データベース ファイルとファイル グループ
適用対象: ![]() SQL Server
SQL Server ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
SQL Server の各データベースには、データ ファイルとログ ファイルという少なくとも 2 つのオペレーティング システム ファイルがあります。 データ ファイルには、テーブル、インデックス、ストアド プロシージャ、およびビューなどのデータおよびオブジェクトが含まれます。 ログ ファイルには、データベース内のすべてのトランザクションを復旧するために必要な情報が含まれます。 データ ファイルは、割り当てと管理の目的でファイル グループにまとめることができます。
データベース ファイル
SQL Server データベースには、次の表で示すように 3 種類のファイルがあります。
| ファイル | 説明 |
|---|---|
| プライマリ | データベースの起動情報が含まれており、データベース内の他のファイルを指し示します。 各データベースには 1 つのプライマリ データ ファイルがあります。 プライマリ データ ファイルに推奨されるファイル名拡張子は .mdf です。 |
| セカンダリ | 省略可能なユーザー定義データ ファイル。 各ファイルを異なるディスク ドライブに配置することにより、複数のディスクにデータを分散できます。 セカンダリ データ ファイルに推奨されるファイル名拡張子は .ndf です。 |
| トランザクション ログ | このログには、データベースの復旧に使用するログ情報が格納されます。 1 つのデータベースにトランザクション ログ ファイルが少なくとも 1 つ必要です。 トランザクション ログに推奨されるファイル名拡張子は .ldf です。 |
たとえば、Sales という単純なデータベースには、データとオブジェクトをすべて格納するプライマリ ファイルが 1 つと、トランザクション ログ情報を格納するログ ファイルが 1 つ含まれます。 プライマリ ファイルを 1 つとセカンダリ ファイルを 5 つ含む Orders というより複雑なデータベースを作成できます。 データベース内のデータとオブジェクトは 6 つすべてのファイルに分散され、4 つのログ ファイルにトランザクション ログ情報が含まれます。
既定では、単一ディスク システムを処理するため、データとトランザクション ログは同一のドライブおよびパス上に配置されます。 この選択は、実稼働環境では最適ではない場合があります。 そのため、データとログ ファイルは別のディスクに配置することをお勧めします。
論理ファイル名と物理ファイル名
SQL Server ファイルにはファイル名の種類が 2 つあります。
logical_file_name:logical_file_nameは、すべての Transact-SQL ステートメントで物理ファイルを参照するために使用する名前です。 論理ファイル名は、SQL Server の識別子の規則に従っている必要があります。また、データベース内の論理ファイル名は互いに一意にする必要があります。os_file_name:os_file_nameは、ディレクトリ パスを含む物理ファイルの名前です。 この名前はオペレーティング システムのファイル名の規則に従っている必要があります。
NAME および FILENAME 引数の詳細については、「ALTER DATABASE の File および Filegroup オプション (Transact-SQL)」を参照してください。
ヒント
SQL Server のデータとログ ファイルは、FAT または NTFS のいずれかのファイル システムに配置できます。 Windows システムの場合、NTFS のセキュリティの方が強力なので、Microsoft は NTFS ファイル システムを使用することをお勧めします。
警告
読み取りまたは書き込みデータ ファイル グループとログ ファイルは、NTFS 圧縮ファイル システムではサポートされていません。 圧縮された NTFS ファイル システムに配置できるのは、読み取り専用データベースと読み取り専用セカンダリ ファイル グループだけです。 領域を節約するために、ファイル システムの圧縮ではなく、データの圧縮を強くお勧めします。
1 台のコンピューターで SQL Server の複数のインスタンスを実行すると、インスタンスごとに異なる既定のディレクトリが与えられ、そのインスタンスで作成したデータベースのファイルがそのディレクトリで保持されます。 詳細については、「 SQL Server の既定のインスタンスおよび名前付きインスタンスのファイルの場所」を参照してください。
データ ファイルのページ
SQL Server のデータ ファイルのページには、ファイル内の最初のページを 0 として、順に番号が付けられています。 データベース内の各ファイルには一意のファイル ID 番号が付けられています。 データベース内のページを一意に識別するには、ファイル ID とページ番号の両方が必要です。 次の例は、4 MB のプライマリ データ ファイルと 1 MB のセカンダリ データ ファイルがあるデータベースのページ番号を示しています。
