チュートリアル: HPE Serviceguard for Linux を使用して 3 ノード Always On 可用性グループをセットアップする
適用対象: ![]() SQL Server - Linux
SQL Server - Linux
このチュートリアルでは、オンプレミスの仮想マシン (VM) または Azure ベースの仮想マシンで実行されている HPE Serviceguard for Linux を使用して SQL Server 可用性グループを構成する方法について説明します。
HPE Serviceguard クラスターの概要については、HPE Serviceguard クラスターに関する記事を参照してください。
Note
Microsoft では、データ移動、可用性グループ、および SQL Server コンポーネントをサポートしています。 HPE Serviceguard クラスターとクォーラム管理のドキュメントに関するサポートについては、HPE にお問い合わせください。
このチュートリアルは、次のタスクで構成されています。
- 可用性グループに含める 3 つのすべての VM に SQL Server をインストールする
- VM に HPE Serviceguard をインストールする
- HPE Serviceguard クラスターを作成する
- Azure Portal でロード バランサーを作成する
- 可用性グループを作成し、その可用性グループにサンプル データベースを追加する
- Serviceguard クラスター マネージャーを使用して可用性グループに SQL Server ワークロードを展開する
- 自動フェールオーバーを実行し、ノードをクラスターに再び参加させる
前提条件
Azure で、Linux ベースの VM (仮想マシン) を 3 つ作成します。 Azure で Linux ベースの仮想マシンを作成するには、「クイックスタート: Azure portal で Linux 仮想マシンを作成する」を参照してください。 VM をデプロイする際には、必ず、HPE Serviceguard でサポートされている Linux ディストリビューションを使用してください。 なお、必要に応じて、オンプレミス環境で VM をローカルにデプロイすることもできます。
サポートされているディストリビューションの例については、「HPE Serviceguard for Linux」を参照してください。 パブリック クラウド環境のサポートについては、HPE に関する情報を確認してください。
このチュートリアルの手順は、HPE Serviceguard for Linux に対して検証されています。 試用版は HPE からダウンロードできます。
3 つのすべての仮想マシンに対する論理ボリューム マウント (LVM) 上の SQL Server データベース ファイル。 Serviceguard Linux (HPE) のクイック スタート ガイドを参照してください。
VM に OpenJDK Java ランタイムがインストールされていることを確認してください。 IBM Java SDK はサポートされていません。
SQL Server をインストールする
3 つのすべての VM で、このチュートリアルで選択した Linux ディストリビューションに基づいて、次のいずれかの手順に従って SQL Server とツールをインストールします。
Red Hat Enterprise Linux (RHEL)
SUSE Linux Enterprise Server (SLES)
この手順を完了すると、可用性グループに参加する 3 つのすべての VM に SQL Server サービスおよびツールがインストールされます。
VM に HPE Serviceguard をインストールする
この手順では、3 つのすべての VM に HPE Serviceguard for Linux をインストールします。 次の表では、各サーバーがクラスターで果たすロールについて説明します。
| [Number of VMs](VM の数) | HPE Serviceguard ロール | Microsoft SQL Server 可用性グループのレプリカ ロール |
|---|---|---|
| 1 | HPE Serviceguard クラスター ノード | プライマリ レプリカ |
| 1 つ以上 | HPE Serviceguard クラスター ノード | セカンダリ レプリカ |
| 1 | HPE Serviceguard クォーラム サーバー | 構成専用レプリカ |
Note
HPE のこのビデオを参照してください。このビデオでは、UI を使用して HPE Serviceguard クラスターをインストールして構成する方法について説明しています。
Serviceguard をインストールするには、cminstaller メソッドを使用します。 具体的な手順については、以下のリンクを参照してください。
- 2 つのノードに Serviceguard for Linux をインストールします。 「Install_serviceguard_using_cminstaller」セクションを参照してください。
