE dbo.ProductInventory
SET Quantity = Quantity + @quantityIncrement
WHERE ProductId = @productId
AND LocationId = @locationId
-- If zero rows were updated then this is an insert
-- of the new product for a given location
IF @@rowcount = 0
BEGIN
IF @quantityIncrement < 0
SET @quantityIncrement = 0
INSERT INTO [dbo].[ProductInventory] (
[ProductId], [LocationID], [Quantity]
)
VALUES (@productId, @locationId, @quantityIncrement)
END
END;
spUpdateInventory ストアド プロシージャによって、在庫に新しい製品が挿入されるか、特定の場所の製品の数量が更新されます。 このビジネス ロジックは、テーブルの更新によって Quantity フィールドを増減させ、常に最新の状態を正しく維持することに焦点を当てており、単純です。それに対し、システム バージョン管理されたテーブルでは、次の図のとおり、履歴ディメンションをデータに追加します。

これで、ネイティブにコンパイルされているモジュールから最新の状態を効率的にクエリできます。
CREATE PROCEDURE [dbo].[spQueryInventoryLatestState]
WITH NATIVE_COMPILATION, SCHEMABINDING
AS
BEGIN ATOMIC
WITH (
TRANSACTION ISOLATION LEVEL = SNAPSHOT,
LANGUAGE = N'English'
)
SELECT ProductId, LocationID, Quantity, ValidFrom
FROM dbo.ProductInventory
ORDER BY ProductId, LocationId
END;
GO
EXEC [dbo].[spQueryInventoryLatestState];
次の例に示すとおり、FOR SYSTEM_TIME ALL 句を使用すると、データの経時的な変化の分析が簡単になります。
DROP VIEW IF EXISTS vw_GetProductInventoryHistory;
GO
CREATE VIEW vw_GetProductInventoryHistory
AS
SELECT ProductId,
LocationId,
Quantity,
ValidFrom,
ValidTo
FROM [dbo].[ProductInventory]
FOR SYSTEM_TIME ALL;
GO
SELECT * FROM vw_GetProductInventoryHistory
WHERE ProductId = 2;
次の図には、Power Query、Power BI または類似のビジネス インテリジェンス ツールに前述のビューをインポートすることにより、簡単にレンダリングできる 1 つの製品のデータ履歴を示しています。

このシナリオでテンポラル テーブルを使用すると、過去の任意の時点 AS OF 在庫の状態の再構築や、別の時点のスナップショットとの比較など、その他の種類のタイム トラベル分析を行えます。
この使用シナリオ用に、Product テーブルと Location テーブルをテンポラル テーブルに拡張して、UnitPrice と NumberOfEmployee の変更履歴を後で分析することもできます。
ALTER TABLE Product ADD
ValidFrom DATETIME2 GENERATED ALWAYS AS ROW START HIDDEN
CONSTRAINT DF_ValidFrom DEFAULT DATEADD (SECOND, -1, SYSUTCDATETIME()),
ValidTo DATETIME2 GENERATED ALWAYS AS ROW END HIDDEN
CONSTRAINT DF_ValidTo DEFAULT '9999.12.31 23:59:59.99',
PERIOD FOR SYSTEM_TIME(ValidFrom, ValidTo);
ALTER TABLE Product
SET (SYSTEM_VERSIONING = ON (HISTORY_TABLE = dbo.ProductHistory));
ALTER TABLE [Location] ADD
ValidFrom DATETIME2 GENERATED ALWAYS AS ROW START HIDDEN
CONSTRAINT DFValidFrom DEFAULT DATEADD (SECOND, -1, SYSUTCDATETIME()),
ValidTo DATETIME2 GENERATED ALWAYS AS ROW END HIDDEN
CONSTRAINT DFValidTo DEFAULT '9999.12.31 23:59:59.99',
PERIOD FOR SYSTEM_TIME(ValidFrom, ValidTo);
ALTER TABLE [Location]
SET (SYSTEM_VERSIONING = ON (HISTORY_TABLE = dbo.LocationHistory));
これでデータ モデルは複数のテンポラル テーブルを使用するようになったので、AS OF 分析のベスト プラクティスとしては、関連テーブルから必要なデータを抽出するビューを作成し、そのビューに FOR SYSTEM_TIME AS OF を適用します。こうすることで、データ モデル全体の状態の再構築が非常に簡単になります。
