Hadoop 内の外部データにアクセスするように PolyBase を構成する
Applies to: ![]() SQL Server - Windows only
SQL Server - Windows only ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
この記事では、SQL Server インスタンス上で PolyBase を使用して、Hadoop 上の外部データに対してクエリを実行する方法について説明します。
Note
SQL Server 2022 (16.x) 以降、Hadoop は PolyBase でサポートされなくなります。
前提条件
- PolyBase をインストールしていない場合は、「PolyBase のインストール」をご覧ください。 インストールに関する記事では、前提条件について説明します。
- SQL Server 2019 (15.x) 以降では、PolyBase 機能を有効にすることも必要です。
- PolyBase は、Hortonworks Data Platform (HDP) と Cloudera Distributed Hadoop (CDH) の 2 つの Hadoop プロバイダーをサポートしています。 Hadoop では、新規リリースについて "Major.Minor.Version" パターンを採用しており、サポートされているメジャーおよびマイナー リリース内のすべてのバージョンがサポートされています。 サポートされている Hortonworks Data Platform (HDP) と Cloudera Distributed Hadoop (CDH) のバージョンについては、「PolyBase 接続構成」を参照してください。
Note
PolyBase では、SQL Server 2016 SP1 CU7 および SQL Server 2017 CU3 以降の Hadoop 暗号化ゾーンがサポートされています。 PolyBase スケールアウト グループを使用する場合は、すべての計算ノードを、Hadoop 暗号化ゾーンがサポートされたビルド上に配置にする必要があります。
Hadoop 接続を構成する
まず、特定の Hadoop プロバイダーを使用するように SQL Server PolyBase を構成します。
'hadoop connectivity' を使用して sp_configure を実行し、プロバイダーに対する適切な値を設定します。 プロバイダーの値を見つけるには、PolyBase 接続構成 に関する記事を参照してください。
-- Values map to various external data sources. -- Example: value 7 stands for Hortonworks HDP 2.1 to 2.6 on Linux, -- 2.1 to 2.3 on Windows Server, and Azure Blob Storage sp_configure @configname = 'hadoop connectivity', @configvalue = 7; GO RECONFIGURE GOservices.msc を使用して SQL Server を再起動する必要があります。 SQL Server を再起動すると、次のサービスが再起動します。
- SQL Server PolyBase Data Movement Service
- SQL Server PolyBase エンジン

プッシュダウン計算を有効にする
クエリ パフォーマンスを高めるには、Hadoop クラスターへのプッシュダウン計算を有効にします。
SQL Server のインストール パスで yarn-site.xml というファイルを検索します。 通常、このパスは次のとおりです。
C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\Binn\PolyBase\Hadoop\conf\Hadoop コンピューターで、Hadoop 構成ディレクトリ内の対応するファイルを検索します。 このファイル内の構成キー yarn.application.classpath の値をコピーします。
SQL Server コンピューターで、yarn.site.xml ファイル 内の yarn.application.classpath プロパティを検索します。 Hadoop コンピューターからこの値要素に値を貼り付けます。
すべての CDH 5.X バージョンで、yarn.site.xml file の最後か mapred-site.xml file に mapreduce.application.classpath 構成パラメーターを追加する必要があります。 HortonWorks では、yarn.application.classpath 構成内にこれらの構成が含まれます。 例については、「PolyBase の構成」を参照してください。
重要
Hadoop で計算プッシュダウン機能を使用するには、ターゲットの Hadoop クラスターに、ジョブの履歴サーバーが有効になっている HDFS のコア コンポーネントの YARN と MapReduce がある必要があります。 PolyBase から MapReduce 経由でプッシュダウン クエリを送信し、ジョブの履歴サーバーからステータスをプルします。 いずれかのコンポーネントがない場合、クエリは失敗します。
外部テーブルを構成する
Hadoop データ ソース内のデータのクエリを実行するには、Transact-SQL クエリで使用する外部テーブルを定義する必要があります。 次の手順では、外部テーブルを構成する方法を説明します。
まだ存在しない場合は、データベースにマスター キーを作成します。 これは、資格情報のシークレットの暗号化に必須です。
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password';引数
PASSWORD ='password'
データベース内のマスター キーの暗号化に使用されているパスワードを指定します。 パスワードは、SQL Server のインスタンスをホストしている、コンピューターの Windows パスワード ポリシー要件を満たす必要があります。
Kerberos でセキュリティ保護された Hadoop クラスターのデータベース スコープ資格情報を作成します。
-- IDENTITY: the Kerberos user name. -- SECRET: the Kerberos password CREATE DATABASE SCOPED CREDENTIAL HadoopUser1 WITH IDENTITY = '<hadoop_user_name>', Secret = '<hadoop_password>';CREATE EXTERNAL DATA SOURCE を使用して外部データ ソースを作成します。
-- LOCATION (Required) : Hadoop Name Node IP address and port. -- RESOURCE MANAGER LOCATION (Optional): Hadoop Resource Manager location to enable pushdown computation. -- CREDENTIAL (Optional): the database scoped credential, created above. CREATE EXTERNAL DATA SOURCE MyHadoopCluster WITH ( TYPE = HADOOP, LOCATION ='hdfs://10.xxx.xx.xxx:xxxx', RESOURCE_MANAGER_LOCATION = '10.xxx.xx.xxx:xxxx', CREDENTIAL = HadoopUser1 );CREATE EXTERNAL FILE FORMAT を使用して外部ファイル形式を作成します。
