FAST クエリ言語 (FQL) 構文のリファレンス
FAST クエリ言語 (FQL) を使用した SharePoint の検索 の複雑な検索クエリの構築について説明します。 このリファレンスでは、FQL クエリの要素について、および FQL クエリでプロパティーの指定、トークン式、および演算子を使用する方法について説明します。
SharePoint の FQL およびクエリ言語のサブ式と式の概要
FAST クエリ言語 (FQL) は、開発者が、完全一致の検索を実行したり、検索範囲を特定の管理プロパティまたはフルテキスト インデックスに属する値に狭めたりするのを可能にする強力なクエリ言語です。
クエリ言語式には、表 1 で説明するように、クエリ用語、プロパティの指定、および演算子を含む、ネストされたサブ式を含めることができます。
表 1. クエリ言語式のサブ式
| アイテム | 説明 |
|---|---|
| トークン式 | クエリで検索する、1 つ以上のクエリ用語、語句、または数値。 |
| プロパティの指定 | 関連する式と照合するプロパティまたはフルテキスト インデックス。 |
| 演算子 | ブール演算子 ( AND、 OR など) またはオペランドに対する他の制約 ( FILTER など) を指定するキーワード。 |
FQL クエリの例
以下の FQL クエリ例は、インデックス化されたアイテムの body 管理プロパティで、用語 "hello" と "world" を検索します。
body:string("hello world", mode="and")
例の中で:
-
body:は、クエリ範囲をアイテム内の body 管理プロパティに限定します。 -
"hello world"は、 STRING 演算子へのオペランドで、検索する用語を示します。 -
mode="and"は、論理クエリ演算子 AND が"hello world"に適用されることを示します。
FAST クエリ言語のクエリの長さは 2,048 文字に制限されています。
FQL でのプロパティの指定
プロパティの指定によって、関連する式の範囲が、インデックス付きコンテンツの特定領域に限定されます。 このような領域は、フルテキスト インデックスまたは管理プロパティによって特定できます。
Text 型および YesNo 型の管理プロパティは、テキストとして評価されます。 Datetime 型を含む他のすべての管理プロパティの型は、数値として評価されます。
式にプロパティの指定を含めない場合、検索エンジンは、インデックス スキーマで定義された既定のフルテキスト インデックスを照会しようとします。
プロパティの名前の後には必ずコロンを付ける必要があります ( In 演算子)。また数値演算子には必ずプロパティの指定が含まれます。
プロパティの指定 ( In 演算子) は、以下のクエリ エンティティに適用できます。
以下のような、1 つの用語または語句。
author:shakespeare title:"to be or not to be"以下のような演算子 ( STRING 演算子など)
title:string("to be or not to be")この場合、プロパティの指定は完全な演算子式に適用されます。
例
以下の各式は、 title 管理プロパティの "much" と "nothing" の両方を持つアイテムを照合します。
title:and(much, nothing)
and(title:much, title:nothing)
title:string("much nothing", mode="and")
FQL でのトークン式
トークン式は、インデックスに対して照合される単語、語句、または数値です。
テキスト トークン式は、二重引用符で囲まれた 1 つの単語または語句です。
数値トークン式は、1 つの値または値の範囲の式です。
ワイルドカード式
ワイルドカード式は、アスタリスク ("*") 文字を含む 1 つの用語または語句を示します。アスタリスクは、空白文字を除く 0 個以上の文字の一致を意味します。 FQL では、個々のテキスト管理プロパティとフルテキスト インデックスについてプレフィックス検索をサポートします。
ワイルドカード式の例
次に、FQL で有効なワイルドカード式の使用方法を示します。
text*string("this examp*")
数値用語の式
各数値用語の式には、互換性のあるインデックス スキーマのデータ型のプロパティ指定を入れる必要があります。 表 2 に、FQL で使用できる数値データ型を示します。
表 2. FQL で使用できる数値データ型
| FQL の型 | 互換性のあるインデックス スキーマの型 | 説明 |
|---|---|---|
| Int | Integer | 64 ビット整数。 |
| Float | Double | 64 ビット (倍精度) 浮動小数点。 |
| Decimal | Decimal | 128 ビット 10 進数 |
| Datetime | Datetime | 日付と時刻の値。 FQL で日付と時刻がサポートされるので、他の数値と同じ数値演算を日付と時刻の値に対して実行できます。 |
日付と時刻のクエリ式
FQL には、日付と時刻用に datetime データ型が用意されています。
次の ISO 8601 互換の datetime 形式がクエリでサポートされます。
- YYYY-MM-DD
- YYYY-MM-DDThh:mm:ss
- YYYY-MM-DDThh:mm:ssZ
- YYYY-MM-DDThh:mm:ssfrZ
これらの datetime 形式では、
YYYY には、4 桁の年を指定します。
注:
サポートされるのは、4 桁の年だけです。
MM には、2 桁の月を指定します。 たとえば、01 は 1 月を意味します。
DD には、2 桁の日 (01 ~ 31) を指定します。
T には、文字 "T" を指定します。
hh には、2 桁の時間 (00 ~ 23) を指定します。A.M. と P.M. は使用できません。
mm には、2 桁の分 (00 ~ 59) を指定します。
ss には、2 桁の秒 (00 ~ 59) を指定します。
fr は、秒の省略可能な分数 ss を指定します。の 後の 1 から 7 桁の数字を指定します。 たとえば、2012-09-27T11:57:34.1234567 などです。
すべての日付と時刻の値は、UTC (協定世界時) (GMT (グリニッジ標準時) とも呼ばれます) タイム ゾーンに従って指定する必要があります。 UTC タイムゾーンの識別子 (末尾の "Z" 文字) はオプションです。
予約語、特殊文字、エスケープ
次の単語は、FQL で予約されています。
and, or, any, andnot, count, decimal, rank, near, onear, int, in32, int64, float, double, datetime, max, min, range, phrase, scope, filter, not, string, starts-with, ends-with, equals, words, xrank.
