Xamarin.iOS での音声認識
この記事では、新しい Speech API について説明し、これを Xamarin.iOS アプリに実装して継続的な音声認識をサポートし、音声をテキストに (ライブまたは録音されたオーディオ ストリームから) 文字起こしする方法について説明します。
iOS 10 で、Apple から新しい Speech Recognition API がリリースされ、iOS アプリでこれを使うと、継続的な音声認識をサポートし、(ライブまたは録音されたオーディオ ストリームから) 音声を文字起こしできるようになります。
Apple によると、Speech Recognition API には次の機能と利点があります。
- 高精度
- 最先端
- 使いやすい
- 高速
- 複数言語のサポート
- ユーザー プライバシーの尊重
音声認識のしくみ
音声認識は、ライブまたは事前に録音されたオーディオを (API がサポートする任意の音声言語で) 取得し、音声のプレーンテキスト文字起こしを返す Speech Recognizer に渡すことによって、iOS アプリで実装されます。

キーボード ディクテーション
ほとんどのユーザーが iOS デバイスの音声認識を考えるとき、iPhone 4S の iOS 5 でキーボード ディクテーションと共にリリースされた、組み込みの Siri 音声アシスタントのことを思います。
キーボード ディクテーションは、TextKit をサポートするインターフェイス要素 (UITextField または UITextArea など) でサポートされ、iOS 仮想キーボードのディクテーション ボタン (Space バーのすぐ左側) をクリックするとアクティブになります。
Apple は、次のキーボード ディクテーション統計をリリースしています (2011 年から収集)。
- キーボード ディクテーションは、iOS 5 でリリースされて以来広く使用されています。
- 1 日あたり約 65,000 のアプリで使用されます。
- すべての iOS ディクテーションの約 3 分の 1 はサードパーティのアプリで行われます。
キーボード ディクテーションは、アプリの UI デザインで TextKit インターフェイス要素を使用する以外に、開発者の作業を必要としないため、非常に使いやすいです。 キーボード ディクテーションには、使用するためにアプリから特別な特権要求を必要としないという利点もあります。
新しい Speech Recognition API を使用するアプリでは、音声認識には Apple のサーバーへのデータの転送と一時的な保存が必要であるため、ユーザーが特別なアクセス許可を付与する必要があります。 詳細については、セキュリティとプライバシーの強化に関するドキュメントを参照してください。
キーボード ディクテーションは実装が簡単ですが、いくつかの制限と欠点があります。
- テキスト入力フィールドとキーボードの表示を使用する必要があります。
- ライブ オーディオ入力でのみ機能し、アプリはオーディオ録音プロセスを制御することはできません。
- ユーザーの音声を解釈するために使用される言語は制御できません。
- ユーザーがディクテーション ボタンを使用できるかどうかをアプリが認識する方法はありません。
- アプリはオーディオ録音プロセスをカスタマイズできません。
- 提供される結果セットは非常に浅く、タイミングや信頼度などの情報がありません。
Speech Recognition API
Apple は iOS 10 の新機能である Speech Recognition API をリリースしました。これは、iOS アプリで音声認識を実装するためのより強力な方法を提供します。 この API は、Apple が Siri とキーボード ディクテーションの両方を実行するために使用する API と同じであり、最先端の精度で高速な文字起こしを提供できます。
Speech Recognition API によって提供される結果は、個々のユーザーに対して透過的にカスタマイズされ、アプリでプライベート ユーザー データを収集したり、アクセスしたりする必要はありません。
Speech Recognition API では、ユーザーが話している間、ほぼリアルタイムで呼び出し元アプリに結果が返され、テキストだけでなく翻訳の結果に関する詳細情報を提供します。 これには以下が含まれます。
- ユーザーが言ったことの複数の解釈。
- 個々の翻訳の信頼度レベル。
- タイミング情報。
前述のように、翻訳用のオーディオは、ライブ フィード、または事前に録音されたソースから、iOS 10 でサポートされている 50 を超える言語と方言のいずれかで提供できます。
Speech Recognition API は、iOS 10 を実行している任意の iOS デバイスで使用できます。ほとんどの場合、翻訳の大部分は Apple のサーバーで実行されるため、ライブ インターネット接続が必要です。 ただし、一部の新しい iOS デバイスでは、特定の言語の常にオンになっているオンデバイス翻訳がサポートされています。