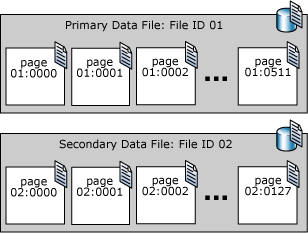
ファイル ヘッダー ページは、そのファイルの属性に関する情報が格納されている最初のページです。 また、ファイルの先頭にある数ページには、アロケーション マップなどのシステム情報が格納されています。 プライマリ データ ファイルと最初のログ ファイルの両方に格納されているシステム ページの 1 つは、データベースの属性情報が格納されているデータベース ブート ページです。
ファイル サイズ
SQL Server のファイルは、最初に指定したサイズから自動拡張するように設定できます。 ファイルを定義するときに、拡張の増分値を指定できます。 ファイルの空き容量がなくなるたびに、ファイルのサイズは指定した増分値だけ拡張されます。 ファイル グループに複数のファイルが存在する場合、すべてのファイルの空き容量がなくなるまで、ファイル グループ内のファイルは自動拡張しません。
ページとページの種類の詳細については、「ページとエクステントのアーキテクチャ ガイド」を参照してください。
各ファイルに最大サイズを指定することもできます。 最大サイズを指定しなかった場合、ファイルはディスクの空き領域を使い果たすまで拡張し続けます。 この機能は、ユーザーがシステム管理者と簡単に連絡を取れない状況にあり、SQL Server をアプリケーションに埋め込んだデータベースとして使用している場合に特に便利です。 ユーザーは、必要に応じてファイルを自動拡張するようにし、データベースの空き領域の監視や追加領域を手動で割り当てる管理上の負担を軽減できます。
トランザクション ログ ファイル管理の詳細については、「トランザクション ログ ファイルのサイズの管理」を参照してください。
データベース スナップショット ファイル
スナップショットがユーザーによって作成されるか、内部的に使用されるかに応じて、copy-on-write (書き込まれるたびにコピー) のデータを保存するためにデータベース スナップショットで使用されるファイル形式が決まります。
- ユーザーによって作成されるデータベース スナップショットでは、1 つまたは複数のスパース ファイルにデータを保存します。 スパース ファイル技術は NTFS ファイル システムの機能です。 初期状態のスパース ファイルにはユーザー データが含まれておらず、ユーザー データ用のディスク領域も割り当てられていません。 データベース スナップショットでのスパース ファイルの使用方法と、データベース スナップショットがどのように拡張されるかについては、「 データベース スナップショットのスパース ファイルのサイズを表示する方法 (Transact-SQL)」を参照してください。
- データベース スナップショットは特定の DBCC コマンドによって内部的に使用されます。 これらのコマンドには、
DBCC CHECKDB、DBCC CHECKTABLE、DBCC CHECKALLOCおよびDBCC CHECKFILEGROUPがあります。 内部データベース スナップショットでは、元のデータベース ファイルのスパース代替データ ストリームを使用します。 スパース ファイル同様、代替データ ストリームも NTFS ファイル システムの機能です。 スパース代替データ ストリームを使用すると、ファイル サイズやボリューム統計に影響を与えることなく、複数のデータ割り当てを単一のファイルまたはフォルダーに関連付けることができます。
ファイル グループ
- プライマリ ファイル グループには、プライマリ データ ファイル、および他のファイル グループに配置されていないセカンダリ ファイルが含まれます。
- ユーザー定義のファイル グループを作成して、データベースの管理、データの割り当て、および配置をしやすくするために、データ ファイルをグループ化できます。
たとえば、Data1.ndf、Data2.ndf、Data3.ndf をそれぞれ 3 つのディスク ドライブ上に作成し、ファイル グループ fgroup1 に割り当てることができます。 その後、ファイル グループ fgroup1 にテーブルを作成することができます。 このテーブル内にあるデータに対するクエリが 3 つのディスクにわたって分散されるため、パフォーマンスが向上します。 RAID (Redundant Array of Independent Disks) ストライプ セットにファイルを 1 つ作成しても、同じくらいパフォーマンスを向上させることができます。 ただし、ファイルとファイル グループを使用すれば、新しいファイルを新しいディスクに容易に追加できます。
すべてのデータ ファイルは、次の表に一覧表示されているファイル グループに格納されます。
| [ファイル グループ] | 説明 |