DROP VIEW IF EXISTS vw_ProductInventoryDetails;
GO
CREATE VIEW vw_ProductInventoryDetails
AS
SELECT PrInv.ProductId,
PrInv.LocationId,
P.ProductName,
L.LocationName,
PrInv.Quantity,
P.UnitPrice,
L.NumberOfEmployees,
P.ValidFrom AS ProductStartTime,
P.ValidTo AS ProductEndTime,
L.ValidFrom AS LocationStartTime,
L.ValidTo AS LocationEndTime,
PrInv.ValidFrom AS InventoryStartTime,
PrInv.ValidTo AS InventoryEndTime
FROM dbo.ProductInventory AS PrInv
INNER JOIN dbo.Product AS P
ON PrInv.ProductId = P.ProductID
INNER JOIN dbo.Location AS L
ON PrInv.LocationId = L.LocationID;
GO
SELECT * FROM vw_ProductInventoryDetails
FOR SYSTEM_TIME AS OF '2022-01-01';
次のスクリーンショットは、SELECT クエリ用に生成された実行プランを示しています。 これは、データベース エンジンによって、テンポラルな関係を処理するときのすべての複雑が処理されることを示しています。

次のコードを使用すると、ある 2 つの時点 (前日と 1 か月前) の製品の在庫の状態を比較できます。
DECLARE @dayAgo DATETIME2 = DATEADD (DAY, -1, SYSUTCDATETIME());
DECLARE @monthAgo DATETIME2 = DATEADD (MONTH, -1, SYSUTCDATETIME());
SELECT inventoryDayAgo.ProductId,
inventoryDayAgo.ProductName,
inventoryDayAgo.LocationName,
inventoryDayAgo.Quantity AS QuantityDayAgo,
inventoryMonthAgo.Quantity AS QuantityMonthAgo,
inventoryDayAgo.UnitPrice AS UnitPriceDayAgo,
inventoryMonthAgo.UnitPrice AS UnitPriceMonthAgo
FROM vw_ProductInventoryDetails
FOR SYSTEM_TIME AS OF @dayAgo AS inventoryDayAgo
INNER JOIN vw_ProductInventoryDetails
FOR SYSTEM_TIME AS OF @monthAgo AS inventoryMonthAgo
ON inventoryDayAgo.ProductId = inventoryMonthAgo.ProductId
AND inventoryDayAgo.LocationId = inventoryMonthAgo.LocationID;
異常検出
異常検出 (または外れ値検知) では、予想されているパターンやデータセット内の他のアイテムと一致しないアイテムを識別できます。 システム バージョン管理されたテンポラル テーブルを使用すると、一時的なクエリを使用して、特定のパターンをすばやく検索できるので、定期的にまたは不規則に発生する異常を検出できます。 何が異常であるかは、収集するデータの種類およびビジネス ロジックによって異なります。
次の例は、販売数の "急増" を検出する単純化されたロジックです。 購入品の履歴を収集するテンポラル テーブルで作業しているとします。
CREATE TABLE [dbo].[Product] (
[ProdID] [int] NOT NULL PRIMARY KEY CLUSTERED,
[ProductName] [varchar](100) NOT NULL,
[DailySales] INT NOT NULL,
[ValidFrom] [datetime2] GENERATED ALWAYS AS ROW START NOT NULL,
[ValidTo] [datetime2] GENERATED ALWAYS AS ROW END NOT NULL,
PERIOD FOR SYSTEM_TIME([ValidFrom], [ValidTo])
)
WITH (
SYSTEM_VERSIONING = ON (
HISTORY_TABLE = [dbo].[ProductHistory],
DATA_CONSISTENCY_CHECK = ON
)
);
次の図は購入を時間順に示しています。

通常の日は購入品数にはあまり変動がないことを前提に、次のクエリでは単一の外れ値が識別されます。つまり、周りのサンプルは大きくは変わらない中 (20% 未満)、すぐ隣のものと比較して大きく異なる (2 倍) サンプルが識別されます。
WITH CTE (
ProdId,
PrevValue,
CurrentValue,
NextValue,
ValidFrom,
ValidTo
)
AS (
SELECT ProdId,
LAG(DailySales, 1, 1) OVER (PARTITION BY ProdId ORDER BY ValidFrom) AS PrevValue,