上記のいずれかの単語をクエリ式の用語として使用する場合は、次の例に示すように、その単語を二重引用符で囲む必要があります。
or("any", "and", "xrank")string("any and xrank", mode="OR")phrase(this, is, a, "phrase")
ヒント
予約語と予約文字は、大文字と小文字が区別されませんが、将来の互換性のために、小文字を使用することをお勧めします。
FQL では、文字列を必ず二重引用符で囲む必要があるわけではありません。 たとえば、 and(cat, dog) は、 cat と dog は二重引用符で囲まれていませんが、有効な FQL です。 ただし、予約語との競合を避けるために、二重引用符を使用することをお勧めします。
クエリの用語は、ユーザーのロケール設定に従ってトークン化されます。 トークン化処理では、特定の特殊文字が削除されます。 特殊文字が削除されるので、次の 2 つの FQL 式は同値です。
and("[king]", "<queen>")
and("king", "queen")
クエリに、ユーザー入力または別のアプリケーションからの用語を追加する場合は、 string("<query terms>", mode="AND|OR|PHRASE") 演算子を使用して、クエリ言語の予約語と競合しないようにする必要があります。 また、ユーザー指定のクエリから可能な二重引用符を削除する必要があります。
FQL の演算子
FAST クエリ言語 (FQL) 演算子は、ブール演算やその他の制約をオペランドに指定するキーワードです。 FQL 演算子の構文は次のとおりです。
[property-spec:]operator(operand [,operand]* [, parameter="value"]*)
構文の詳細:
- property-spec は、オプションのプロパティ指定であり、その後に "in" 演算子が続きます。
- operator は、実行する演算を指定するキーワードです。
- operand は、項表現または別の演算子です。
- parameter は、演算子の動作を変更する値の名前です。
- value は、パラメーター名で使用する値です。
演算子名、パラメーター名、パラメーター テキストの各値は大文字と小文字を区別しません。 演算子の本文内に空白を含めることはできますが、二重引用符で囲まれていない場合、空白は無視されます。 FAST クエリ言語のクエリの長さは 2,048 文字に制限されています。
表 3 では、FQL でサポートされている演算子の型の一覧を示します。
表 3. FQL でサポートされている演算子の型
| 種類 | 説明 | 演算子 |
|---|---|---|
| String | 用語の文字列に対するクエリ操作を指定できます。 これはテキスト用語で使用する最も一般的な演算子です。 | STRING |
| ブール値 | クエリ内で用語とサブ式を組み合わせることができます。 | AND、 または、 ANY、 ANDNOT、 NOT、 COUNT、 COUNT |
| 近接性 | 対応する一連のテキストでクエリ用語の近接を指定できます。 | NEAR、ONEAR、PHRASE、STARTS-WITH、ENDS-WITH、EQUALS |
| 数値型 (Numeric) | クエリで数値的条件を指定できます。 | RANGE、INT、FLOAT、DATETIME、DECIMAL |
| 関連性 | クエリの関連性評価に影響を与えることができます。 | XRANK および FILTER |
表 4 に、サポートされている演算子の一覧を示します。
表 4. FQL でサポートされている演算子
| 演算子 | 説明 | 型 |
|---|---|---|
| AND | すべての AND オペランドに一致するアイテムのみを返します。 | ブール値 |
| ANDNOT | 1 番目のオペランドに一致し、それ以降のオペランドに一致しないアイテムのみを返します。 | ブール値 |
| ANY | OR 演算子と似ていますが、動的ランク (結果セット.md 内の関連性スコア) は、一致するオペランド数やアイテム内の用語間の距離に影響されません。 | ブール値 |
| COUNT | 結果として返すアイテムに含まれている必要のあるクエリ用語の出現回数を指定できます。 オペランドに指定できるのは、1 つのクエリ用語、語句、またはワイルドカード クエリ用語です。 | ブール型 (Boolean) |
| DATETIME | 数値の明示的な入力を提供します。 明示的な型変換はオプションであり、通常は必要ありません。 クエリ用語の型はターゲットの数値管理プロパティの型に従って検出されます。 | 数値型 (Numeric) |
| DECIMAL | 数値の明示的な入力を提供します。 明示的な型変換はオプションであり、通常は必要ありません。 クエリ用語の型はターゲットの数値管理プロパティの型に従って検出されます。 | 数値型 (Numeric) |
| ENDS-WITH | 単語または語句が管理プロパティの末尾に出現する必要があることを指定します。 | 近接性 |
| EQUALS | 単語、用語、または語句が、管理プロパティと完全にトークン一致する必要があることを指定します。 | 近接性 |
| FILTER | メタデータまたはその他の構造化データのクエリを実行するために使用します。 | 関連性 |
| FLOAT | 数値の明示的な入力を提供します。 明示的な型変換はオプションであり、通常は必要ありません。 クエリ用語の型はターゲットの数値管理プロパティの型に従って検出されます。 | 数値型 (Numeric) |
| INT | 数値の明示的な入力を提供します。 明示的な型変換はオプションであり、通常は必要ありません。 クエリ用語の型はターゲットの数値管理プロパティの型に従って検出されます。 | 数値型 (Numeric) |
| NEAR | 特定の互いの距離内で N 個の用語を持つアイテムに結果セットを制限します。 |
近接性 |
| NOT | オペランドを含まないアイテムのみを返します。 | ブール値 |
| ONEAR |
NEAR の順序付けされたバリアントで、用語の順序付き一致が必要です。
