Troubleshoot a pyspark notebook
Important
The Microsoft SQL Server 2019 Big Data Clusters add-on will be retired. Support for SQL Server 2019 Big Data Clusters will end on February 28, 2025. All existing users of SQL Server 2019 with Software Assurance will be fully supported on the platform and the software will continue to be maintained through SQL Server cumulative updates until that time. For more information, see the announcement blog post and Big data options on the Microsoft SQL Server platform.
This article demonstrates how to troubleshoot a pyspark notebook that fails.
Architecture of a PySpark job under Azure Data Studio
Azure Data Studio communicates with the livy endpoint on SQL Server Big Data Clusters.
The livy endpoint issues spark-submit commands within the big data cluster. Each spark-submit command has a parameter that specifies YARN as the cluster resource manager.
To efficiently troubleshoot your PySpark session you will collect and review logs within each layer: Livy, YARN and Spark.
This troubleshooting steps require that you have:
- Azure Data CLI (
azdata) installed and with configuration correctly set to your cluster. - Familiarity with running Linux commands and some log troubleshooting skills.
Troubleshooting steps
Review the stack and error messages in the
pyspark.Get the application ID from the first cell in the notebook. Use this application ID to investigate the
livy, YARN, and spark logs.SparkContextuses uses this YARN application ID.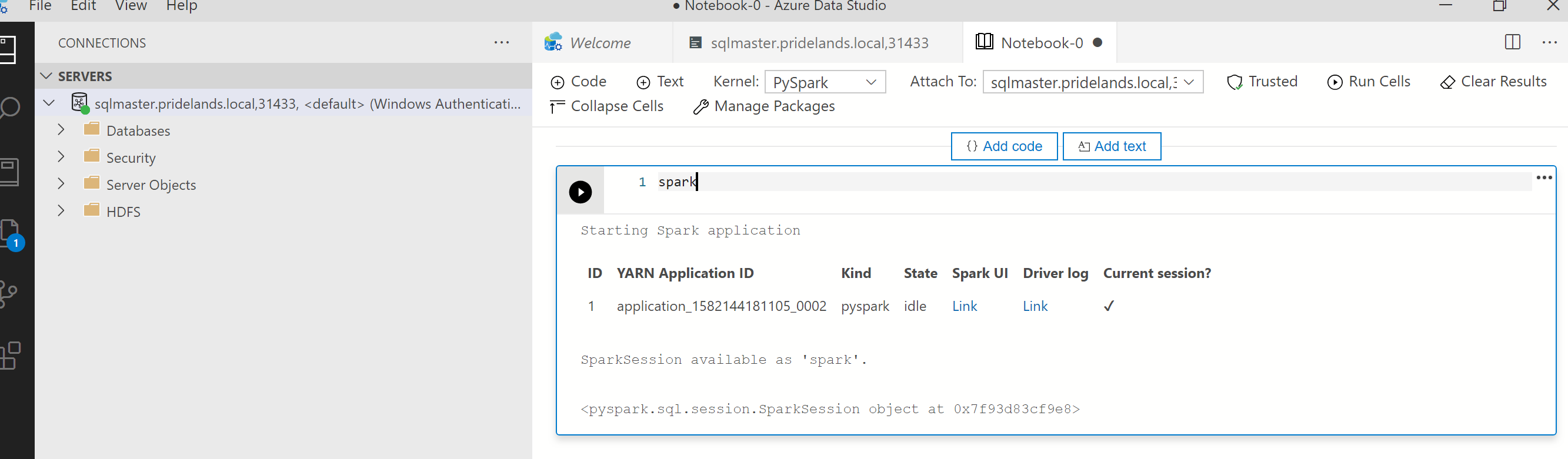
Get the logs.
Use
azdata bdc debug copy-logsto investigateThe following example connects a big data cluster endpoint to copy the logs. Update the following values in the example before running.
<ip_address>: Big data cluster endpoint<username>: Your big data cluster username<namespace>: The Kubernetes namespace for your cluster<folder_to_copy_logs>: The local folder path where you want your logs copied to
azdata login --auth basic --username <username> --endpoint https://<ip_address>:30080 azdata bdc debug copy-logs -n <namespace> -d <folder_to_copy_logs>Example output
<user>@<server>:~$ azdata bdc debug copy-logs -n <namespace> -d copy_logs Collecting the logs for cluster '<namespace>'. Collecting logs for containers... Creating an archive from logs-tmp/<namespace>. Log files are archived in /home/<user>/copy_logs/debuglogs-<namespace>-YYYYMMDD-HHMMSS.tar.gz. Creating an archive from logs-tmp/dumps. Log files are archived in /home/<user>/copy_logs/debuglogs-<namespace>-YYYYMMDD-HHMMSS-dumps.tar.gz. Collecting the logs for cluster 'kube-system'. Collecting logs for containers... Creating an archive from logs-tmp/kube-system. Log files are archived in /home/<user>/copy_logs/debuglogs-kube-system-YYYYMMDD-HHMMSS.tar.gz. Creating an archive from logs-tmp/dumps. Log files are archived in /home/<user>/copy_logs/debuglogs-kube-system-YYYYMMDD-HHMMSS-dumps.tar.gz.Review the Livy logs. The Livy logs are at
<namespace>\sparkhead-0\hadoop-livy-sparkhistory\supervisor\log.- Search for the YARN application ID from the pyspark notebook first cell.