DailySales,
LEAD(DailySales, 1, 1) OVER (PARTITION BY ProdId ORDER BY ValidFrom) AS NextValue,
ValidFrom,
ValidTo
FROM Product
FOR SYSTEM_TIME ALL
)
SELECT ProdId,
PrevValue,
CurrentValue,
NextValue,
ValidFrom,
ValidTo,
ABS(PrevValue - NextValue) / convert(FLOAT, (
CASE
WHEN NextValue > PrevValue THEN PrevValue
ELSE NextValue
END)) AS PrevToNextDiff,
ABS(CurrentValue - PrevValue) / convert(FLOAT, (
CASE
WHEN CurrentValue > PrevValue THEN PrevValue
ELSE CurrentValue
END)) AS CurrentToPrevDiff,
ABS(CurrentValue - NextValue) / convert(FLOAT, (
CASE
WHEN CurrentValue > NextValue THEN NextValue
ELSE CurrentValue
END)) AS CurrentToNextDiff
FROM CTE
WHERE ABS(PrevValue - NextValue) / (
CASE
WHEN NextValue > PrevValue THEN PrevValue
ELSE NextValue
END) < 0.2
AND ABS(CurrentValue - PrevValue) / (
CASE
WHEN CurrentValue > PrevValue THEN PrevValue
ELSE CurrentValue
END) > 2
AND ABS(CurrentValue - NextValue) / (
CASE
WHEN CurrentValue > NextValue THEN NextValue
ELSE CurrentValue
END) > 2;
Note
この例は意図的に単純化しています。 実稼働のシナリオでは、共通のパターンを示さないサンプルの識別には高度な統計的手法が使用されるでしょう。
緩やかに変化するディメンション
通常、データ ウェアハウスのディメンションには、エンティティに関する地理的な場所、顧客、または製品など、比較的静的なデータが含まれます。 ただし、一部のシナリオでは、ディメンション テーブル内のデータも追跡する必要があります。 ディメンションに対する変更は予測できない方法でまれにしか実行されず、ファクト テーブルに適用される定期的な更新スケジュール外のものであるため、この種のディメンション テーブルは、緩やかに変化するディメンション (SCD) と呼ばれています。
変更履歴がどのように保存されるかによって、緩やかに変化するディメンションには、いくつかのカテゴリがあります。
| 分析コード タイプ | 詳細 |
|---|---|
| タイプ 0 | 履歴は保存されません。 ディメンション属性は元の値です。 |
| タイプ 1 | ディメンション属性には最新の値が反映されます (前の値は上書きされます)。 |
| タイプ 2 | ディメンション メンバーのすべてのバージョンは、通常は有効期間を示す列と共にテーブルに別の行に示されます。 |
| タイプ 3 | 同じ行の追加の列を使用して、選択された属性の限られた履歴を保持する |
| タイプ 4 | 元のディメンション テーブルには最新 (現在) のディメンション メンバーのバージョンを保持しながら、別のテーブルに履歴を保持します。 |
SCD 戦略を選択した場合、ディメンション テーブルは ETL (Extract-Transform-Load) 層によって正確に維持されますが、通常はより複雑なコードと余分なメンテナンスが必要になります。
システム バージョン管理されたテンポラル テーブルを使用すると、データ履歴は自動的に保存されるので、コードの複雑さが大幅に少なくなります。 2 つのテーブルを使用して実装されるテンポラル テーブルは、タイプ 4 の SCD に最も近いものです。 しかし、テンポラル クエリでは現在のテーブルしか参照できないので、タイプ 2 の SCD の使用を計画している環境でもテンポラル テーブルを検討できます。
標準のディメンションを SCD に変換するために、新しいものを作成するか、既存のものをシステム バージョン管理されたテンポラル テーブルになるように変更することができます。 既存のディメンション テーブルに履歴データが含まれる場合、別のテーブルを作成して、そこに履歴データを移動し、現在 (実際) のディメンション バージョンを元のディメンション テーブルに保存します。 次いで ALTER TABLE 構文を使用し、ディメンション テーブルを事前定義された履歴テーブルを持つシステム バージョン管理されたテンポラル テーブルに変換します。
次の例はプロセスを図で示したものであり、DimLocation ディメンション テーブルに、ETL 処理によって入力される null 値を許可しない datetime2 の列として ValidFrom および ValidTo が既にあることを前提としています。
/* Move "closed" row versions into newly created history table*/
SELECT * INTO DimLocationHistory
FROM DimLocation
WHERE ValidTo < '9999-12-31 23:59:59.99';