|---|---|
| プライマリ | プライマリ ファイルが含まれているファイル グループ。 すべてのシステム テーブルは、プライマリ ファイル グループの一部です。 |
| メモリ最適化データ | メモリ最適化ファイル グループは filestream ファイル グループに基づきます。 |
| FileStream | |
| ユーザー定義 | ユーザーがデータベースを最初に作成したとき、または後で変更したときに、ユーザーが作成したファイル グループ。 |
既定の (プライマリ) ファイル グループ
所属させるファイル グループを指定せずにデータベース内にオブジェクトを作成すると、そのオブジェクトは既定のファイル グループに割り当てられます。 どのような場合でも、必ず 1 つのファイル グループが既定のファイル グループとして指定されます。 既定のファイル グループ内のファイルは、他のファイル グループに割り当てられない新しいオブジェクトを十分に格納できる大きさである必要があります。
PRIMARY ファイル グループは、ALTER DATABASE ステートメントを使用して変更しない限り、既定のファイル グループです。 システム オブジェクトとシステム テーブルは、変更後の既定のファイル グループではなく、引き続き PRIMARY ファイル グループに格納されます。
メモリ最適化データ ファイル グループ
メモリ最適化ファイル グループの詳細については、「メモリ最適化ファイル グループ」を参照してください。
FILESTREAM ファイル グループ
FILESTREAM ファイル グループの詳細については、「FILESTREAM」と「FILESTREAM が有効なデータベースを作成する」を参照してください。
ファイルおよびファイル グループの例
次の例では、SQL Server のインスタンスにデータベースを作成します。 このデータベースにはプライマリ データ ファイル、ユーザー定義のファイル グループ、およびログ ファイルが含まれます。 プライマリ データ ファイルはプライマリ ファイル グループ内にあり、ユーザー定義ファイル グループには 2 つのセカンダリ データ ファイルがあります。 ALTER DATABASE ステートメントにより、このユーザー定義のファイル グループは既定のファイル グループになります。 その後、ユーザー定義のファイル グループを指定してテーブルを作成します。 (この例では、SQL Server のバージョンの指定を回避するため、一般的なパス c:\Program Files\Microsoft SQL Server\MSSQL.1 を使用しています。)
USE master;
GO
-- Create the database with the default data
-- filegroup, filestream filegroup and a log file. Specify the
-- growth increment and the max size for the
-- primary data file.
CREATE DATABASE MyDB
ON PRIMARY
( NAME='MyDB_Primary',
FILENAME=
'c:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB_Prm.mdf',
SIZE=4MB,
MAXSIZE=10MB,
FILEGROWTH=1MB),
FILEGROUP MyDB_FG1
( NAME = 'MyDB_FG1_Dat1',
FILENAME =
'c:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB_FG1_1.ndf',
SIZE = 1MB,
MAXSIZE=10MB,
FILEGROWTH=1MB),
( NAME = 'MyDB_FG1_Dat2',
FILENAME =
'c:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB_FG1_2.ndf',
SIZE = 1MB,
MAXSIZE=10MB,
FILEGROWTH=1MB),
FILEGROUP FileStreamGroup1 CONTAINS FILESTREAM
( NAME = 'MyDB_FG_FS',
FILENAME = 'c:\Data\filestream1')
LOG ON
( NAME='MyDB_log',
FILENAME =
'c:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB.ldf',
SIZE=1MB,
MAXSIZE=10MB,
FILEGROWTH=1MB);
GO
ALTER DATABASE MyDB
MODIFY FILEGROUP MyDB_FG1 DEFAULT;
GO
-- Create a table in the user-defined filegroup.