-- FORMAT TYPE: Type of format in Hadoop (DELIMITEDTEXT, RCFILE, ORC, PARQUET). CREATE EXTERNAL FILE FORMAT TextFileFormat WITH ( FORMAT_TYPE = DELIMITEDTEXT, FORMAT_OPTIONS (FIELD_TERMINATOR ='|', USE_TYPE_DEFAULT = TRUE))CREATE EXTERNAL TABLEを使用して、Hadoop に格納されているデータをポイントする外部テーブルを作成します。 この例では、外部データには車両センサー データが含まれています。
-- LOCATION: path to file or directory that contains the data (relative to HDFS root). CREATE EXTERNAL TABLE [dbo].[CarSensor_Data] ( [SensorKey] int NOT NULL, [CustomerKey] int NOT NULL, [GeographyKey] int NULL, [Speed] float NOT NULL, [YearMeasured] int NOT NULL ) WITH (LOCATION='/Demo/', DATA_SOURCE = MyHadoopCluster, FILE_FORMAT = TextFileFormat );外部テーブルの統計を作成します。
CREATE STATISTICS StatsForSensors on CarSensor_Data(CustomerKey, Speed)
PolyBase クエリ
PolyBase が適している機能には、次の 3 つがあります。
- 外部テーブルに対するアドホック クエリ。
- データのインポート。
- データのエクスポート。
次のクエリでは、架空の車両センサー データの例を示します。
アドホック クエリ
次のアドホック クエリでは、Hadoop データを結合します。 時速 35 マイルを越えて走行している顧客を選択し、SQL Server に格納されている構造化された顧客データと Hadoop に格納されている車両センサー データを結合します。
SELECT DISTINCT Insured_Customers.FirstName,Insured_Customers.LastName,
Insured_Customers. YearlyIncome, CarSensor_Data.Speed
FROM Insured_Customers, CarSensor_Data
WHERE Insured_Customers.CustomerKey = CarSensor_Data.CustomerKey and CarSensor_Data.Speed > 35
ORDER BY CarSensor_Data.Speed DESC
OPTION (FORCE EXTERNALPUSHDOWN); -- or OPTION (DISABLE EXTERNALPUSHDOWN)
データの インポート
次のクエリでは、外部データを SQL Server にインポートします。 この例では、高速走行しているドライバーのデータを、さらに詳細な分析を実行するために SQL Server にインポートします。 パフォーマンスを上げるため、サンプルでは列ストア インデックスが使用されています。
SELECT DISTINCT
Insured_Customers.FirstName, Insured_Customers.LastName,
Insured_Customers.YearlyIncome, Insured_Customers.MaritalStatus
INTO Fast_Customers from Insured_Customers INNER JOIN
(
SELECT * FROM CarSensor_Data where Speed > 35
) AS SensorD
ON Insured_Customers.CustomerKey = SensorD.CustomerKey
ORDER BY YearlyIncome
CREATE CLUSTERED COLUMNSTORE INDEX CCI_FastCustomers ON Fast_Customers;
データのエクスポート
次のクエリは、SQL Server から Hadoop にデータをエクスポートします。 これを行うには、先に PolyBase のエクスポートを有効にする必要があります。 次に、データをエクスポートする前に、エクスポート先の外部テーブルを作成します。
-- Enable INSERT into external table
sp_configure 'allow polybase export', 1;
reconfigure
-- Create an external table.
CREATE EXTERNAL TABLE [dbo].[FastCustomers2009] (
[FirstName] char(25) NOT NULL,
[LastName] char(25) NOT NULL,
[YearlyIncome] float NULL,
[MaritalStatus] char(1) NOT NULL
)
WITH (
LOCATION='/old_data/2009/customerdata',
DATA_SOURCE = HadoopHDP2,
FILE_FORMAT = TextFileFormat,
REJECT_TYPE = VALUE,
REJECT_VALUE = 0
);
-- Export data: Move old data to Hadoop while keeping it query-able via an external table.
INSERT INTO dbo.FastCustomer2009
SELECT T.* FROM Insured_Customers T1 JOIN CarSensor_Data T2
ON (T1.CustomerKey = T2.CustomerKey)
WHERE T2.YearMeasured = 2009 and T2.Speed > 40;
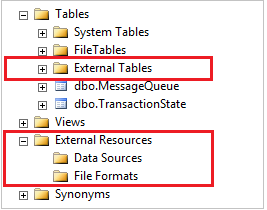
SSMS での PolyBase オブジェクトの表示
SSMS では、外部テーブルが別のフォルダー [外部テーブル]に表示されます。 外部データ ソースおよび外部ファイル形式は、 [外部リソース]の下のサブフォルダーにあります。
次のステップ
さまざまなデータ ソースへの外部データ ソースと外部テーブルの作成に関するその他のチュートリアルについては、「PolyBase Transact-SQL リファレンス」を参照してください。
次の記事を参照して、PolyBase を使用して監視するための方法をさらに調べます。