- 3 番目のノードに Serviceguard クォーラム サーバーをインストールします。 「Install_QS_from_the_ISO」セクションを参照してください。
HPE Serviceguard クラスターのインストールが完了したら、プライマリ レプリカ ノード上の TCP ポート 5522 でクラスター管理ポータルを有効にすることができます。 次の手順では、5522 を許可する規則をファイアウォールに追加します。 次のコマンドは Red Hat Enterprise Linux (RHEL) 用で、 その他の配布ファイルには同様のコマンドを実行する必要があります。
sudo firewall-cmd --zone=public --add-port=5522/tcp --permanent
sudo firewall-cmd --reload
HPE Serviceguard クラスターを作成する
HPE Serviceguard クラスターを構成と作成するには、次の手順に従ってください。 この手順では、クォーラム サーバーも構成します。
- 3 番目のノードで Serviceguard クォーラム サーバーを構成します。 「Configure_QS」セクションを参照してください。
- 他の 2 つのノードで Serviceguard クラスターを構成して作成します。 「Configure_and_create_Cluster」セクションを参照してください。
注意
VM を作成するときに、AZURE VM マーケットプレースから HPE Serviceguard for Linux (SGLX) 拡張機能を追加することで、HPE Serviceguard クラスターとクォーラムの手動インストールをバイパスできます。
可用性グループを作成し、サンプル データベースを追加する
この手順では、2 つ (以上) の同期レプリカと構成専用レプリカを持つ可用性グループを作成します。これにより、データ保護が提供され、また高可用性を提供することもできます。 次の図は、このアーキテクチャを表したものです。
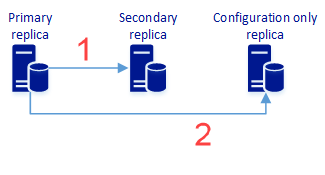
セカンダリ レプリカへのユーザー データの同期レプリケーションです。 これには、可用性グループの構成メタデータも含まれます。
可用性グループの構成メタデータの同期レプリケーションです。 これには、ユーザー データは含まれません。
詳細については、「2 つの同期レプリカと 1 つの構成専用レプリカ」を参照してください。
可用性グループを作成するには、次の手順に従います。
- 構成専用レプリカを含むすべての VM で 可用性グループを有効にし、mssql-server を再起動します。
AlwaysOn_healthイベント セッションを有効にします (省略可能)- プライマリ VM で証明書を作成する
- セカンダリ サーバーで証明書を作成する
- レプリカにデータベース ミラーリング エンドポイントを作成する
- 可用性グループを作成する
- セカンダリ レプリカに参加する
- 可用性グループにデータベースを追加する
可用性グループを有効にして mssql-server を再起動する
SQL Server インスタンスをホストするすべてのノードで可用性グループを有効にします。 次に、mssql-server を再起動します。 3 つのすべてのノードで次のスクリプトを実行します。
sudo /opt/mssql/bin/mssql-conf
set hadr.hadrenabled 1 sudo systemctl restart mssql-server
AlwaysOn_health イベント セッションを有効にする (省略可能)
オプションで、AlwaysOn 可用性グループの拡張イベントを有効にすると、可用性グループのトラブルシューティング時の根本原因の診断に役立ちます。 SQL Server の各インスタンスで次のコマンドを実行します。
ALTER EVENT SESSION AlwaysOn_health ON SERVER WITH (STARTUP_STATE=ON);
GO
プライマリ VM で証明書を作成する
次の Transact-SQL スクリプトでは、マスター キーと証明書を作成します。 その後、証明書をバックアップし、秘密キーでファイルをセキュリティ保護します。 強力なパスワードでスクリプトを更新してください。 プライマリ SQL Server インスタンスに接続し、次の Transact-SQL スクリプトを実行します。
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<Master_Key_Password>';
CREATE CERTIFICATE dbm_certificate WITH SUBJECT = 'dbm';
BACKUP CERTIFICATE dbm_certificate TO FILE = '/var/opt/mssql/data/dbm_certificate.cer'
WITH PRIVATE KEY