ONEAR 演算子を使用すると、結果セットを、一定の距離内N項を持つ項目に制限できます。オペランドと一致しない項目のみを返します。 オペランドには、任意の有効な FQL 式を指定できます。 |
近接性 |
| OR | 1 つ以上の OR オペランドに一致するアイテムのみを返します。 OR オペランドに一致する数が多くなると、一致するアイテムの動的ランク (結果セット.md 内の関連性スコア) が高くなります。 | ブール値 |
| PHRASE | トークンの完全な文字列に一致するアイテムのみを返します。 | 近接性 |
| RANGE | 範囲一致式を有効にします。 RANGE 演算子は、数値管理プロパティおよび日時管理プロパティで使用します。 | 数値型 (Numeric) |
| STARTS-WITH | 単語または語句が管理プロパティの先頭に出現する必要があることを指定します。 | 近接性 |
| STRING | テキスト文字列に対するブール型の一致条件を定義します。 | String |
| XRANK | クエリに一致する項目を変更することなく、特定の用語の出現に基づいて項目の動的ランクを高めることができます。 XRANK 式には、一致する必要がある 1 つのコンポーネントと、動的ランク付けにのみ影響する 1 つ以上のコンポーネントが含まれています。 | 関連性 |
注:
SharePoint では、RANK 演算子は非推奨になり、効果がなくなりました。 代わりに XRANK を使用します。
AND
すべての AND オペランドに一致するアイテムのみを返します。 オペランドに指定できるのは、1 つの用語か任意の有効な FQL サブ式です。
構文
and(operand, operand [, operand]*)
パラメーター
なし。
例
次の式は、既定のフルテキスト インデックスに "cat"、"dog"、および "fox" が含まれるアイテムに一致します。
and(cat, dog, fox)
ANDNOT
1 番目のオペランドに一致し、それ以降のオペランドに一致しないアイテムのみを返します。 オペランドに指定できるのは、1 つの用語か任意の有効な FQL サブ式です。
構文
andnot(operand, operand [,operand]*)
パラメーター
なし。
例
例 1. 次の式は、既定のフルテキスト インデックスに "cat" が含まれて "dog" が含まれないアイテムに一致します。
andnot(cat, dog)
例 2。 次の式は、既定のフルテキスト インデックスに "dog" が含まれて "beagle" と "chihuahua" が含まれないアイテムに一致します。
andnot(dog, beagle, chihuahua)
ANY
注:
SharePoint では、ANY 演算子は非推奨になりました。 代わりに OR を使用します。
OR 演算子と似ていますが、動的ランク (結果セット内の関連性スコア) は、一致するオペランド数やアイテム内の用語間の距離に影響されません。 オペランドに指定できるのは、1 つの用語か任意の有効な FQL サブ式です。
クエリの該当部分の動的ランク付けコンポーネントは、ANY 式内で最もよく一致する用語に基づいています。
注:
OR との違いは、結果セット内でのランク付けに関連したことだけです。 同じアイテム セットがどちらのクエリにも一致します。
構文
any(operand, operand [,operand]*)
パラメーター
なし。
例
次の式は、既定のフルテキスト インデックスに "cat" または "dog" が含まれるアイテムに一致します。
インデックスに "cat" と "dog" の両方が含まれ、"cat" のほうがより良い一致とみなされる場合、アイテムの動的ランクは "cat" に基づきます。"dog" は考慮されません。
any(cat, dog)
COUNT
結果として返すアイテムに含まれている必要のあるクエリ用語の出現回数を指定します。 オペランドに指定できるのは、1 つのクエリ用語、語句、またはワイルドカード クエリ用語です。
構文
property-spec:count(operand [,from=<numeric value>, to=<numeric value>])
パラメーター
| パラメーター | 値 | 説明 |
|---|---|---|
| From | <numeric_value> | from パラメーターの値には、指定したオペランドに一致する必要のある最小回数を示す正の整数を指定する必要があります。 from パラメーターを指定しない場合、下限がなくなります。 |
| to | <numeric_value> | to パラメーターの値には、指定したオペランドに一致する必要のある包括的ではない最大回数を示す正の整数を指定する必要があります。 たとえば、 to 値の 11 は、10 回以下を示します。 to パラメーターを指定しない場合、上限がなくなります。 |
例
例 1. 次の式は、単語 "cat" が 5 回以上出現する場合に一致します。
count(cat, from=5)
例 2。 次の式は、単語 "cat" が 5 回以上かつ 10 回未満出現する場合に一致します。
count(cat, from=5, to=10)
例 3. 次の各式は、特定の単語が 3 回以上出現する場合に一致し、その単語は "cat" または "dog" のいずれかです。
count(or(cat, dog), from=3)count(string("cat dog", mode="or"), from=3)
次の表に、管理プロパティの文字列値の例と、その文字列値が例 3. の 2 つの式に一致するかどうかを示します。
| 一致ですか? | テキスト |
|---|---|
| はい | My cat likes my dog, but my dog hates my cat. |
| いいえ | My bird likes my newt, but my dog hates my cat. |
DATETIME
日付/時刻の数値の明示的な入力を提供します。 オペランドは、 FQL でのトークン式に指定された構文に従って書式設定された日時文字列です。
明示的な型変換はオプションであり、通常は必要ありません。 クエリ用語の型はターゲットの数値管理プロパティの型に従って検出されます。
