さまざまなストアとの間でのデータ モデルのシリアル化 (プレビュー)
データ モデルをデータベースに格納するには、データベースが理解できる形式に変換する必要があります。 データベースが異なると、異なるストレージ スキーマと形式が必要になります。 厳密なスキーマを使用する必要があるスキーマもあれば、ユーザーがスキーマを定義できるようにするものもあります。
マッピング オプション
セマンティック カーネルによって提供されるベクター ストア コネクタには、このマッピングを実現するための複数の方法が用意されています。
組み込みのマッパー
セマンティック カーネルによって提供されるベクター ストア コネクタには、データベース スキーマとの間でデータ モデルをマップする組み込みのマッパーがあります。 組み込みのマッパーが各データベースのデータをマップする方法の詳細については、各コネクタ の
カスタム マッパー
セマンティック カーネルによって提供されるベクター ストア コネクタでは、VectorStoreRecordDefinitionと組み合わせてカスタム マッパーを提供する機能がサポートされています。 この場合、VectorStoreRecordDefinition は指定されたデータ モデルとは異なる場合があります。
VectorStoreRecordDefinition はデータベース スキーマの定義に使用されますが、データ モデルは開発者がベクター ストアと対話するために使用します。
この場合、データ モデルから、VectorStoreRecordDefinitionによって定義されたカスタム データベース スキーマにマップするには、カスタム マッパーが必要です。
ヒント
独自のカスタム マッパーを作成する方法の例については、「ベクター ストア コネクタ のカスタム マッパーを作成する方法」を参照してください。
class または definition として定義されたデータ モデルをデータベースに格納するには、データベースが理解できる形式にシリアル化する必要があります。
セマンティック カーネルによって提供される組み込みのシリアル化を使用するか、独自のシリアル化ロジックを提供することで、2 つの方法を実行できます。
次の 2 つの図は、ストア モデルとの間のデータ モデルのシリアル化と逆シリアル化の両方のフローを示しています。
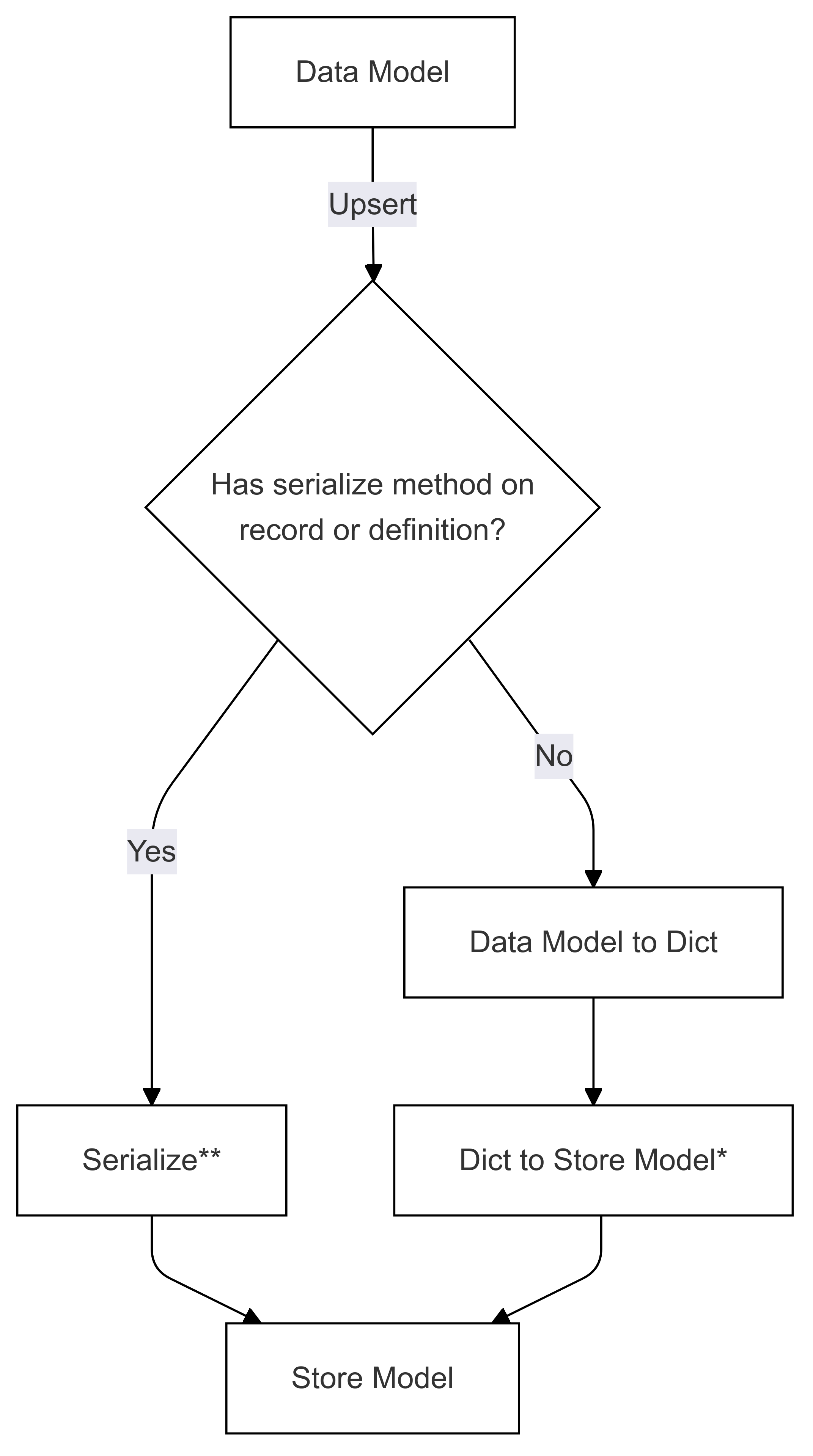
シリアル化フロー (Upsert で使用)
逆シリアル化フロー (Get と Search で使用)
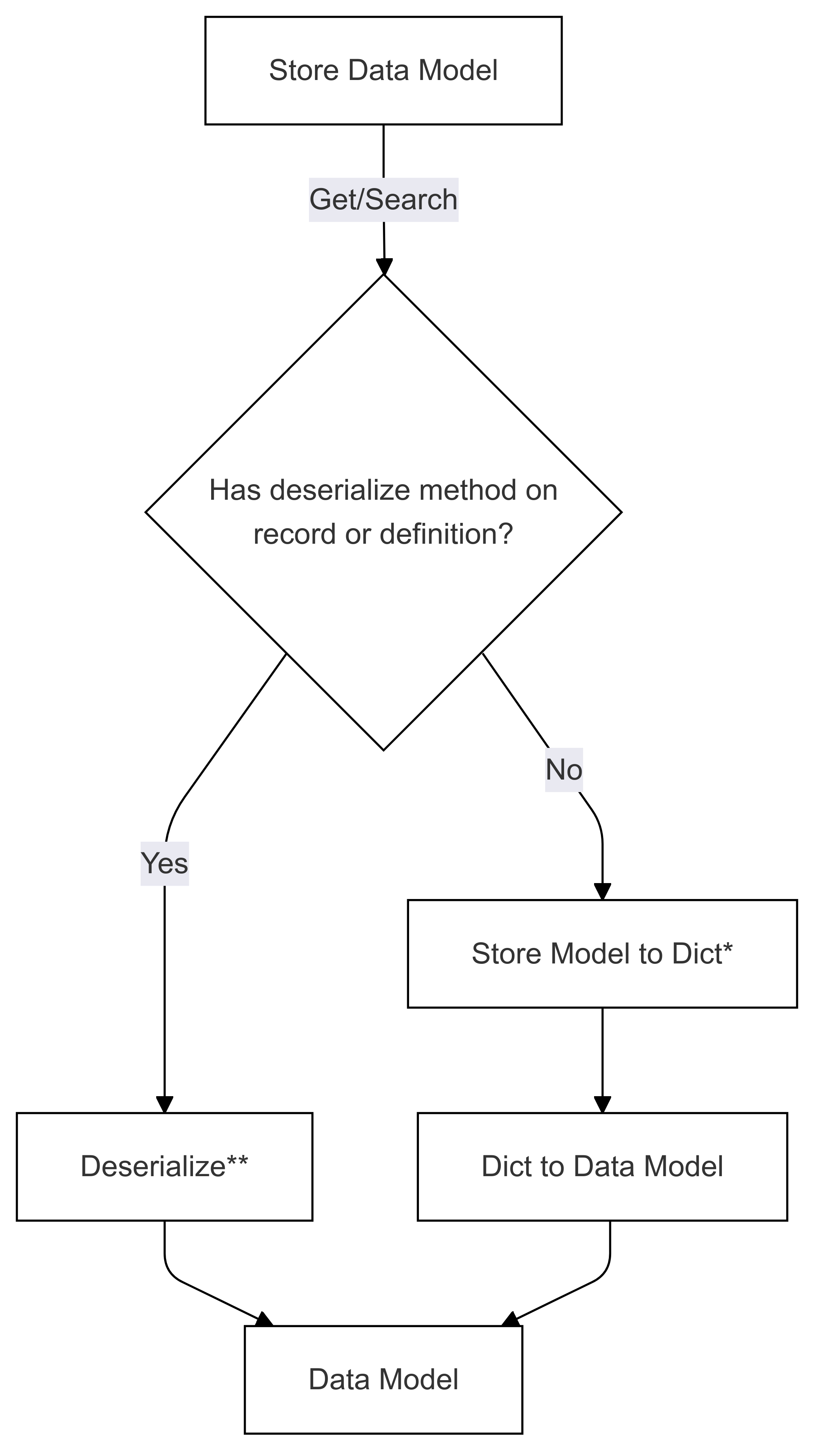
*でマークされた手順 (両方の図) は、特定のコネクタの開発者によって実装され、ストアごとに異なります。 ** でマークされた手順 (両方の図) は、レコードのメソッドとして、またはレコード定義の一部として提供されます。これは常にユーザーによって提供されます。詳細については、「ダイレクト シリアル化 を参照してください。