GO
/* Create clustered columnstore index which is a very good choice in DW scenarios*/
CREATE CLUSTERED COLUMNSTORE INDEX IX_DimLocationHistory ON DimLocationHistory;
/* Delete previous versions from DimLocation which will become current table in temporal-system-versioning configuration*/
DELETE FROM DimLocation
WHERE ValidTo < '9999-12-31 23:59:59.99';
/* Add period definition*/
ALTER TABLE DimLocation
ADD PERIOD FOR SYSTEM_TIME(ValidFrom, ValidTo);
/* Enable system-versioning and bind history table to the DimLocation*/
ALTER TABLE DimLocation
SET (SYSTEM_VERSIONING = ON (HISTORY_TABLE = dbo.DimLocationHistory));
一度 SCD を作成したら、データ ウェアハウスの読み込み処理中は、それを維持するための追加のコードは必要ありません。
次の図は、2 つの SCD (DimLocation および DimProduct)と 1 つのファクト テーブルを使用する単純なシナリオでテンポラル テーブルを使用する方法を示します。

レポートで前述の SCD を使用するには、クエリを効率的に調整する必要があります。 たとえば、過去 6 か月間の売上額合計と 1 人当たりが販売した製品の平均数を計算したいとします。 両方のメトリックでは、ファクト テーブルとディメンションのデータに相関関係がある必要があります。分析に重要なその属性 (DimLocation.NumOfCustomers、DimProduct.UnitPrice) に変更がある可能性があります。 次のクエリによって、必要なメトリックが正しく計算されます。
DECLARE @now DATETIME2 = SYSUTCDATETIME();
DECLARE @sixMonthsAgo DATETIME2;
SET @sixMonthsAgo = DATEADD(month, - 12, SYSUTCDATETIME());
SELECT DimProduct_History.ProductId,
DimLocation_History.LocationId,
SUM(F.Quantity * DimProduct_History.UnitPrice) AS TotalAmount,
AVG(F.Quantity / DimLocation_History.NumOfCustomers) AS AverageProductsPerCapita
FROM FactProductSales F
/* find corresponding record in SCD history in last 6 months, based on matching fact */
INNER JOIN DimLocation
FOR SYSTEM_TIME BETWEEN @sixMonthsAgo AND @now AS DimLocation_History
ON DimLocation_History.LocationId = F.LocationId
AND F.FactDate BETWEEN DimLocation_History.ValidFrom AND DimLocation_History.ValidTo
/* find corresponding record in SCD history in last 6 months, based on matching fact */
INNER JOIN DimProduct
FOR SYSTEM_TIME BETWEEN @sixMonthsAgo AND @now AS DimProduct_History
ON DimProduct_History.ProductId = F.ProductId
AND F.FactDate BETWEEN DimProduct_History.ValidFrom AND DimProduct_History.ValidTo
WHERE F.FactDate BETWEEN @sixMonthsAgo AND @now
GROUP BY DimProduct_History.ProductId, DimLocation_History.LocationId;
考慮事項
データベースのトランザクション時間に基づいて計算される有効期間がビジネス ロジックで問題ない場合は、SCD にシステム バージョン管理されたテンポラル テーブルを使用できます。 データが大幅に遅れて読み込まれる場合、トランザクション時間が許可されないものとなってしまう場合があります。
既定では、システム バージョン管理されたテンポラル テーブルでは、読み込み後の履歴データは変更できません (SYSTEM_VERSIONING を OFF に設定した後に履歴を変更できます)。 履歴データの変更が定期的に行われる場合は、これが制限になる可能性があります。
システム バージョン管理されたテンポラル テーブルでは、すべての列の変更で行バージョンが生成されます。 特定の列の変更で新しいバージョンが作成されるのを抑制したい場合、その制限を ETL ロジックに組み込む必要があります。