( FILE = '/var/opt/mssql/data/dbm_certificate.pvk',
ENCRYPTION BY PASSWORD = '<Private_Key_Password>' );
この時点で、プライマリ SQL Server レプリカの /var/opt/mssql/data/dbm_certificate.cer には証明書が、var/opt/mssql/data/dbm_certificate.pvk には秘密キーが作成されています。 これら 2 つのファイルは、可用性レプリカをホストするすべてのサーバーの同じ場所にコピーします。 mssql ユーザーを使用するか、または mssql ユーザーにこれらのファイルへのアクセス許可を付与します。
たとえば、ソース サーバーでは、次のコマンドでファイルがターゲット コンピューターにコピーされます。 node2 の値を、セカンダリ SQL Server インスタンスを実行しているホストの名前に置き換えます。 同様に、構成専用レプリカの証明書をコピーし、そのノードで次のコマンドを実行します。
cd /var/opt/mssql/data
scp dbm_certificate.* root@<node2>:/var/opt/mssql/data/
次に、セカンダリ インスタンスを実行しているセカンダリ VM、および SQL Server の構成専用レプリカで、次のコマンドを実行します。これにより、mssql ユーザーは、コピーされた証明書を所有できます。
cd /var/opt/mssql/data
chown mssql:mssql dbm_certificate.*
セカンダリ サーバーで証明書を作成する
次の Transact-SQL スクリプトでは、プライマリ SQL Server レプリカで作成したバックアップからマスター キーと証明書を作成します。 強力なパスワードでスクリプトを更新してください。 暗号化解除パスワードは、前の手順で .pvk ファイルの作成に使ったものと同じパスワードです。 証明書を作成するには、構成専用レプリカを除くすべてのセカンダリ サーバーで次のスクリプトを実行します。
CREATE MASTER KEY ENCRYPTION BY PASSWORD =
'<Master_Key_Password>';
CREATE CERTIFICATE dbm_certificate FROM FILE =
'/var/opt/mssql/data/dbm_certificate.cer'
WITH PRIVATE KEY ( FILE = '/var/opt/mssql/data/dbm_certificate.pvk',
DECRYPTION BY PASSWORD = '<Private_Key_Password>' );
レプリカにデータベース ミラーリング エンドポイントを作成する
プライマリおよびセカンダリ レプリカで次のコマンドを実行して、データベース ミラーリング エンドポイントを作成します。
CREATE ENDPOINT [hadr_endpoint] AS TCP (LISTENER_PORT = 5022)
FOR DATABASE_MIRRORING
(
ROLE = WITNESS,
AUTHENTICATION = CERTIFICATE dbm_certificate,
ENCRYPTION = REQUIRED ALGORITHM AES
);
ALTER ENDPOINT [hadr_endpoint] STATE = STARTED;
注意
5022 は、データベース ミラーリング エンドポイントで使用される標準ポートですが、使用可能な任意のポートに変更することができます。
構成専用レプリカで、以下のコマンドを使用してデータベース ミラーリング エンドポイントを作成します。ここでは、役割の値が WITNESS に設定されていることに注意してください。構成専用レプリカにはこのように設定する必要があります。
CREATE ENDPOINT [hadr_endpoint] AS TCP (LISTENER_PORT = 5022)
FOR DATABASE_MIRRORING (
ROLE = WITNESS,
AUTHENTICATION = CERTIFICATE dbm_certificate,
ENCRYPTION = REQUIRED ALGORITHM AES
);
ALTER ENDPOINT [hadr_endpoint] STATE = STARTED;
可用性グループを作成する
プライマリ レプリカ インスタンスで、次のコマンドを実行します。 これらのコマンドにより、ag1 という名前の可用性グループが作成されます。これには EXTERNAL cluster_type が含まれており、この可用性グループにデータベースの作成アクセス許可が付与されます。
次のスクリプトを実行する前に、<node1>、<node2>、および <node3> (構成専用レプリカ) プレースホルダーを、前の手順で作成した VM の名前に置き換えます。
CREATE AVAILABILITY GROUP [ag1]
WITH (CLUSTER_TYPE = EXTERNAL)
FOR REPLICA ON