Apple は、特定の言語が現在翻訳可能かどうかを判断するための Availability API を含めています。 アプリでは、インターネット接続自体を直接テストするのではなく、この API を使用する必要があります。
キーボード ディクテーションのセクションで述べたように、音声認識にはインターネット経由で Apple のサーバー上のデータの転送と一時的な保存が必要であるため、アプリは、その Info.plist ファイルに NSSpeechRecognitionUsageDescription キーを含めて SFSpeechRecognizer.RequestAuthorization メソッドを呼び出すことによって、認識を行うユーザーのアクセス許可を要求する "必要があります"。
音声認識に使用されているオーディオのソースによっては、アプリの Info.plist ファイルに対するその他の変更が必要になる場合があります。 詳細については、セキュリティとプライバシーの強化に関するドキュメントを参照してください。
アプリでの音声認識の採用
iOS アプリで音声認識を採用するために開発者が実行する必要がある 4 つの主要な手順があります。
NSSpeechRecognitionUsageDescriptionキーを使用して、アプリのInfo.plistファイルに使用方法の説明を提供する。 たとえば、カメラ アプリには次のような説明を含めることができます。"これにより、"チーズ" というだけで写真を撮ることができます"。SFSpeechRecognizer.RequestAuthorizationメソッドを呼び出して承認を要求し、アプリがユーザーに音声認識アクセスを必要とする理由の説明 (上記のNSSpeechRecognitionUsageDescriptionキーで提供) をダイアログ ボックスで提示し、承認または拒否できるようにします。- 音声認識要求を作成します。
- ディスクに事前に録音されたオーディオの場合は、
SFSpeechURLRecognitionRequestクラスを使用します。 - ライブ オーディオ (またはメモリからのオーディオ) の場合は、
SFSPeechAudioBufferRecognitionRequestクラスを使用します。
- ディスクに事前に録音されたオーディオの場合は、
- 音声認識要求を音声認識エンジン (
SFSpeechRecognizer) に渡して認識を開始します。 アプリは必要に応じて、返されたSFSpeechRecognitionTaskを保持して、認識結果を監視および追跡できます。
これらの手順については、以下で詳しく説明します。
使用方法の説明を提供する
Info.plist ファイルに必要な NSSpeechRecognitionUsageDescription キーを指定するには、次の操作を行います。
Info.plistファイルをダブルクリックして編集用に開きます。[ソース] ビューに切り替えます。
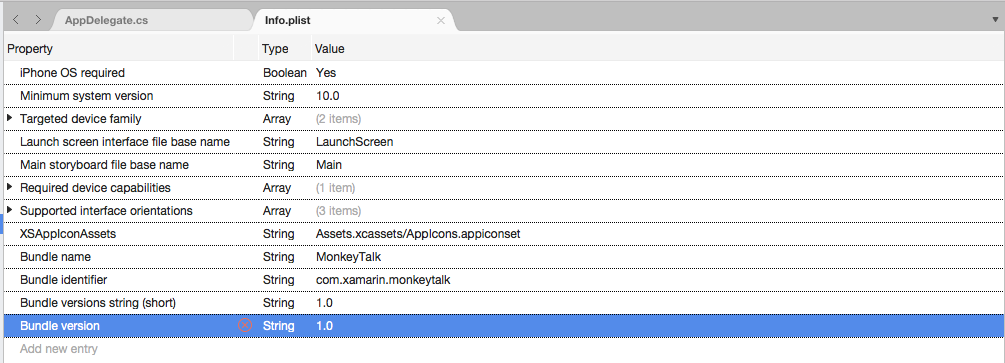
[新しいエントリの追加] をクリックし、[プロパティ] に
NSSpeechRecognitionUsageDescriptionと入力し、[型] としてString、[値] として使用方法の説明を入力します。 次に例を示します。
アプリでライブ オーディオの文字起こしを処理する場合は、マイクの使用に関する説明も必要です。 [新しいエントリの追加] をクリックし、[プロパティ] に
NSMicrophoneUsageDescriptionと入力し、[型] としてString、[値] として使用方法の説明を入力します。 次に例を示します。
変更をファイルに保存します。





重要
上記の Info.plist キー (NSSpeechRecognitionUsageDescription または NSMicrophoneUsageDescription) のいずれかを指定しないと、ライブ オーディオ用に音声認識またはマイクにアクセスしようとしたときに、警告なしでアプリが失敗する可能性があります。
認可の要求
アプリが音声認識にアクセスすることを許可する必要なユーザー認可を要求するには、メインの View Controller クラスを編集し、次のコードを追加します。
using System;
using UIKit;
using Speech;
namespace MonkeyTalk
{
public partial class ViewController : UIViewController
{
protected ViewController (IntPtr handle) : base (handle)
{
// Note: this .ctor should not contain any initialization logic.
