完全なデータ一致に基づく機密情報の種類のスキーマを作成する
ヒント
E5 のお客様でない場合は、90 日間の Microsoft Purview ソリューション試用版を使用して、Purview の追加機能が組織のデータ セキュリティとコンプライアンスのニーズの管理にどのように役立つかを確認してください。 Microsoft Purview 試用版ハブから開始します。 サインアップと試用期間の詳細については、こちらをご覧ください。
適用対象
- 従来の正確なデータ一致 (EDM) 機密情報の種類 (SIT) の作成エクスペリエンス。
正確なデータ一致スキーマと機密情報の種類のパターン ツールを使用する
EDM ベースの SITS やその実装に慣れていない場合は、次のことを理解しておく必要があります。
1 つの EDM スキーマを、同じ機密データ テーブルを使用する複数の機密情報の種類で使用できます。 Microsoft 365 テナントには、最大 10 個の異なる EDM スキーマを作成できます。
正確なデータ一致スキーマと機密情報の種類ツールを使用する
このツールを使用すると、スキーマ ファイルの作成プロセスを簡略化できます。
前提条件
- 正確 なデータ一致ベースの機密情報の種類については、「ソース データをエクスポートする」の手順を実行します。
正確なデータ一致スキーマと機密情報の種類のパターン ツールを使用する
現在使用しているポータルに該当するタブを選択してください。 Microsoft 365 プランによっては、Microsoft Purview コンプライアンス ポータルは廃止されるか、間もなく廃止されます。
Microsoft Purview ポータルの詳細については、Microsoft Purview ポータルを参照してください。 コンプライアンス ポータルの詳細については、「Microsoft Purview コンプライアンス ポータル」を参照してください。
Microsoft Purview ポータルにサインインします>Information Protection>Classifiers>EDM 分類子>EDM スキーマ (新しい EMD エクスペリエンスがオフに切り替えられたときに使用できます)。
[ EDM スキーマの作成 ] を選択して、スキーマ ツールの構成ポップアップを開きます。
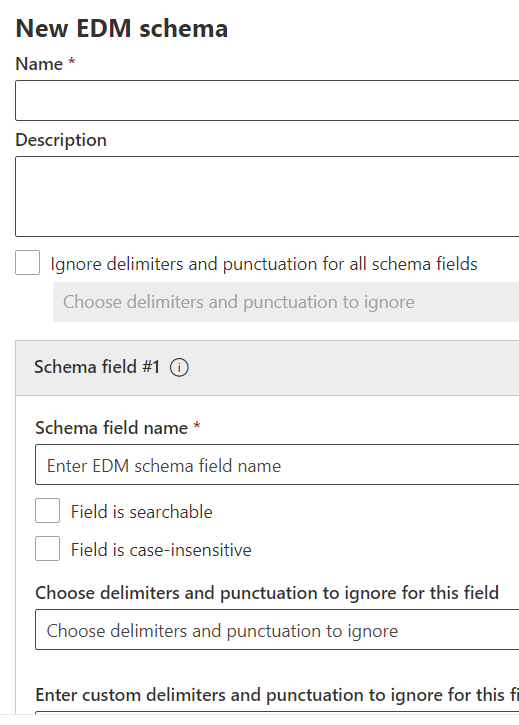
適切な 名前 と説明 を入力します。
スキーマ全体に Ignore... 動作を適用する場合は、[すべてのスキーマ フィールドの区切り記号と句読点を無視する] を選択します。 大文字と小文字または区切り記号を無視するように EDM を構成する方法の詳細については、この機能の詳細については、「 caseInsensitive フィールドと ignoreDelimiters フィールドの使用 」を参照してください。
スキーマ フィールド#1 必要な値を入力し、必要に応じてフィールドを追加します。 各スキーマ フィールドは、機密情報ソース ファイルの列ヘッダーと同じである必要があります。
必要な場合は、次のフィールドごとの値を設定します。
- フィールドは検索可能
- フィールドでは大文字と小文字が区別されません
- このフィールドで無視する区切り記号と句読点を選択する
- このフィールドのカスタム区切り記号と句読点を入力します
重要
スキーマ フィールドの少なくとも 1 つ (ただし 10 個以下) を検索可能として指定する必要があります。
保存] を選択します。 これで、スキーマが一覧表示され、使用できるようになります。
重要
EDM SIT に既に関連付けられているスキーマを削除する場合は、最初に EDM SIT を削除する必要があります。 データ ストアが関連付けられているスキーマを削除すると、24 時間以内にデータ ストアも削除されます。
XML 形式での EDM スキーマ ファイルのエクスポート
EDM スキーマ ツールで EDM スキーマを作成した場合は、スキーマ ファイルを XML 形式でエクスポートする必要があります。 完全なデータ一致の機密情報の種類のフェーズで、ハッシュを完了し、機密情報ソース テーブルをアップロードするには XML ファイルが必要です。
EDM スキーマ ファイルをエクスポートするには、次の構文を使用します。
$Schema = Get-DlpEdmSchema -Identity "[your EDM Schema name]" Set-Content -Path ".\Schemafile.xml" -Value $Schema.EdmSchemaXML後で使用するために、このファイルを保存します。
正確なデータ一致スキーマ ファイルを手動で作成してアップロードする
スキーマ ファイルを作成するときは、列ヘッダー (データ フィールド) が次の名前付け要件に準拠している必要があります。
- 文字で始まり、少なくとも 3 文字の英数字で構成する必要があります。
- 英数字のみを含める必要があります。
列/データ フィールドごとに次の構文を使用します。
<Field name="FieldName" searchable="true/false" caseInsensitive="true/false" ignoredDelimiters="delimiter characters" />
caseInsensitive フィールドと ignoredDelimiters フィールドの使用
次のスキーマ XML サンプルでは、 caseInsensitive フィールドと ignoredDelimiters フィールドを使用します。
スキーマ定義に true の値に設定されているcaseInsensitive フィールドを含めると、EDM はケースの違いに基づいて項目を除外しません。 たとえば、EDM では FOO-1234 と fOo-1234 の値が、 PatientID フィールドと同一であると見なされます。
サポートされている文字を含む ignoredDelimiters フィールドを含めると、EDM はこれらの文字を無視します。 そのため、EDM では 、FOO-1234 と FOO#1234 の値が PatientID フィールドと同一であると見なされます。
この例では、 caseInsensitive と ignoredDelimiters の両方が使用されている場合、EDM は FOO-1234 と fOo#1234 を同一と見なし、項目を患者レコードの機密情報の種類として分類します。
これらのパラメーターはどちらもフィールドごとに使用されます。
重要
空白を無視するように構成した場合、これはプライマリ フィールド列に対してのみ有効であり、複数ワード文字列を検出できる機密情報の種類が定義されます。 それ以外の場合は、分析対象のコンテンツ内の個々の単語に対して比較が行われます。
ignoredDelimiters フラグは、英数字以外の文字をサポートします。次に例を示します。
- .