N'<node1>' WITH (
ENDPOINT_URL = N'tcp://<node1>:<5022>',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
),
N'<node2>' WITH (
ENDPOINT_URL = N'tcp://<node2>:\<5022>',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
),
N'<node3>' WITH (
ENDPOINT_URL = N'tcp://<node3>:<5022>',
AVAILABILITY_MODE = CONFIGURATION_ONLY
);
ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE;
セカンダリ レプリカに参加する
すべてのセカンダリ レプリカで次のコマンドを実行します。 これらのコマンドにより、セカンダリ レプリカがプライマリ レプリカと共に ag1 可用性グループに参加し、ag1 可用性グループにデータベースの作成アクセスが付与されます。
ALTER AVAILABILITY GROUP [ag1]
JOIN WITH (CLUSTER_TYPE = EXTERNAL);
GO
ALTER AVAILABILITY GROUP [ag1]
GRANT CREATE ANY DATABASE;
GO
可用性グループにデータベースを追加する
プライマリ レプリカに接続し、次の T-SQL コマンドを実行して、次の操作を実行します。
- 可用性グループに追加する
db1という名前のサンプル データベースを作成します。 - データベースの復旧モデルを full に設定します。 可用性グループ内のすべてのデータベースには、full 復旧モデルが必要です。
- データベースをバックアップします。 可用性グループにデータベースを追加するには、データベースに少なくとも 1 つの完全バックアップが必要です。
-- creates a database named db1
CREATE DATABASE [db1];
GO
-- set the database in full recovery model
ALTER DATABASE [db1] SET RECOVERY FULL;
GO
-- backs up the database to disk
BACKUP DATABASE [db1]
TO DISK = N'/var/opt/mssql/data/db1.bak';
GO
-- adds the database db1 to the AG
ALTER AVAILABILITY GROUP [ag1] ADD DATABASE [db1];
GO
前の手順が正常に完了すると、ag1 可用性グループが作成され、1 つのプライマリ レプリカ、1 つのセカンダリ レプリカ、1 つの構成専用レプリカを含むレプリカとして 3 つの VM が追加されます。 ag1 には、データベースが 1 つ含まれています。
SQL Server 可用性グループ ワークロードを展開する (HPE クラスター マネージャー)
HPE Serviceguard で、Serviceguard クラスター マネージャー UI を使用して可用性グループに SQL Server ワークロードを展開します。
Serviceguard マネージャーのグラフィカル ユーザー インターフェイスを使用して、可用性グループ ワークロードを展開し、高可用性 (HA)、Serviceguard クラスター経由でのディザスター リカバリー (DR) を有効にします。 Always On 可用性グループの Microsoft SQL Server on Linux の保護に関するセクションを参照してください。
Azure Portal でロード バランサーを作成する
Azure Cloud でのデプロイの場合、HPE Serviceguard for Linux では、プライマリ レプリカとのクライアント接続を有効にし、従来の IP アドレスを置き換えるためのロード バランサーが必要です。
Azure portal で、Serviceguard クラスター ノードまたは仮想マシンが含まれているリソース グループを開きます。
リソース グループで、 [追加] を選択します。
"ロード バランサー" を検索し、検索結果から、Microsoft によって発行された Load Balancer を選択します。
[Load Balancer] ペインで、[作成] を選択します。
ロード バランサーを次のように構成します。
設定 値 名前 ロード バランサー名。 たとえば、 SQLAvailabilityGroupLBのようにします。Type 内部 SKU Basic または Standard 仮想ネットワーク VM レプリカに使用される仮想ネットワーク サブネット SQL Server インスタンスがホストされているサブネット IP アドレスの割り当て 静的 プライベート IP アドレス サブネット内にプライベート IP を作成する サブスクリプション 該当するサブスクリプションを選択する リソース グループ 該当するリソース グループを選択する 場所 SQL ノードと同じ場所を選択する