}
public override void ViewDidLoad ()
{
base.ViewDidLoad ();
// Request user authorization
SFSpeechRecognizer.RequestAuthorization ((SFSpeechRecognizerAuthorizationStatus status) => {
// Take action based on status
switch (status) {
case SFSpeechRecognizerAuthorizationStatus.Authorized:
// User has approved speech recognition
...
break;
case SFSpeechRecognizerAuthorizationStatus.Denied:
// User has declined speech recognition
...
break;
case SFSpeechRecognizerAuthorizationStatus.NotDetermined:
// Waiting on approval
...
break;
case SFSpeechRecognizerAuthorizationStatus.Restricted:
// The device is not permitted
...
break;
}
});
}
}
}
SFSpeechRecognizer クラスの RequestAuthorization メソッドは、開発者が Info.plist ファイルの NSSpeechRecognitionUsageDescription キーで指定した理由を使用して、音声認識にアクセスするためのアクセス許可をユーザーに要求します。
SFSpeechRecognizerAuthorizationStatus 結果が RequestAuthorization メソッドのコールバック ルーチンに返され、これを使用してユーザーのアクセス許可に基づいてアクションを実行できます。
重要
Apple では、ユーザーが音声認識を必要とするアクションをアプリで開始してから、このアクセス許可を要求することを勧めています。
事前に録音された音声の認識
事前に録音された WAV または MP3 ファイルからアプリで音声を認識する場合は、次のコードを使用できます。
using System;
using UIKit;
using Speech;
using Foundation;
...
public void RecognizeFile (NSUrl url)
{
// Access new recognizer
var recognizer = new SFSpeechRecognizer ();
// Is the default language supported?
if (recognizer == null) {
// No, return to caller
return;
}
// Is recognition available?
if (!recognizer.Available) {
// No, return to caller
return;
}
// Create recognition task and start recognition
var request = new SFSpeechUrlRecognitionRequest (url);
recognizer.GetRecognitionTask (request, (SFSpeechRecognitionResult result, NSError err) => {
// Was there an error?
if (err != null) {
// Handle error
...
} else {
// Is this the final translation?
if (result.Final) {
Console.WriteLine ("You said, \"{0}\".", result.BestTranscription.FormattedString);
}
}
});
}
このコードを詳しく見ると、まず音声認識エンジン (SFSpeechRecognizer) の作成が試みられています。 既定の言語が音声認識でサポートされていない場合は、null が返され、関数は終了します。
既定の言語で音声認識エンジンを使用できる場合、アプリは Available プロパティを使用してそれが現在認識に使用できるかどうかをチェックします。 たとえば、デバイスにアクティブなインターネット接続がない場合、認識が使用できない場合があります。
iOS デバイス上の事前に録音されたファイルの NSUrl の場所から SFSpeechUrlRecognitionRequest が作成され、コールバック ルーチンで処理するために音声認識エンジンに渡されます。
コールバックが呼び出されたときに、NSError が null でない場合は、処理する必要があるエラーが発生しています。 音声認識は段階的に行われるため、コールバック ルーチンを複数回呼び出してSFSpeechRecognitionResult.Final プロパティをテストし、翻訳が完了し、翻訳の最適なバージョンが書き出されたかどうかを確認できます (BestTranscription)。
ライブ音声の認識
アプリでライブ音声を認識する場合、プロセスは事前に録音された音声を認識する場合とよく似ています。 次に例を示します。
using System;
using UIKit;
using Speech;
using Foundation;
using AVFoundation;
...
#region Private Variables
private AVAudioEngine AudioEngine = new AVAudioEngine ();
private SFSpeechRecognizer SpeechRecognizer = new SFSpeechRecognizer ();
private SFSpeechAudioBufferRecognitionRequest LiveSpeechRequest = new SFSpeechAudioBufferRecognitionRequest ();
private SFSpeechRecognitionTask RecognitionTask;
#endregion
...
public void StartRecording ()
{
// Setup audio session
var node = AudioEngine.InputNode;
var recordingFormat = node.GetBusOutputFormat (0);
node.InstallTapOnBus (0, 1024, recordingFormat, (AVAudioPcmBuffer buffer, AVAudioTime when) => {
// Append buffer to recognition request
LiveSpeechRequest.Append (buffer);
});
// Start recording
AudioEngine.Prepare ();
NSError error;
AudioEngine.StartAndReturnError (out error);
// Did recording start?
if (error != null) {
// Handle error and return
...
return;
}
// Start recognition
RecognitionTask = SpeechRecognizer.GetRecognitionTask (LiveSpeechRequest, (SFSpeechRecognitionResult result, NSError err) => {
// Was there an error?
if (err != null) {
// Handle error
...