- -
- /
- _
- *
- ^
- #
- !
- ?
- [
- ]
- {
- }
- \
- ~
- ;
ignoredDelimitersフラグは以下をサポートしていません:
- 0 から 9 の文字
- A から Z
- a から z
- "
- ,
重要
EDM 機密情報の種類を定義する場合、 ignoredDelimiters は、EDM パターンのプライマリ要素に関連付けられている分類の機密情報の種類がアイテム内のコンテンツを識別する方法に影響しません。 そのため、検索可能なフィールドの ignoredDelimiters を構成する場合は、そのフィールドに基づいてプライマリ要素に使用される機密情報の種類が、それらの文字の有無にかかわらず文字列を選択することを確認する必要があります。
機密情報ソース テーブル内の列の数とスキーマ内のフィールドの数が一致している必要があります。順序は関係ありません。
トークン区切り記号として使用される文字は、他の区切り記号とは異なる動作をします。 次に、いくつかの例を示します:
- \ (スペース)
- \t
- ,
- .
- ;
- ?
- !
- r
- \n
トークン区切り記号を含めると、EDM は区切り記号があるトークンを中断します。 たとえば、EDM では、LastName フィールドの値 Middle-Last Name が Middle-Last と Name に表示されます。 文字 '-' を持つLastName フィールドにignoredDelimitersが含まれている場合、そのアクションは値が壊れた後にのみ発生します。 最後に、EDM には次の値 MiddleLast と Name が表示されます。
トークン区切り記号ではなく、ignoredDelimitersとして次の文字を使用するには、対応する形式に一致する SIT をフィールドに関連付ける必要があります。 たとえば、ダッシュを含む複数単語の文字列を検出する SIT は、 LastName フィールドに関連付ける必要があります。
- .
- ;
- !
- ?
- \
POWERShell を使用して、SID をセカンダリ要素に関連付けることができます。
スキーマを XML 形式で定義します (次の例のように)。 このスキーマ ファイル にedm.xml 名前を付け、機密情報ソース テーブルの各列に構文を使用する行が存在するように構成します。
\<Field name="" searchable=""/\>.- Field name の値に列名を使用します。
- 検索可能なフィールドと最大 5 つのフィールドまでのプライマリ フィールドには、
searchable="true"を使用します。 少なくとも 1 つのフィールドは検索可能である必要があります。
たとえば、次の XML ファイルは、患者レコード データベースのスキーマを定義し、
PatientID、MRN、SSN、Phone、DOBの 5 つのフィールドを検索可能として指定します。(この例は、コピー、変更、使用することができます。)
<EdmSchema xmlns="http://schemas.microsoft.com/office/2018/edm"> <DataStore name="PatientRecords" description="Schema for patient records" version="1"> <Field name="PatientID" searchable="true" caseInsensitive="true" ignoredDelimiters="-,/,*,#,^" /> <Field name="MRN" searchable="true" /> <Field name="FirstName" /> <Field name="LastName" /> <Field name="SSN" searchable="true" /> <Field name="Phone" searchable="true" /> <Field name="DOB" searchable="true" /> <Field name="Gender" /> <Field name="Address" /> </DataStore> </EdmSchema>XML 形式で EDM スキーマ ファイルを作成したら、クラウド サービスにアップロードする必要があります。
データベース スキーマをアップロードするには、次のコマンドを実行します。
New-DlpEdmSchema -FileData ([System.IO.File]::ReadAllBytes('.\\edm.xml')) -Confirm:$true次のように、確認を求められます。
確認
この操作を実行しますか?
データ ストア 'patientrecords' の新しい EDM スキーマがインポートされます。
[Y] Yes [A] Yes to All [N] No [L] No to All [?]ヘルプ (既定値は "Y"):
ヒント
確認なしで変更を行う場合は、手順 3 の
-Confirm:$trueを使用しないでください。
注:
追加機能を使用して EDMSchema を更新するには、10 から 60 分かかることがあります。 追加機能を使用する手順を実行する前に、更新プログラムを完了する必要があります。