構文
datetime(<date/time string>)
パラメーター
なし。
DECIMAL
少数の値の明示的な入力を提供します。 オペランドは、 FQL でのトークン式に指定された構文に従う 10 進値です。
明示的な型変換はオプションであり、通常は必要ありません。 クエリ用語の型はターゲットの数値管理プロパティの型に従って検出されます。
構文
decimal(<decimal point value>)
パラメーター
なし。
ENDS-WITH
単語または語句が管理プロパティの末尾に出現する必要があることを指定します (境界一致)。
境界一致は数値管理プロパティでサポートされません。 数値管理プロパティは、常に、完全一致または値範囲の一致に従います。
一部のアプリケーションでは、マネージド プロパティの完全一致を実行できることが必要な場合があります。 たとえば、これは製品名管理プロパティであり、ある 製品 のフル ネームは別の製品名の部分文字列です。
構文
ends-with(<term or phrase>)
パラメーター
なし。
例
次の式は、"author" 管理プロパティに値 "Mr Adam Jones" および "Adam Jones" が含まれるアイテムに一致します。 値 "Adam Jones sr" が含まれるアイテムには一致しません。
author:ends-with("adam jones")
注釈
境界一致は、管理プロパティのすべてのテキスト、または文字列値のリスト (名前のリストなど) を含む管理プロパティ内の個々の文字列に適用できます。 この場合、各文字列の完全な内容の一致を実行したり、文字列境界を超えるクエリ一致を回避したりできます。
境界一致クエリを適用するには、関連する管理プロパティをインデックス スキーマに構成する必要があります。
管理プロパティの境界一致機能を有効にすることで、以下の処理を行うことができます。
- 明示的な境界一致クエリを使用する。
- 文字列境界を超えて語句が一致しないようにする。 複数の文字列を含む管理プロパティでこの機能を使用すると、文字列は、境界指示の前または後ろで単語に一致しません。
EQUALS
単語または語句が、管理プロパティと完全にトークン一致する必要があることを指定します。
構文
equals(<term or phrase>)
パラメーター
なし。
例
次の例は、"author" 管理プロパティに値 "Adam Jones" が含まれるアイテムに一致します。 値 "Adam Jones sr" または "Mr Adam Jones" が含まれるアイテムには一致しません。
author:equals("adam jones")
注釈
「ENDS-WITH」も参照してください。
FILTER
メタデータまたはその他の構造化データのクエリを実行するために使用します。
FILTER 演算子を使用すると、指定したクエリに対して以下の処理が自動的に行われます。
言語的機能が linguistics="OFF" に設定されます。
ランク付けが無効になります。
クエリの強調表示は、クエリ結果検索の検索語句強調表示サマリーでは使用されません。
ヒント:FILTER 式の中で STRING 演算子を使用する場合、既定では言語は無効です。 オペランド
linguistics="ON"を使用して FILTER 内の各 STRING 式内で言語処理を有効にすることができます。
構文
filter(<any valid FQL operator expression>)
パラメーター
なし。
例
次の式は、"sonata" が含まれる Title 管理プロパティおよびトークン "audio" のみが含まれる Doctype 管理プロパティを持つアイテムに一致します。 "audio" で言語的一致は実行されません。 FILTER トークンが "audio" の一致に使用されるため、そのテキストは、検索語句を強調表示する要約で強調表示されません。
and(title:sonata, filter(doctype:equals("audio")))
注釈
数値プロパティで、1 つ以上の大きな整数値セットを照合するようにクエリを制限する必要がある場合、機能的に等しい次の 2 つの方法でこの式を表現できます。
and(string("hello world"), filter(property-spec:or(1, 20, 453, ... , 3473)))and(string("hello world"), filter(property-spec:int("1 20 453 ... 3473", mode="or")))
2 番目の例は、一連の数値を二重引用符で囲んだ文字列を使用して、 INT 演算子を使用しています。 大きな数値セットを使用してフィルター処理を行う場合は、これによりクエリのパフォーマンスが大幅に向上します。
大きな値セットをフィルター処理する必要がある場合、文字列値の代わりに数値の使用を考慮し、最適化された構文を使用してクエリを表現する必要があります。
FLOAT
浮動小数点数値の明示的な入力を提供します。 オペランドは、 FQL でのトークン式に指定された構文に従う浮動小数点値です。
明示的な型変換はオプションであり、通常は必要ありません。 クエリ用語の型はターゲットの数値管理プロパティの型に従って検出されます。
構文
float(<floating point value>)
パラメーター
なし。
INT
整数値の明示的な入力を提供します。 オペランドは、 FQL でのトークン式に指定された構文に従う整数値です。
明示的な型変換はオプションであり、通常は必要ありません。 クエリ用語の型はターゲットの数値管理プロパティの型に従って検出されます。
INT 演算子を使用して、整数値のセットをブール型 FQL 演算子の引数として表すこともできます。 これにより、 INT 演算子を使用して渡される値は FQL クエリ パーサーによって解析されず、クエリ一致コンポーネントに直接渡されるため、クエリに整数値のセットを提供するパフォーマンス効率の高い方法が提供されます。
構文
int(<integer value>)
int("value, value, ??? , value")
1 番目の構文では、1 つの整数が指定されています。 2 番目の構文では、二重引用符で囲まれた整数値のコンマ区切りのリストが指定されています。
