SQL Server ビッグ データ クラスター で展開されたリソース
適用対象: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
重要
Microsoft SQL Server 2019 ビッグ データ クラスターのアドオンは廃止されます。 SQL Server 2019 ビッグ データ クラスターのサポートは、2025 年 2 月 28 日に終了します。 ソフトウェア アシュアランス付きの SQL Server 2019 を使用する既存の全ユーザーはプラットフォームで完全にサポートされ、ソフトウェアはその時点まで SQL Server の累積更新プログラムによって引き続きメンテナンスされます。 詳細については、お知らせのブログ記事と「Microsoft SQL Server プラットフォームのビッグ データ オプション」を参照してください。
この記事では、SQL Server ビッグ データ クラスターで展開されるリソースについて説明します。
ビッグ データ クラスターでは、展開プロファイルに基づいてポッドが展開されます。 詳細については、「既定の構成」を参照してください。
この記事では、aks-dev-test-ha プロファイルで展開されるポッドについて説明します。Spark プールが含まれています。 クラスターに展開されているポッドを確認するには、Kubernetes にクエリを実行します。 次の例では、特定の名前空間にあるポッドの一覧が返されます。
kubectl get pods -n <namespace>
<namespace> をビッグ データ クラスターの名前に置き換えます。
詳細については、「Kubernetes に SQL Server ビッグ データ クラスターを展開する方法」を参照してください。
次の図は、ビッグ データ クラスターに展開されたコンポーネントを示しています。
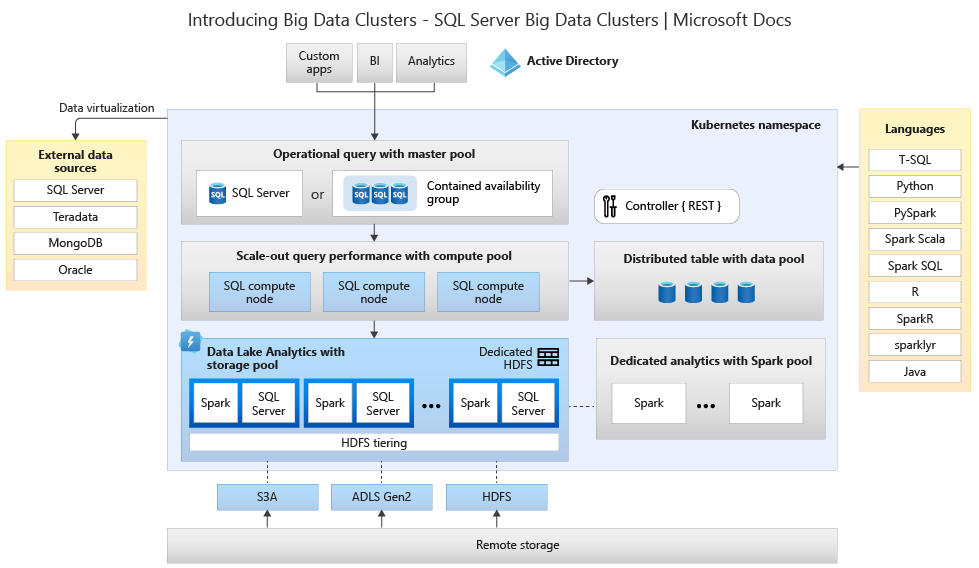
アーキテクチャの詳細については、「SQL Server ビッグ データ クラスター の概要」を参照してください。
展開されたポッド
次の表は、ビッグ データ クラスターに展開されたポッドを示しています。
| 名前 | 領域 |
|---|---|
control-<nnnn> |
コントロール |
controldb-<#> |
コントロール |
controlwd-<nnnn> |
コントロール |
logsdb-<#> |
コントロール |
logsui-<nnnn> |
コントロール |
metricsdb-<#> |
コントロール |
metricsdc-<nnnn> |
コントロール |
metricsui-<nnnn> |
コントロール |
mgmtproxy-<nnnn> |
コントロール |
zookeeper-<#> |
コントロール |
dns-<nnnn> |
コントロール |
master-<#n> |
マスター インスタンス |
operator-<nnnn> |
マスター インスタンス |
compute-<#n>-<#m> |
コンピューティング プール |
data-<#>-<#> |
データ プール |
storage-<#>-<#> |
記憶域プール |
nmnode-<#>-<#> |
記憶域プール |
sparkhead-<#> |
記憶域プール |
appproxy-<#m> |
アプリケーション プール |
gateway-<#> |
ゲートウェイ サービス |
すべてのビッグ データ クラスターにすべてのポッドが含まれているわけではありません。 高可用性または Active Directory 統合を使用する展開には、特定のポッドが含まれます。
高可用性に固有のポッド:
operator-<nnnn>zookeeper-<#>
Active Directory に固有のポッド:
dns-<nnnn>
次のセクションでは、ポッドについて説明し、各ポッドのコンテナーの一覧を示します。
コントロール
コントロール ポッドでは制御サービスが提供されます。
| ポッド名 | Count | Kubernetes コントローラーの種類 | Containers |
|---|---|---|---|
control-# |
1 | ReplicaSet | - controller- security-support- fluentbit |
controldb |
1 | StatefulSet | - mssql-server- fluentbit |
controlwd |
1 | ReplicaSet | - controlwatchdog |
logsdb-# |
1 | StatefulSet | - elasticsearch |
logsui |
1 | ReplicaSet | - kibana |
metricsdb-# |
1 | StatefulSet | - influxdb |
metricsdc |
Kubernetes ノードごとに 1 つ。 | DaemonSet | - telegraf |
metricsui-nnnn |
1 | ReplicaSet | - grafana |
mgmtproxy-nnnn |
1 | ReplicaSet | - service-proxy- fluentbit |
dns-nnnn |
Active Directory 統合の場合は 0 または 1 | ReplicaSet | - dns- fluentbit |
マスター インスタンス
master-<#n> は SQL Server マスター インスタンスです。
- DDL を使用してデータ プールを管理します
- DML を使用してデータ プール内のデータを操作します
- データ プールに対する分析クエリ実行をオフロードします