- Search for
ERRstatus.
Example of Livy log that has a
YARN ACCEPTEDstate. Livy has submitted the yarn application.HH:MM:SS INFO utils.LineBufferedStream: YYY-MM-DD HH:MM:SS INFO impl.YarnClientImpl: Submitted application application_<application_id> YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: YYY-MM-DD HH:MM:SS INFO yarn.Client: Application report for application_<application_id> (state: ACCEPTED) YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: YYY-MM-DD HH:MM:SS INFO yarn.Client: YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: client token: N/A YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: diagnostics: N/A YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: ApplicationMaster host: N/A YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: ApplicationMaster RPC port: -1 YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: queue: default YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: start time: ############ YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: final status: UNDEFINED YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: tracking URL: https://sparkhead-1.fnbm.corp:8090/proxy/application_<application_id>/ YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: user: <account>Review the YARN UI
Get the YARN endpoint URL from the Azure Data Studio big data cluster management dashboard or run
azdata bdc endpoint list –o table.For example:
azdata bdc endpoint list -o tableReturns
Description Endpoint Name Protocol ------------------------------------------------------ ---------------------------------------------------------------- -------------------------- ---------- Gateway to access HDFS files, Spark https://knox.<namespace-value>.local:30443 gateway https Spark Jobs Management and Monitoring Dashboard https://knox.<namespace-value>.local:30443/gateway/default/sparkhistory spark-history https Spark Diagnostics and Monitoring Dashboard https://knox.<namespace-value>.local:30443/gateway/default/yarn yarn-ui https Application Proxy https://proxy.<namespace-value>.local:30778 app-proxy https Management Proxy https://bdcmon.<namespace-value>.local:30777 mgmtproxy https Log Search Dashboard https://bdcmon.<namespace-value>.local:30777/kibana logsui https Metrics Dashboard https://bdcmon.<namespace-value>.local:30777/grafana metricsui https Cluster Management Service https://bdcctl.<namespace-value>.local:30080 controller https SQL Server Master Instance Front-End sqlmaster.<namespace-value>.local,31433 sql-server-master tds SQL Server Master Readable Secondary Replicas sqlsecondary.<namespace-value>.local,31436 sql-server-master-readonly tds HDFS File System Proxy https://knox.<namespace-value>.local:30443/gateway/default/webhdfs/v1 webhdfs https Proxy for running Spark statements, jobs, applications https://knox.<namespace-value>.local:30443/gateway/default/livy/v1 livy httpsCheck the application ID and individual application_master and container logs.
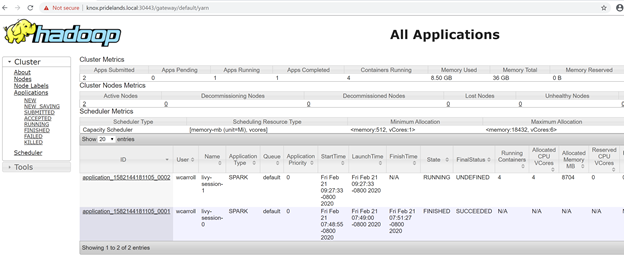
Review the YARN application logs.
Get application log for the app. Use
kubectlto connect to thesparkhead-0pod, for example:kubectl exec -it sparkhead-0 -- /bin/bashAnd then run this command within that shell using the right
application_id:yarn logs -applicationId application_<application_id>Search for errors or stacks.
An example of permission error against hdfs. In the java stack look for the
Caused by:YYYY-MM-DD HH:MM:SS,MMM ERROR spark.SparkContext: Error initializing SparkContext. org.apache.hadoop.security.AccessControlException: Permission denied: user=<account>, access=WRITE, inode="/system/spark-events":sph:<bdc-admin>:drwxr-xr-x at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:399) at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:255) at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:193) at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1852) at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1836) at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkAncestorAccess(FSDirectory.java:1795) at org.apache.hadoop.hdfs.server.namenode.FSDirWriteFileOp.resolvePathForStartFile(FSDirWriteFileOp.java:324) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFileInt(FSNamesystem.java:2504) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFileChecked(FSNamesystem.java:2448) Caused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.AccessControlException): Permission denied: user=<account>, access=WRITE, inode="/system/spark-events":sph:<bdc-admin>:drwxr-xr-xReview the SPARK UI.
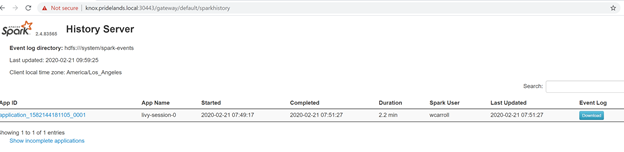
Drill down into the stages tasks looking for errors.
Next steps
Troubleshoot SQL Server Big Data Clusters Active Directory integration