パラメーター
なし。
例
数値プロパティで、1 つ以上の大きな整数値セットを照合するようにクエリを制限する必要がある場合、 INT 演算子を使用してこれを表現できます。
and(string("hello world"), filter(id:int("1 20 49 124 453 985 3473", mode="or")))
NEAR
特定の互いの距離内で N 個の用語を持つアイテムに、結果セットを制限します。
照合では、クエリ用語の順序は重要ではありません。重要なのは距離だけです。
任意の数の用語を NEAR 演算子と組み合わせることができます。
NEAR オペランドに指定できるのは、1 つの用語、語句、またはブール型の OR あるいは ANY 演算子式です。 ワイルドカードも使用できます。
NEAR 演算子の複数のオペランドが同じインデックス付きトークンに一致する場合、それらは互いに近いとみなされます。
構文
near(arg, arg [, arg]* [, N=<numeric value>])
パラメーター
| パラメーター | 値 | 説明 |
|---|---|---|
| N | <numeric_value> | 用語間に出現可能な単語の最大数を指定します (明示的な近接)。 NEAR に 3 つ以上のオペランドが含まれる場合、用語間で出現可能な単語の最大数 ( N) は式全体内でカウントされます。 既定値: 4 |
例
例 1. 次の式は、"cat" と "dog" の両方を含む文字列のうち、4 つ以下のインデックス付きトークン (既定) でそれらが区切られている文字列に一致します。
near(cat, dog)
例 2。 次の式は、"cat"、"dog"、"fox"、および "wolf" を含む文字列のうち、4 つ以下のインデックス付きトークンでそれらが区切られている文字列に一致します。
near(cat, dog, fox, wolf)
次の表に、管理プロパティの文字列値の例と、その文字列値が前述の例 2. の式に一致するかどうかを示します。
| 一致ですか? | テキスト |
|---|---|
| はい | The picture shows a cat, a dog, a fox, and a wolf. |
| はい (ステミングを使用) | Dogs, foxes, and wolves are canines, but cats are felines. |
| いいえ | The picture shows a cat with a dog, a fox, and a wolf. |
次の式は、前述の表のすべての文字列に一致します。
near(cat, dog, fox, wolf, N=5)
注釈
NEAR/ONEAR の用語距離に関する考慮事項
N は、アイテムの一致セグメント内のクエリ用語間で出現可能な単語の最大数を示します。 NEAR または ONEAR に 3 つ以上のオペランドがある場合、クエリ用語間で出現可能な単語の最大数 ( N) は、 NEAR または ONEAR のすべての用語に一致するアイテムのセグメント内でカウントされます。
NEAR または ONEAR はトークン化されたテキストで動作します。 つまり、コンマ (" 、")、ピリオド (" . ")、コロン (" : ")、セミコロン (" ; ") などの特殊文字が含まれます。は空白として扱われます。 用語 "距離" は、インデックス付きのテキスト内のトークンに関係します。
ONEAR または NEAR を等号オペランドと共に使用する場合、演算子は次のように機能します。
near(a, a, n=x)
1 つ以上の '' '' のインスタンスがコンテキスト内に出現する場合、このクエリは常に a を返します。 また、これは、 NEAR を COUNT 演算子として使用できないことも意味します。 用語の出現回数のカウント方法については、 COUNT 演算子を参照してください。
語句に適用される NEAR は、テキスト内の重複する語句にも一致します。
一致セグメント内のトークンが NEAR または ONEAR 式の複数のオペランドに一致する場合は、一致セグメント内の不一致トークンの数が NEAR または ONEAR 演算子式の ' N' の値を超える場合でも、クエリは一致する場合があります。 たとえば、重複は重複する語句になりえます。 トークンの重複一致の数が ' O' の場合、' N+O' を超える不一致トークンがアイテムの一致セグメント内に出現しない場合、クエリは一致します。
NEAR または ONEAR と NOT
NOT 演算子を NEAR または ONEAR 演算子内で使用することはできません。 次の FQL 構文は誤りです。
near(audi,not(bmw),n=2)
NOT
オペランドに一致しないアイテムのみを返します。 オペランドに指定できるのは、任意の有効な FQL 式です。
構文
not(operand)
パラメーター
なし。
ONEAR
NEAR の順序付けされたバリアントで、用語の順序付き一致が必要です。 ONEAR 演算子を使用すると、結果セットを、互いに一定の距離内に N 個の用語がある項目に制限できます。
構文
onear(arg, arg [, arg]* [, N=<numeric value>])
パラメーター
| パラメーター | 値 | 説明 |
|---|---|---|
| N | <numeric_value> | 用語間に出現可能な単語の最大数を指定します (明示的な近接)。 ONEAR に 3 つ以上のオペランドが含まれる場合、用語間で出現可能な単語の最大数 ( N) は式全体内でカウントされます。 既定値: 4 |
例
例 1. 次の式は、単語 "cat"、"dog"、"fox"、および "wolf" のすべてが順序どおりに出現するもののうち、4 つ以下のインデックス付きトークンでそれらの単語が区切られている場合に一致します。
onear(cat, dog, fox, wolf)
次の表に、管理プロパティの文字列値の例と、その文字列値が前述の式に一致するかどうかを示します。
| 一致ですか? | テキスト |
|---|---|
| はい | The picture shows a cat, a dog, a fox, and a wolf. |