(De)シリアル化の方法
直接シリアル化 (モデルを格納するデータ モデル)
直接シリアル化は、モデルのシリアル化方法を完全に制御し、パフォーマンスを最適化する最適な方法です。 欠点は、データ ストアに固有であるため、これを使用する場合、同じデータ モデルを使用して異なるストアを切り替えるのはそれほど簡単ではありません。
これを使用するには、データ モデルで SerializeMethodProtocol プロトコルに従うメソッドを実装するか、SerializeFunctionProtocol に従う関数をレコード定義に追加することで、両方を semantic_kernel/data/vector_store_model_protocols.pyで確認できます。
これらの関数のいずれかが存在する場合は、データ モデルをストア モデルに直接シリアル化するために使用されます。
2 つのうちの 1 つのみを実装し、他の方向に組み込みの (de) シリアル化を使用することもできます。これは、たとえば、コントロールの外部で作成されたコレクションを処理する場合に役立ち、逆シリアル化の方法に合わせてカスタマイズを行う必要があります (アップサートを実行することはできません)。
組み込みでサポートされているシリアル化および逆シリアル化(データモデルからDict、Dictからストアモデルおよびその逆方向への変換)
組み込みシリアル化を行うには、まずデータ モデルをディクショナリに変換し、次に、組み込みコネクタの一部として定義されているストアごとに、それをストアが認識するモデルにシリアル化します。 逆シリアル化は逆順で行われます。
シリアル化の手順 1: データ モデルから Dict
使用しているデータ モデルの種類に応じて、手順はさまざまな方法で実行されます。 データ モデルをディクショナリにシリアル化するには、次の 4 つの方法があります。
- 定義の
to_dictメソッドは、データモデルの to_dict 属性に合わせており、ToDictFunctionProtocolに従っています。 - レコードが
ToDictMethodProtocolかどうかを確認し、to_dictメソッドを使用する - レコードが Pydantic モデルであるかどうかを確認し、モデルの
model_dumpを使用します。詳細については、以下の注を参照してください。 - 定義内のフィールドをループしてディクショナリを作成する
シリアル化の手順 2: モデルを格納するディクテーション
ディクショナリをストア モデルに変換するには、コネクタからメソッドを指定する必要があります。 これはコネクタの開発者によって行われ、ストアごとに異なります。
逆シリアル化手順 1: モデルを Dict に格納する
ストア モデルをディクショナリに変換するには、コネクタからメソッドを指定する必要があります。 これはコネクタの開発者によって行われ、ストアごとに異なります。
