予測コーディング モデルのトレーニング (プレビュー)
ヒント
新しい Microsoft Purview ポータルで電子情報開示 (プレビュー) を使用できるようになりました。 新しい電子情報開示エクスペリエンスの使用の詳細については、「電子 情報開示 (プレビュー)」を参照してください。
重要
予測コーディングは 2024 年 3 月 31 日に廃止され、新しい電子情報開示ケースでは使用できません。 トレーニング済みの予測コーディング モデルを使用する既存のケースでは、既存のスコア フィルターを引き続き適用してセットを確認できます。 ただし、新しいモデルを作成またはトレーニングすることはできません。
Microsoft Purview eDiscovery (Premium) で予測コーディング モデルを作成した後、次の手順は、最初のトレーニング ラウンドを実行して、レビュー セット内の関連コンテンツと関連性のないコンテンツに関するモデルをトレーニングすることです。 トレーニングの最初のラウンドを完了した後、後続のトレーニング ラウンドを実行して、関連するコンテンツと関連性のないコンテンツを予測するモデルの能力を向上させることができます。
予測コーディング ワークフローを確認するには、「電子情報開示 (Premium) での予測コーディングの詳細」を参照してください。
ヒント
E5 のお客様でない場合は、90 日間の Microsoft Purview ソリューション試用版を使用して、Purview の追加機能が組織のデータ セキュリティとコンプライアンスのニーズの管理にどのように役立つかを確認してください。 Microsoft Purview コンプライアンス ポータルのトライアル ハブで今すぐ開始してください。 サインアップと試用期間の詳細については、こちらをご覧ください。
モデルをトレーニングする前に
- トレーニング ラウンド中に、ドキュメント内のコンテンツの関連性に基づいて、アイテムに [ 関連 ] または [関連しない ] としてラベルを付けます。 メタデータ フィールドの値に基づいて決定しないでください。 たとえば、メール メッセージや Teams の会話の場合、メッセージの参加者にラベル付けの決定を基にしないでください。
初めてモデルをトレーニングする
注:
期間限定で、この従来の電子情報開示エクスペリエンスは、新しい Microsoft Purview ポータルでも利用できます。 電子情報開示 (プレビュー) エクスペリエンス設定でコンプライアンス ポータルのクラシック電子情報開示エクスペリエンスを有効にして、新しい Microsoft Purview ポータルにクラシック エクスペリエンスを表示します。
Microsoft Purview コンプライアンス ポータルで電子情報開示 (Premium) ケースを開き、[レビュー セット] タブを選択します。
レビュー セットを開き、[ Analytics>Manage 予測コーディング (プレビュー)] を選択します。
[ 予測コーディング モデル (プレビュー)] ページで 、トレーニングするモデルを選択します。
[ 概要 ] タブの [ ラウンド 1] で、[ 次のトレーニング ラウンドを開始する] を選択します。
[ トレーニング ] タブが表示され、ラベルを付けるアイテムが 50 個含まれています。
各ドキュメントを確認し、閲覧ウィンドウの下部にある [ 関連] または [ 関連しない ] を選択してラベルを付けます。
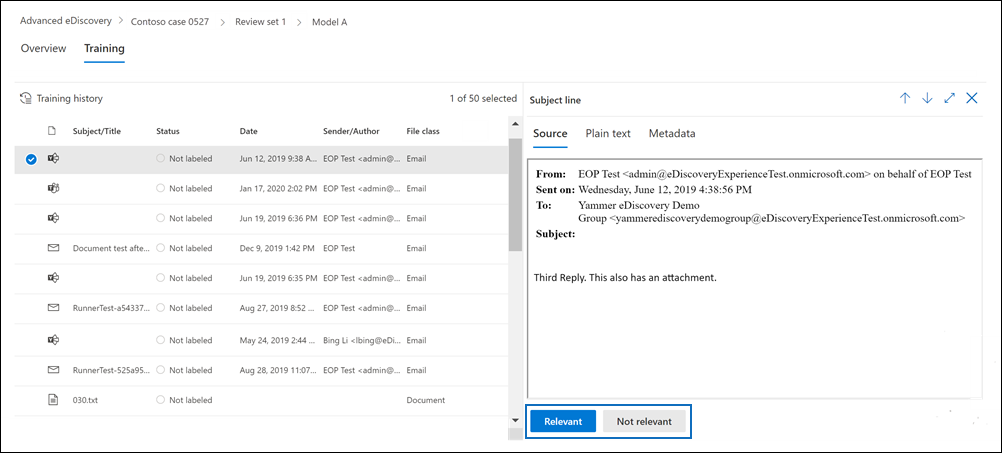
50 個すべての項目にラベルを付けたら、[完了] を選択 します。
システムがラベル付けから "学習" し、モデルを更新するまでに数分かかります。 このプロセスが完了すると、[予測コーディング モデル (プレビュー)] ページにモデルの状態が [準備完了] と表示されます。
追加のトレーニング ラウンドを実行する