| いいえ | Dogs, foxes, and wolves are canines, but cats are felines. |
| いいえ | The picture shows a cat with a dog, a fox, and a wolf. |
例 2。 次の式は、前述の表の 2 番目の行のテキストに一致 (ステミングを使用) します。
onear(dog, fox, wolf, cat, N=5)
例 3. 次の式は、前述の表の 1 番目と 3 番目の行のテキストに一致します。
onear(cat, dog, fox, wolf, N=5)
注釈
「NEAR」も参照してください。
OR
1 つ以上の OR オペランドに一致するアイテムのみを返します。 OR オペランドに一致する数が多くなると、一致するアイテムの動的ランク (結果セット内の関連性スコア) が高くなります。 オペランドに指定できるのは、1 つの用語か任意の有効な FQL サブ式です。
構文
or(operand, operand [,operand]*)
パラメーター
なし。
例
次の式は、既定のフルテキスト インデックスに "cat" または "dog" が含まれるすべてのアイテムに一致します。 アイテムの既定のフルテキスト インデックスに "cat" と "dog" の両方が含まれる場合、そのアイテムは一致し、そのトークンの 1 つのみが含まれる場合よりも動的ランクが高くなります。
or(cat, dog)
PHRASE
トークンの完全な文字列を検索します。
PHRASE オペランドに指定できるのは、1 つの用語です。 ワイルドカードも使用できます。
構文
phrase(term [, term]*)
パラメーター
なし。
注釈
「STRING」も参照してください。
RANGE
RANGE 演算子は、数値管理プロパティおよび日時管理プロパティで使用します。 この演算子を使用すると、範囲一致式を指定できます。
構文
range(start, stop [,from="GE"|"GT"] [,to="LE"|"LT"])
パラメーター
| パラメーター | 値 | 値 | 説明 |
|---|---|---|---|
| start | _<numeric_value>\ | <date/time_value>_ | 範囲の開始値です。 範囲に下限がないことを指定するには、予約語の min を使用します。 |
| stop | _<numeric_value>\ | <date/time_value>_ | 範囲の終了値です。 範囲に上限がないことを指定するには、予約語の max を使用します。 |
| from | **GE\ | GT** | 開かれた開始間隔または閉じられた開始間隔を示すオプションのパラメーター。 有効な値:
|
| to | **LE\ | LT** | 開かれた終了間隔または閉じられた終了間隔を示すオプションのパラメーター。 有効な値:
|
例
次の式は、サイズが 10000 バイト以上のアイテム内に出現する語句 "big accomplishments" で始まる Description プロパティに一致します。
and(size:range(10000, max), description:starts-with("big accomplishments"))
STARTS-WITH
管理プロパティの先頭に出現する必要がある単語または語句を指定します。
構文
starts-with(<term or phrase>)
パラメーター
なし。
例
次の式は、author 管理プロパティに値 "Adam Jones sr" および "Adam Jones" が含まれるアイテムに一致します。 値 "Mr Adam Jones" が含まれるアイテムには一致しません。
author:starts-with("adam jones")
注釈
境界一致の詳細については、「ENDS-WITH」を参照してください。
STRING
テキスト文字列に対するブール型の一致条件を定義します。
オペランドは、照合するテキスト文字列 (1 つ以上の用語) です。 文字列の後にはゼロ個以上のパラメーターが続きます。
STRING 演算子を型変換として使用することもできます。 たとえば、クエリ string("24.5")では、数値 "24.5" がテキスト文字列として扱われます。
構文
string("<text string>"
[, mode=<mode>]
[, n=<near>]
[, weight=<n>]
[, linguistics=<on|off>]
[, wildcard=<on|off>])
パラメーター
| パラメーター | 値 | 説明 | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| mode | <mode> |
mode パラメーターは、<text string> 値の評価方法を指定します。 次の一覧に有効な値を示します。
"PHRASE" - phrase(term [,term]*)
|
||||||||||||||
| n | <numeric_value> | このパラメーターは、mode= "NEAR" または mode= "ONEAR" の最大用語距離を示します。 次の式は同等です。 string("hello world", mode="NEAR", n=5)near(hello, world, n=5) 既定値: 4 |
||||||||||||||
| weight | <numeric_value> | このパラメータは、動的ランク付けの用語の重みを示す正の数値です。 低い値は、ランクへの用語の貢献度が低くなることを示します。 高い値は、ランクへの用語の貢献度が高くなることを示します。 重みパラメーターの値がゼロの場合、用語は動的ランクに影響しません。 weight パラメータは、STRING 式のすべての用語に適用されます。 ヒント: weight パラメーターは、フルテキスト インデックス クエリにのみ影響します。 既定値: 100 | ||||||||||||||