逆シリアル化手順 2: データ モデルへのディクテーション
逆シリアル化は逆順に行われ、次のオプションが試行されます。
- 定義の
from_dictメソッド (FromDictFunctionProtocolに従って、データ モデルのfrom_dict属性に合わせて配置されます) - レコードが
FromDictMethodProtocolかどうかを確認し、from_dictメソッドを使用する - レコードが Pydantic モデルであるかどうかを確認し、モデルの
model_validateを使用します。詳細については、以下の注を参照してください。 - 定義内のフィールドをループして値を設定すると、この dict は名前付き引数としてデータ モデルのコンストラクターに渡されます (データ モデルが dict 自体でない限り、その場合はそのまま返されます)。
手記
組み込みのシリアル化での Pydantic の使用
Pydantic BaseModel を使用してモデルを定義すると、 model_dump メソッドと model_validate メソッドを使用して、ディクテーションとの間でデータ モデルをシリアル化および逆シリアル化します。 これを行うには、パラメーターを指定せずに model_dump メソッドを使用します。これを制御する場合は、最初に試みるように、データ モデルに ToDictMethodProtocol を実装することを検討してください。
ベクターのシリアル化
データ モデルにベクターがある場合は、浮動小数点のリストまたは int のリストである必要があります。これはほとんどのストアで必要になるため、クラスでベクターを別の形式で格納する場合は、serialize_function注釈で定義されているdeserialize_functionとVectorStoreRecordVectorFieldを使用できます。 たとえば、numpy 配列の場合は、次の注釈を使用できます。
import numpy as np
vector: Annotated[
np.ndarray | None,
VectorStoreRecordVectorField(
dimensions=1536,
serialize_function=np.ndarray.tolist,
deserialize_function=np.array,
),
] = None
ネイティブ numpy 配列を処理できるベクター ストアを使用していて、それらを前後に変換したくない場合は、モデルとそのストアの ダイレクト シリアル化および逆シリアル化 メソッドを設定する必要があります。
手記
これは、組み込みのシリアル化を使用する場合にのみ使用されます。直接シリアル化を使用する場合は、任意の方法でベクターを処理できます。
間もなく利用できます
詳細については、近日公開予定です。