トレーニングの最初のラウンドを実行した後、前のセクションの手順に従って、後続のトレーニング ラウンドを実行できます。 唯一の違いは、トレーニング ラウンドの数がモデルの [概要 ] タブで更新されることです。たとえば、最初のトレーニング ラウンドを実行した後、[ 次のトレーニング ラウンドを開始 する] を選択して、2 回目のトレーニングラウンドを開始できます。 などなど。
各トレーニングラウンド (進行中のトレーニングと完了したトレーニングの両方) は、モデルの [ トレーニング ] タブに表示されます。 トレーニング ラウンドを選択すると、ラウンドの情報とメトリックを含むポップアップ ページが表示されます。
トレーニング ラウンドを実行した後の動作
最初のトレーニング ラウンドを実行すると、次のことを行うジョブが開始されます。
トレーニング セット内の 40 個の項目にラベルを付けた方法に基づいて、モデルはラベル付けから学習し、より正確になるように更新します。
次に、モデルはレビュー セット全体の各項目を処理し、予測スコアを 0 (関連なし) から 1 (関連なし) の間で割り当てます。
モデルは、トレーニング ラウンド中にラベル付けしたコントロール セット内の 10 個の項目に予測スコアを割り当てます。 このモデルでは、これらの 10 項目の予測スコアと、トレーニング ラウンド中にアイテムに割り当てた実際のラベルが比較されます。 この比較に基づいて、モデルは次の分類 ( 制御セット混同行列と呼ばれます) を識別して、モデルの予測パフォーマンスを評価します。
| Label | モデルは、項目が関連すると予測します | モデルは項目が関連しないと予測します |
|---|---|---|
| 関連するレビュー担当者ラベル アイテム | 真陽性 | 誤検知 |
| レビュー担当者ラベルアイテムが関連性のないものとして | False の負数 | True 負 |
これらの比較に基づいて、モデルは F スコア、精度、再現率のメトリックの値と、それぞれの誤差のマージンを導き出します。 これらのモデルのパフォーマンス メトリックのスコアは、トレーニング ラウンドのポップアップ ページに表示されます。 これらのメトリックの詳細については、「 予測コーディング リファレンス」を参照してください。
- 最後に、モデルは、次のトレーニング ラウンドに使用される次の 50 個の項目を決定します。 今回は、モデルでコントロール セットから 20 項目、レビュー セットから 30 個の新しい項目を選択し、次のラウンドのトレーニング セットとして指定します。 次のトレーニング ラウンドのサンプリングは均一にサンプリングされません。 モデルは、レビュー セットからの項目のサンプリング選択を最適化して、予測があいまいな項目を選択します。つまり、予測スコアが 0.5 の範囲であることを意味します。 このプロセスは、 バイアス選択と呼ばれます。
後続のトレーニング ラウンドを実行した後の動作
後続のトレーニング ラウンド (最初のトレーニング ラウンドの後) を実行すると、モデルは次のことを行います。
- モデルは、そのトレーニングのラウンドでトレーニング セットに適用したラベルに基づいて更新されます。
- システムは、コントロール セット内の項目に対するモデルの予測スコアを評価し、スコアがコントロール セット内の項目のラベル付け方法と一致するかどうかをチェックします。 評価は、すべてのトレーニング ラウンドに対してコントロール セットからラベル付けされたすべての項目に対して実行されます。 この評価の結果は、モデルの [ 概要 ] タブのダッシュボードに組み込まれます。
- 更新されたモデルは、レビュー セット内のすべての項目を再処理し、各項目に更新された予測スコアを割り当てます。
次の手順
最初のトレーニング ラウンドを実行した後は、より多くのトレーニング ラウンドを実行するか、モデルの予測スコア フィルターをレビュー セットに適用して、モデルが関連性が高いアイテムまたは関連性のないアイテムを表示できます。 詳細については、「 レビュー セットに予測スコア フィルターを適用する」を参照してください。