} else {
// Is this the final translation?
if (result.Final) {
Console.WriteLine ("You said \"{0}\".", result.BestTranscription.FormattedString);
}
}
});
}
public void StopRecording ()
{
AudioEngine.Stop ();
LiveSpeechRequest.EndAudio ();
}
public void CancelRecording ()
{
AudioEngine.Stop ();
RecognitionTask.Cancel ();
}
このコードを詳しく見ると、認識プロセスを処理するためにいくつかのプライベート変数が作成されています。
private AVAudioEngine AudioEngine = new AVAudioEngine ();
private SFSpeechRecognizer SpeechRecognizer = new SFSpeechRecognizer ();
private SFSpeechAudioBufferRecognitionRequest LiveSpeechRequest = new SFSpeechAudioBufferRecognitionRequest ();
private SFSpeechRecognitionTask RecognitionTask;
AV Foundation を使用して、認識要求を処理するために SFSpeechAudioBufferRecognitionRequest に渡されるオーディオを録音します。
var node = AudioEngine.InputNode;
var recordingFormat = node.GetBusOutputFormat (0);
node.InstallTapOnBus (0, 1024, recordingFormat, (AVAudioPcmBuffer buffer, AVAudioTime when) => {
// Append buffer to recognition request
LiveSpeechRequest.Append (buffer);
});
アプリは録音を開始しようとし、録音を開始できない場合はエラーが処理されます。
AudioEngine.Prepare ();
NSError error;
AudioEngine.StartAndReturnError (out error);
// Did recording start?
if (error != null) {
// Handle error and return
...
return;
}
認識タスクが開始され、ハンドルが認識タスク (SFSpeechRecognitionTask) に対して維持されます。
RecognitionTask = SpeechRecognizer.GetRecognitionTask (LiveSpeechRequest, (SFSpeechRecognitionResult result, NSError err) => {
...
});
上記の事前録音された音声で使用したものと同様の方法でコールバックが使用されます。
ユーザーが録音を停止すると、オーディオ エンジンと音声認識要求の両方に通知されます。
AudioEngine.Stop ();
LiveSpeechRequest.EndAudio ();
ユーザーが認識を取り消すと、オーディオ エンジンと認識タスクに通知されます。
AudioEngine.Stop ();
RecognitionTask.Cancel ();
ユーザーが翻訳をキャンセルした場合、RecognitionTask.Cancel を呼び出してメモリとデバイスのプロセッサの両方を解放することが重要です。
重要
NSSpeechRecognitionUsageDescriptionキーまたはNSMicrophoneUsageDescription Info.plist キーを指定しないと、音声認識またはマイクにライブ オーディオ (var node = AudioEngine.InputNode;) にアクセスしようとすると、警告なしにアプリが失敗する可能性があります。 詳細については、上記の「使用方法の説明を提供する」セクションを参照してください。
音声認識の制限
Apple では、iOS アプリで音声認識を使用する場合に、次の制限を課しています。
- 音声認識はすべてのアプリで無料ですが、その使用方法は無制限ではありません。
- 個々の iOS デバイスでは、1 日に実行できる認識の数が限られています。
- アプリは、1 日あたりの要求に基づいてグローバルでスロットルされます。
- アプリは、音声認識ネットワーク接続と使用量制限エラーを処理するように準備する必要があります。
- 音声認識は、ユーザーの iOS デバイス上でバッテリの枯渇と高いネットワーク トラフィックの両方で高いコストを発生させる可能性があります。このため、Apple は最大約 1 分の音声という厳格なオーディオ継続時間制限を課しています。
アプリが定期的にレート調整の制限に達している場合、Apple は開発者に連絡するよう求めます。
プライバシーと使いやすさに関する考慮事項
Apple は、音声認識を含める iOS アプリが、透過的であり、ユーザーのプライバシーを尊重するように、以下のことを推奨しています。
- ユーザーの音声を録音するときは、アプリのユーザー インターフェイスに録音が行われていることを明確に示してください。 たとえば、アプリで "録音" の音を再生し、録音中インジケーターを表示します。
- パスワード、医療データ、財務情報などの機密性の高いユーザー情報には音声認識を使用しないでください。
- 認識結果は、操作する "前" にユーザーに表示します。 これにより、アプリの実行内容に関するフィードバックが提供されるだけでなく、ユーザーは認識エラーが発生した時点で対処できます。
まとめ
この記事では、新しい Speech API について説明し、これを Xamarin.iOS アプリに実装して継続的な音声認識をサポートし、音声をテキストに (ライブまたは録音されたオーディオ ストリームから) 文字起こしする方法について説明しました。