SCD テーブルの履歴行が多くなることが予想される場合、履歴テーブルのメインのストレージ オプションとしてクラスター化列ストア インデックスを使用することを検討してください。 列ストア インデックスを使用すると、履歴テーブルのフットプリントが減少し、分析クエリが高速化されます。
データの行レベルでの破損を修復する
システム バージョン管理されたテンポラル テーブルの履歴データを使用すると、個々の行を以前にキャプチャした任意の状態に迅速に修復できます。 テンポラル テーブルのこのプロパティは、影響を受けた行を探せる場合や、不要なデータ変更が行われた時間がわかっている場合に便利です。 この知識により、バックアップを処理することなく効率的に修復を実行できます。
この方法には、いくつかの利点があります。
修復のスコープを正確に制御できます。 影響を受けていないレコードは最新の状態に維持される必要があり、これは多くの場合、非常に重要な要件になります。
効率的に操作でき、そのデータを使用するすべてのワークロードのためにデータベースをオンライン状態に維持できます。
修復操作自体が、バージョン管理されます。 修復操作自体の監査記録があるので、必要に応じて後で何が発生したか分析できます。
修復アクションは、比較的簡単に自動化できます。 次のコード例は、データの監査シナリオで使用される Employee テーブルのデータの修復を実行するストアド プロシージャを示しています。
DROP PROCEDURE IF EXISTS sp_RepairEmployeeRecord;
GO
CREATE PROCEDURE sp_RepairEmployeeRecord
@EmployeeID INT,
@versionNumber INT = 1
AS
WITH History
AS (
/* Order historical rows by their age in DESC order*/
SELECT
ROW_NUMBER() OVER (PARTITION BY EmployeeID
ORDER BY [ValidTo] DESC) AS RN,
*
FROM Employee FOR SYSTEM_TIME ALL
WHERE YEAR(ValidTo) < 9999 AND Employee.EmployeeID = @EmployeeID
)
/* Update current row by using N-th row version from history (default is 1 - i.e. last version) */
UPDATE Employee
SET [Position] = H.[Position],
[Department] = H.Department,
[Address] = H.[Address],
AnnualSalary = H.AnnualSalary
FROM Employee E
INNER JOIN History H ON E.EmployeeID = H.EmployeeID AND RN = @versionNumber
WHERE E.EmployeeID = @EmployeeID;
このストアド プロシージャでは、@EmployeeID と @versionNumber を入力パラメーターとして受け取ります。 この手順は、既定では、行の状態を履歴から最新のバージョンに復元します (@versionNumber = 1)。
次の図は、プロシージャの呼び出しの前後に行の状態を示しています。 長方形で赤くマークされているのは、不正な行バージョンで、長方形で緑にマークされているのは履歴の正しいバージョンです。

EXEC sp_RepairEmployeeRecord @EmployeeID = 1, @versionNumber = 1;

この修復のストアド プロシージャは、行のバージョンではなく、正確なタイムスタンプを受け入れるように定義できます。 指定された時点 (つまり、AS OF の時点) でアクティブであった任意のバージョンに行を復元します。
DROP PROCEDURE IF EXISTS sp_RepairEmployeeRecordAsOf;
GO
CREATE PROCEDURE sp_RepairEmployeeRecordAsOf
@EmployeeID INT,
@asOf DATETIME2
AS
/* Update current row to the state that was actual AS OF provided date*/
UPDATE Employee
SET [Position] = History.[Position],
[Department] = History.Department,
[Address] = History.[Address],
AnnualSalary = History.AnnualSalary
FROM Employee AS E
INNER JOIN Employee FOR SYSTEM_TIME AS OF @asOf AS History
ON E.EmployeeID = History.EmployeeID
WHERE E.EmployeeID = @EmployeeID;
次の図では、同じデータ サンプルを時間条件で復元するシナリオを示しています。 @asOf パラメーター、指定された時点で実際のものであった履歴で選択されていた行、修復操作後の現在のテーブルの新しい行バージョンが強調表示されています。

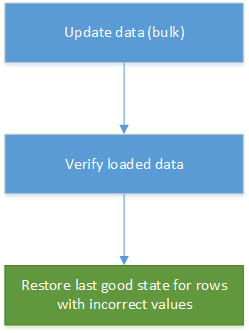
データ修正は、データ ウェアハウスおよびレポート システムで自動的にデータを読み込む際の一部にできます。 新しく更新された値が正しくない場合、多くのシナリオでは、履歴から以前のバージョンを復元することで十分に対応できます。 次の図では、これを自動化する手順を示します。