| linguistics | on|off | 文字列のすべての言語機能 (見出し語解析、同義語、スペルチェック) がクエリで有効になっている場合、それらを無効または有効にします。 このパラメーターを使用すると、ランクへの特定の用語または文字列の貢献を維持したまま、その用語または文字列の言語的処理をオフに切り替えることができます。 既定値: "ON" | ||||||||||||||
| wildcard | on|off | このパラメータは、<文字列>内で用語のワイルドカード拡張を制御します。 この設定は、クエリ パラメーター内のすべてのワイルドカード設定を上書きします。また、この設定を使用して、クエリの特定の部分で、拡張されたワイルドカード文字を有効または無効にできます。 有効な値は次のとおりです。
|
注:
SharePoint では、STRING 演算子のパラメーター minexpansion、maxexpansion、annotation_class は廃止されました。
例
例 1. 既定の文字列モードは " PHRASE " であるため、次の式はそれぞれ同じ結果を返します。
"what light through yonder window breaks"string("what light through yonder window breaks")string("what light through yonder window breaks", mode="phrase")phrase(what, light, through, yonder, window, breaks)
例 2。 次の文字列トークン式と AND 演算子式は同じ結果を返します。
string("cat dog fox", mode="and")and(cat, dog, fox)
例 3. 次の文字列トークン式と OR 演算子式は同じ結果を返します。
string("coyote saguaro", mode="or")or(coyote, saguaro)
例 4. 次の文字列トークン式と ANY 演算子式は同じ結果を返します。
string("coyote saguaro", mode="any")any(coyote, saguaro)
例 5. 次の文字列トークン式と NEAR 演算子式は同じ結果を返します。
string("coyote saguaro", mode="near")near(coyote, saguaro)
例 6. 次の文字列トークン式と NEAR 演算子式は同じ結果を返します。
string("cat dog fox wolf", mode="near", N=4)near(cat, dog, fox, wolf, N=4)
例 7. 次の文字列トークン式と ONEAR 演算子式は同じ結果を返します。
string("cat dog fox wolf", mode="onear")onear(cat, dog, fox, wolf)
例 8. 次の文字列トークン式は、言語機能が無効になっている "nobler" という単語と一致するため、他の形式の単語 ("ennobling" など) はステミングを使用して一致しません。
string("nobler", linguistics="off")
例 9. 次の式は、"cat" または "dog " が含まれるアイテムに一致しますが、"dog" が含まれるアイテムの動的ランクは "cat" が含まれるアイテムよりも高くなります。
or(string("cat", weight="200"), string("dog", weight="500"))
注釈
動的ランクにおける関連性の重み
weight パラメーターの主な効果は OR クエリで発揮されます。 また、AND クエリにも一部の効果が与えられます。 動的ランク アルゴリズムは、アイテム内のどの場所で用語の一致が発生するかによって、用語によりランク貢献度が異なることを暗黙に示す可能性があります。
ランク貢献度の差は、用語の頻度と、逆のアイテムの頻度に基づくこともできます。 例を次に示します。
- クエリ:
and(string("a"), string("b", weight=200)) - インデックス スキーマ: title 管理プロパティは、 body 管理プロパティよりも高い重みを持っている。
- インデックス アイテム 1 のタイトルには用語 "a" が含まれ、本文には用語 "b" が含まれる。
- インデックス アイテム 2 の本文には用語 "a" が含まれ、タイトルには用語 "b" が含まれる。
この例では、アイテム 2 の合計ランクが最高になります。高い動的ランクの貢献を持つアイテムは、ランクがさらにアップするためです。
ヒント: 相対的な用語のブースト (正または負) は、合計ランクの動的ランク コンポーネントに適用されます。 ただし、近接ブースト (単語間の間隔) のランク計算は、用語の重み付けの影響を受けません。 相対的な重み付けは、アイテムの合計ランクが特定のパーセンテージに従って変更されることを必ずしも意味しません。 > 次のクエリでは、"peter"、"paul"、または "mary" という用語を検索します。ここで、"peter" は他の 2 つの用語の 2 倍のランクコントリビューションを持つことになります。 >
or(peter, string("paul mary", mode="OR", weight=50))
特殊文字を含む文字列を処理する
コンマ (",")、セミコロン (";")、コロン (":")、ピリオド (".")、マイナス ("-")、下線 ("_")、スラッシュ ("/") などの特殊文字は、二重引用符で囲まれた文字列式内では空白として処理されます。 これは、トークン化処理に関連します。 これらの文字は、これらの文字によって区切られるトークンの暗黙的な句法も意味します。
次のクエリ式は同等です。
title:string("animals birds", mode="phrase")title:"animals/birds"title:string("animals/birds", mode="and")title:string("animals/birds", mode="or")
次のクエリ式は同等です。
title:or(string("animals birds", mode="phrase"), string("animals insects", mode="phrase"))title:string("animals/birds animals/insects", mode="or")