USE MyDB;
CREATE TABLE MyTable
( cola int PRIMARY KEY,
colb char(8) )
ON MyDB_FG1;
GO
-- Create a table in the filestream filegroup
CREATE TABLE MyFSTable
(
cola int PRIMARY KEY,
colb VARBINARY(MAX) FILESTREAM NULL
)
GO
次の図は、上の例の結果をまとめたものです (filestream データを除く)。

ファイルとファイル グループのフィル戦略
ファイル グループには、ファイル グループ内のすべてのファイルを対象として、各ファイルの空き領域に比例したデータ格納方法が使用されます。 SQL Server データベースは、データをファイル グループに書き込む際には、最初のファイルがいっぱいになるまでそのファイルにすべてのデータを書き込むのではなく、ファイル内の空き領域に比例してファイル グループ内の各ファイルにデータを書き込みます。 その後で、次のファイルにデータを書き込みます。 たとえば、ファイル f1 の空き領域が 100 MB で、ファイル f2 の空き領域が 200 MB の場合、ファイル f1 のエクステント 1 つとファイル f2 のエクステント 2 つが割り当てられます。 これにより、2 つのファイルがほぼ同時にいっぱいになり、簡易ストライピングが実現されます。
たとえば、1 つのファイル グループが 3 つのファイルから構成されていて、すべてのファイルが自動拡張されるように設定されているとします。 ファイル グループ内のすべてのファイルの領域がいっぱいになると、最初のファイルだけが拡張されます。 最初のファイルがいっぱいになり、ファイル グループにデータが書き込めなくなると、2 番目のファイルが拡張されます。 2 番目のファイルがいっぱいになり、ファイル グループにデータが書き込めなくなると、3 番目のファイルが拡張されます。 3 番目のファイルがいっぱいになり、ファイル グループにデータが書き込めなくなると、最初のファイルが再度拡張され、その後データの書き込み領域がなくなると順次各ファイルの拡張が行われます。
ファイルとファイル グループのデザインに関する規則
ファイルとファイル グループに関連する規則は次のとおりです。
- 1 つのファイルまたはファイル グループを複数のデータベースで使用することはできません。 たとえば、sales データベース内のデータとオブジェクトが格納されているファイル
sales.mdfとsales.ndfを他のデータベースが使用することはできません。 - ファイルは 1 つのファイル グループにしか所属できません。
- トランザクション ログ ファイルをファイル グループに格納することはできません。
推奨事項
ファイルとファイル グループを使用する場合の推奨事項:
- 大部分のデータベースは、1 つのデータ ファイルと 1 つのトランザクション ログ ファイルで正常に機能します。
- 複数のデータ ファイルを使用する場合は、追加ファイル用に 2 番目のファイル グループを作成し、既定のファイル グループとして設定します。 これにより、プライマリ ファイルにはシステム テーブルとシステム オブジェクトだけが格納されます。
- パフォーマンスを最適化するには、できるだけ、使用可能な異なるディスクにファイルまたはファイル グループを作成します。 また、大きな記憶域を占有する可能性のあるオブジェクトは、別々のファイル グループに配置します。
- ファイル グループを使用すると、特定の物理ディスク上にオブジェクトを配置できます。
- 同じ結合クエリで使用する各テーブルは別のファイル グループに配置してください。 この手順により、結合されるデータが並列ディスク I/O によって検索されるので、パフォーマンスが向上します。
- アクセス頻度が高いテーブルとそれらのテーブルに属する非クラスター化インデックスは、別々のファイル グループに配置してください。 異なるファイル グループを使用すると、ファイルが別の物理ディスク上にある場合に並列 I/O が行われるので、パフォーマンスが向上します。
- トランザクション ログ ファイルは、他のファイルやファイル グループと同じ物理ディスク上に配置しないでください。
- Diskpart などのツールを使用して、データベース ファイルが存在するボリュームまたはパーティションを拡張する必要がある場合は、まず、すべてのシステム データベースとユーザー データベースをバックアップし、SQL Server サービスを停止してください。 また、ディスク ボリュームが正常に拡張されたら、
DBCC CHECKDBコマンドを実行して、ボリューム上にあるすべてのデータベースの物理的な整合性を確保することを検討してください。
トランザクション ログ ファイル管理の推奨事項については、「トランザクション ログ ファイルのサイズの管理」を参照してください。