| ポッド名 | Count | Kubernetes コントローラーの種類 | Containers |
|---|---|---|---|
master-<#n> |
高可用性の場合は 1 つ以上。 | StatefulSet | - mssql-server- fluentbit- collectd- mssql-ha-supervisor * |
operator* |
高可用性の場合は 0 または 1 | ReplicaSet | - mssql-ha-operator |
* 高可用性の展開のみ。 オペレーターによって、SQL Server および可用性グループのリソースのカスタム リソース定義が実装され、登録されます。 オペレーターが展開されると、オペレーターによって、Kubernetes クラスターに展開された SQL Server リソースに関する通知のリスナーとしてオペレーター自身が登録されます。 mssql-ha-supervisor によって可用性グループがサポートされます。
各 master ポッドには、SQL Server のインスタンスが 1 つ含まれています。 高可用性の展開には 3 つのポッドが含まれます。 各ポッドには、SQL Server インスタンスと、SQL Server Always On 可用性グループ内のデータベースが含まれています。
展開時に、ワークロードに応じて追加のポッドを含めます。
計算プール
コンピューティング プールによって、コンピューティング用の SQL Server インスタンスが提供されます。
| ポッド名 | Count | Kubernetes コントローラーの種類 | Containers |
|---|---|---|---|
compute-<#n>-<#m> |
1 つ以上。 | StatefulSet | - mssql-server- fluentbit- collectd |
#nでコンピューティング プールを識別します。#mでプール内のインスタンス ID を識別します。
コンピューティング プール SQL Server インスタンスはステートレスです。 それらに必要なのは tempdb 用のストレージのみです。
展開時に、ワークロードに応じて追加のポッドを含めます。
データ プール
データ プールによって、ストレージとコンピューティングのための SQL Server インスタンスが提供されます。
| ポッド名 | Count | Kubernetes コントローラーの種類 | Containers |
|---|---|---|---|
data-<#n>-<#m> |
0 以上 | StatefulSet | - mssql-server - fluentbit- collectd |
#nでデータベース ロックを識別します。#mでプール内のインスタンス ID を識別します。
ワークロードに応じて、展開時に追加のポッドを含めます。
記憶域プール
記憶域プールによって、Spark を介したデータ インジェスト、HDFS 内のストレージ、HDFS と SQL Server エンドポイントを介したデータ アクセスが提供されます。
| ポッド名 | Count | Kubernetes コントローラーの種類 | Containers |
|---|---|---|---|
storage-0-# |
1 つ以上。 ワークロードに応じて、展開時に追加のポッドを含めます。 | StatefulSet | - hadoop- mssql-server- fluentbit |
nmnode-0-# |
高可用性の場合は 1 つ以上 | StatefulSet | - hadoop- fluentbit |
sparkehead-# |
高可用性の場合は 1 つ以上 | StatefulSet | - hadoop-yarn-jobhistory- hadoop-livy-sparkhistory- hadoop-hivemetastore-- fluentbit |
zookeeper |
高可用性の場合は 0 または 3。 | StatefulSet | - zookeeper- fluentbit |
アプリケーション プール
アプリケーション プールは、一部のテスト構成プロファイルに含まれています。 アプリケーション プールによって、ビッグ データ クラスター用のアプリケーションを展開するときに定義したアプリケーション サービス プロキシがホストされます。
appproxy は、アプリケーション プールのアプリケーションの前に置かれている Web API です。 それによってユーザーが認証された後、要求がアプリケーションにルーティングされます。
| ポッド名 | Kubernetes コントローラーの種類 | Containers |
|---|---|---|
appproxy |
ReplicaSet | - app-service-proxy- fluentbit |
詳細については、ビッグ データ クラスターでのアプリケーション展開の概要に関するページを参照してください。
ワークロードに応じて、展開時に追加のポッドを含めます。
ゲートウェイ サービス
ゲートウェイ サービスによって、Spark、HDFS、Yarn、Yarn UI、Spark UI への Knox ゲートウェイが提供されます。
| ポッド名 | Kubernetes コントローラーの種類 | Containers |
|---|---|---|
gateway-<#> |
StatefulSet | - knox- fluentbit |
1 つのゲートウェイだけがサポートされます。
オープンソースのコンテナー参照
特定のオープンソース プロジェクトとバージョンについては、「オープンソース ソフトウェア リファレンス」を参照してください。
次のステップ
SQL Server ビッグ データ クラスター の詳細については、次のリソースを参照してください。