次のクエリ式は同等です。
body:string("help contoso com", mode="phrase")body:string("help@contoso.com")
トークン化された語句の一致
STRING 演算子を mode = "phrase" で使用するか、または PHRASE 演算子を使用することで、トークンの正確な文字列を検索できます。
これらの語句操作は、トークン化された語句の一致を意味します。 つまり、コンマ (" 、") 、 セミコロン (") 、コロン (" : ")、アンダースコア (" _ ")、マイナス (" - ")、スラッシュ (" / ") などの特殊文字は空白として扱われます。 これは、トークン化プロセスに関連します。
XRANK
クエリに一致するアイテムを変えることなく、match 式内の特定の用語出現回数に基づいてアイテムの動的ランクを上げます。 XRANK 式は、一致する必要がある 1 つのコンポーネント、つまり match 式、および動的ランク付けのみに貢献する 1 つ以上のコンポーネント、つまり rank 式で構成されます。 XRANK 式を有効にするためには、少なくともパラメーターの 1 つ (n を除く) を指定する必要があります。
Match expressionsに指定できるのは、入れ子の XRANK 式を含む任意の有効な FQL 式です。 Rank expressionsに指定できるのは、XRANK 式を除く任意の有効な FQL 式です。 FQL クエリに複数の XRANK 演算子がある場合、最後の動的なランク値はすべての XRANK 演算子の合計として計算されます。
注:
SharePoint Server 2010 では、XRANK 演算子には boost と boostall という 2 つのパラメーターと、xrank(operand, rank-operand [, rank-operand]* [,boost=n] [,boostall=yes]) の構文がありました。 この構文は、パラメーターとともに SharePoint で廃止されました。 代わりに、新しい構文とパラメーターの使用を推奨します。
構文
xrank(<match expression> [, <rank-expression>]*, rank-parameter[, rank-parameter]*)
式
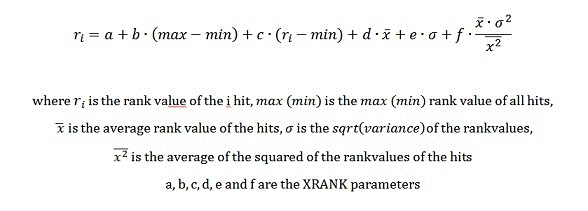
パラメーター
| パラメーター | 値 | 説明 |
|---|---|---|
| N | <integer_value> | 統計を計算する結果の数を指定します。 このパラメーターは、動的ランクが貢献する結果の数には影響しません。統計の計算から無関係なアイテムを除外するだけです。 既定値: 0 ゼロの値は、すべてのドキュメントのセマンティックを引き継ぎます。 |
| Nb | <float_value> | nb パラメーターは、正規化されたブーストを表します。 このパラメーターは、結果セットのランク値の差異および平均スコアの積に乗算する係数を指定します。 XRANK 数式の f。 |
通常、正規化されたブーストである nb は、変更された唯一のパラメーターです。 このパラメーターは、標準偏差を考慮せずに、特定のアイテムの昇格または降格に必要なコントロールを提供します。
詳細パラメーター
次の高度なパラメーターも使用できます。 ただし、通常は使用されません。
| パラメーター | 値 | 説明 |
|---|---|---|
| cb | <float_value> | cb パラメーターは、定数ブーストを表します。 既定値: 0 。 XRANK 数式の a。 |
| stdb | <float_value> | stdb パラメーターは、標準偏差ブーストを表します。 既定値: 0 。 XRANK 数式の e。 |
| avgb | <float_value> | avgb パラメーターは、平均ブーストを表します。 この係数は、結果セットの平均ランク値に乗算されます。 既定値: 0 。 XRANK 数式の d。 |
| rb | <float_value> | rb パラメーターは、範囲ブーストを表します。 この係数は結果セットのランク値の範囲に乗算されます。 既定値: 0 。 XRANK 数式の b。 |
| pb | <float_value> | pb パラメーターは、パーセンテージ ブーストを表します。 この係数は、集成内の最小値と比較されるアイテム自身のランクに乗算されます。 既定値: 0 。 XRANK 数式の c。 |
例
例 1. 次の式は、既定のフルテキスト インデックスに "cat" または "dog" が含まれるアイテムに一致します。 定数ブーストが 100 で "thoroughbred" も含まれるアイテムについては、動的ランクが上昇します。
xrank(or(cat, dog), thoroughbred, cb=100)
例 2。 次の式は、既定のフルテキスト インデックスに "cat" または "dog" が含まれるアイテムに一致します。 正規化されたブーストが 1.5 で "thoroughbred" も含まれるアイテムについては、動的ランクが上昇します。
xrank(or(cat, dog), thoroughbred, nb=1.5)
例 3. 次の式は、既定のフルテキスト インデックスに "cat" または "dog" が含まれるアイテムに一致します。 定数ブーストが 100、正規化されたブーストが 1.5 で、"thoroughbred" も含まれるアイテムについては、動的ランクが上昇します。
xrank(or(cat, dog), thoroughbred, cb=100, nb=1.5)
例 4. 次の式は、"animals" が含まれるすべてのアイテムに一致し、次のように、動的ランクを上げます。
"dogs" を含むアイテムの動的ランクは、100 ポイント上昇します。
"cats" を含むアイテムの動的ランクは、200 ポイント上昇します。
"dogs" および "cats" を含むアイテムの動的ランクは、300 ポイント上昇します。
xrank(xrank(animals, dogs, cb=100), cats, cb=200)