チュートリアル:SQL 機械学習を使用して R でクラスタリング モデルをビルドする
適用対象: ![]() SQL Server 2016 (13.x) 以降
SQL Server 2016 (13.x) 以降 ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
この 4 部構成のチュートリアル シリーズのパート 3 では、クラスタリングを実行するために、R で K-Means モデルをビルドします。 このシリーズの次のパートでは、SQL Server Machine Learning Services またはビッグ データ クラスターを使用して、このモデルをデータベースにデプロイします。
この 4 部構成のチュートリアル シリーズのパート 3 では、クラスタリングを実行するために、R で K-Means モデルをビルドします。 このシリーズの次の部では、SQL Server Machine Learning Services を使用して、このモデルをデータベースにデプロイします。
この 4 部構成のチュートリアル シリーズのパート 3 では、クラスタリングを実行するために、R で K-Means モデルをビルドします。 このシリーズの次のパートでは、SQL Server R Services を使用して、このモデルをデータベースにデプロイします。
この 4 部構成のチュートリアル シリーズのパート 3 では、クラスタリングを実行するために、R で K-Means モデルをビルドします。 このシリーズの次の部では、Azure SQL Managed Instance Machine Learning Services を使用し、データベースにこのモデルをデプロイします。
この記事では、次の方法について学習します。
- K-Means アルゴリズムのクラスター数を定義する
- クラスタリングを実行する
- 結果を分析する
パート 1 では、前提条件をインストールしてサンプル データベースを復元しました。
パート 2 では、データベースからデータを準備してクラスタリングを実行する方法を学びました。
パート 4 では、新しいデータに基づいて R でクラスタリングを実行できるストアド プロシージャをデータベースに作成する方法について学びます。
前提条件
クラスターの数を定義する
顧客データのクラスター化には、データをグループ化する最も単純かつ有名な方法の 1 つ、K-Means クラスタリング アルゴリズムを使用します。 K-Means の詳細については、K-means クラスタリング アルゴリズムの詳細ガイドに関するページを参照してください。
このアルゴリズムでは、次の 2 つの入力を受け取ります。データ自体、および定義済みの数値 "k" は、生成するクラスターの数を表します。 出力は、クラスター間でパーティション分割された入力データを持つ k クラスターとなっています。
アルゴリズムで使用するクラスターの数を決定するには、抽出されたクラスターの数によって、グループ内の平方和のプロットを使用します。 使用するクラスターの数は、プロットの曲がっている部分または "カギ" の部分になります。
# Determine number of clusters by using a plot of the within groups sum of squares,
# by number of clusters extracted.
wss <- (nrow(customer_data) - 1) * sum(apply(customer_data, 2, var))
for (i in 2:20)
wss[i] <- sum(kmeans(customer_data, centers = i)$withinss)
plot(1:20, wss, type = "b", xlab = "Number of Clusters", ylab = "Within groups sum of squares")
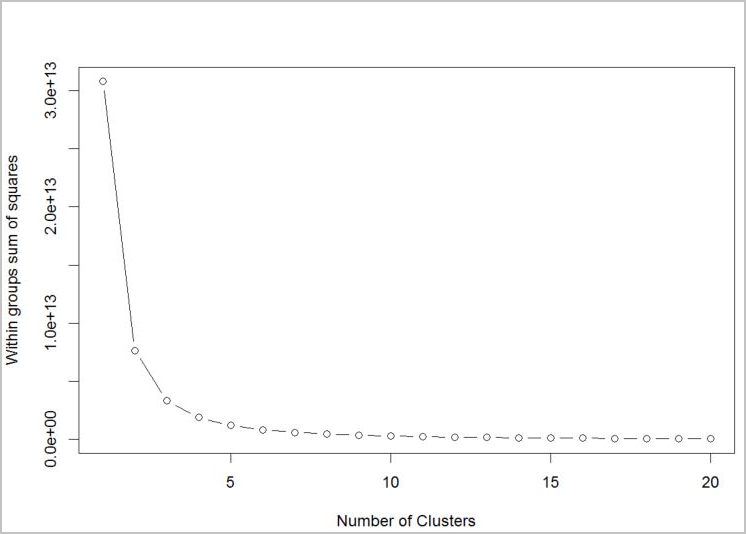
グラフに基づいて、k = 4 の値をまず試します。 k 値は、顧客を 4 つのクラスターにグループ化します。
クラスタリングを実行する
次の R スクリプトでは、関数 kmeans を使用して、クラスタリングを実行します。
# Output table to hold the customer group mappings.
# Generate clusters using Kmeans and output key / cluster to a table
# called return_cluster
## create clustering model
clust <- kmeans(customer_data[,2:5],4)
## create clustering output for table
customer_cluster <- data.frame(cluster=clust$cluster,customer=customer_data$customer,orderRatio=customer_data$orderRatio,
itemsRatio=customer_data$itemsRatio,monetaryRatio=customer_data$monetaryRatio,frequency=customer_data$frequency)
## write cluster output to DB table
sqlSave(ch, customer_cluster, tablename = "return_cluster")
# Read the customer returns cluster table from the database
customer_cluster_check <- sqlFetch(ch, "return_cluster")
head(customer_cluster_check)
結果を分析する
K-Means を使用してクラスタリングを実行したので、次の手順は、結果を分析してアクションにつながる情報を得られるか確認することです。
#Look at the clustering details to analyze results
clust[-1]
$centers
orderRatio itemsRatio monetaryRatio frequency
1 0.621835791 0.1701519 0.35510836 1.009025
2 0.074074074 0.0000000 0.05886575 2.363248
3 0.004807692 0.0000000 0.04618708 5.050481
4 0.000000000 0.0000000 0.00000000 0.000000
$totss
[1] 40191.83
$withinss
[1] 19867.791 215.714 660.784 0.000
$tot.withinss
[1] 20744.29
$betweenss
[1] 19447.54
$size
[1] 4543 702 416 31675
$iter
[1] 3
$ifault
[1] 0
4 つのクラスターは、パート 2 で定義した変数を使用して指定されます。
- orderRatio = 注文返品率 (注文の総数に対する部分的または完全に返品された注文の総数)
- itemsRatio = アイテム返品率 (購入されたアイテムの総数に対する返品されたアイテムの総数)
- monetaryRatio = 返品金額率 (合計購入金額に対する返されたアイテムの合計金額)
- frequency = 返品の頻度
多くの場合、K-Means を使用したデータ マイニングでは結果をさらに詳しく分析し、各クラスターについて理解を深めるためにさらに手順を進める必要がありますが、これにより良いスタートを切ることができるようになります。 これらの結果を解釈するいくつかの方法を次に示します。
- クラスター 1 (もっとも大きいクラスター) はアクティブでない顧客グループであると考えられます (すべての値が 0)。
- クラスター 3 は、戻り値の動作の観点では目立つグループであるように見えます。
リソースをクリーンアップする
このチュートリアルを続行しない場合は、tpcxbb_1gb データベースを削除してください。
次のステップ
このチュートリアル シリーズのパート 3 で学習した内容は次のとおりです。
- K-Means アルゴリズムのクラスター数を定義する
- クラスタリングを実行する
- 結果を分析する
作成した機械学習モデルをデプロイするには、このチュートリアル シリーズのパート 4 の手順に従います。