バックエンド プールを構成する
バックエンド プールは、Serviceguard クラスターが構成されている 2 つのインスタンスのアドレスです。
- リソース グループで、作成したロード バランサーを選択します。
- [設定] > [バックエンド プール] の順に移動し、[追加] を選択してバックエンド アドレス プールを作成します。
- [名前] の下にある [バックエンド プールの追加] に、バックエンド プールの名前を入力します。
- [関連付け先] で、 [仮想マシン] を選択します。
- 環境内の仮想マシンを選択し、適切な IP アドレスを、選択した各仮想マシンに関連付けます。
- [追加] を選択します。
プローブを作成する
プローブでは、どの Serviceguard クラスター ノードがプライマリ レプリカであるかを Azure で検証する方法を定義します。 Azure は、プローブの作成時に定義されたポートで、IP アドレスに基づいてサービスをプローブします。
[ロード バランサーの設定] ペインで [正常性プローブ] を選択します。
[正常性プローブ] ペインで [追加] を選択します。
次の値を使用してプローブを構成します。
設定 値 名前 プローブを表すテキスト名。 たとえば、 SQLAGPrimaryReplicaProbeのようにします。プロトコル TCP [ポート] 空いている任意のポートを使用できます (例: 59999)。 間隔 5 異常のしきい値 2 [OK] を選択します。
すべての仮想マシンにサインインし、次のコマンドを使用してプローブ ポートを開きます。
sudo firewall-cmd --zone=public --add-port=59999/tcp --permanent sudo firewall-cmd --reload
Azure では、プローブを作成し、それを使用して、可用性グループのプライマリ レプリカ インスタンスが実行されている Serviceguard ノードをテストします。 構成したポート (59999) を忘れないでください。これは、Serviceguard クラスターに AG をデプロイするために必要です。
負荷分散規則を設定する
負荷分散規則では、ロード バランサーでトラフィックを Serviceguard ノード (クラスター内のプライマリ レプリカ) にルーティングする方法を構成します。 一度にプライマリ レプリカにすることができる Serviceguard クラスター ノードは 1 つのみであるため、このロード バランサーでは、Direct Server Return を有効にします。
[ロード バランサーの設定] ペインで [負荷分散規則] を選択します。
[負荷分散規則] ペインで、[追加] を選択します。
次の設定を使用して負荷分散規則を構成します。
設定 値 名前 負荷分散規則を表す名前。 たとえば、 SQLAGPrimaryReplicaListenerのようにします。プロトコル TCP [ポート] 1433 バックエンド ポート 1433。この規則ではフローティング IP を使用するため、この値は無視されます。 プローブ このロード バランサーに対して作成したプローブの名前を使用します。 セッション永続化 なし アイドル タイムアウト (分) 4 Floating IP Enabled [OK] を選択します。
負荷分散規則が Azure によって構成されます。 以上で、ロード バランサーは、クラスター内のプライマリ レプリカ インスタンスである Serviceguard ノードにトラフィックをルーティングするように構成されました。
ロード バランサーのフロントエンド IP アドレス "LbReadWriteIP" をメモしておきます。これは、Serviceguard クラスターに AG をデプロイするために必要です。
この時点で、リソース グループのロード バランサーがすべての Serviceguard ノードに接続されています。 ロード バランサーには、クラスター内のプライマリ レプリカ インスタンスに接続するクライアントの IP アドレスも含まれているため、どのマシンがプライマリ レプリカであっても、可用性グループに対する要求に応答できます。
自動フェールオーバーを実行し、ノードをクラスターに再び参加させる
自動フェールオーバー テストでは、プライマリ レプリカをダウンさせて (電源オフ)、プライマリ ノードの突然の停止をレプリケートできます。 予期される動作は次のとおりです。
- クラスター マネージャーにより、可用性グループ内のいずれかのセカンダリ レプリカがプライマリに昇格します。
- 失敗したプライマリ レプリカは、バックアップされた後に自動的にクラスターに参加します。 これは、クラスター マネージャーによってセカンダリ レプリカに昇格します。
HPE Serviceguard については、「Testing the setup for failover readiness」(フェールオーバーの準備のセットアップのテスト) セクションを参照してください。