SQL Server
SQL Server のログ記録と復旧について
Paul S. Randal
概要:
- SQL Server のログ記録と復旧のしくみ
- トランザクション ログのしくみとトランザクション ログの管理に必要な知識
- 復旧モデルの種類とログ記録への影響
目次
ログ記録とは
復旧とは
トランザクション ログ
復旧モデル
まとめ
SQL Server で特に誤解されやすいのが、ログ記録と復旧のメカニズムです。トランザクション ログが存在していること自体、およびトランザクション ログを適切に管理しないと問題の原因になることに、多くの "不本意な DBA" の皆さんは困惑しているようです。トランザクション ログのサイズが際限なく増加していくことがあるのはなぜでしょう。システムがクラッシュした後、データベースがオンラインに復帰するまで非常に時間がかかることがあるのはなぜでしょう。ログ記録を完全には無効にできないのはなぜでしょう。データベースを正しく復旧できないのはなぜでしょう。トランザクション ログとはそもそもどのようなもので、なぜ存在するのでしょう。
このような疑問は、どれも SQL Server フォーラムやニュースグループで何度も見かけるものです。そこで、この記事では、ログ記録と復旧システムの概要を説明し、このシステムが SQL Server ストレージ エンジンのいかに不可欠な部分であるかを説明します。トランザクション ログのアーキテクチャについて説明し、データベースに利用できる 3 つの復旧モデルによってトランザクション ログの動作やログ記録処理自体が変化するようすを説明します。また、トランザクション ログ管理のベスト プラクティスを扱っているリソースへのリンクも紹介します。
ログ記録とは
ログ記録と復旧は、SQL Server 特有の概念ではありません。すべての市販のリレーショナル データベース管理システム (RDBMS) は、トランザクションのさまざまな ACID 属性をサポートするために、こうした概念を備えていなければなりません。ACID は、原子性 (Atomicity)、一貫性 (Consistency)、分離性 (Isolation)、持続性 (Durability) を表す頭字語で、(RDBMS などの) トランザクション処理システムが備える基本属性です。ACID の詳細については、MSDN ライブラリの「ACID 属性」を参照してください。
RDBMS での操作は、データベースのストレージ構造内で行われることに関して、物理レベルでも論理レベルでもログ記録 (記録) されます。ストレージ構造に対するすべての変更にはそれぞれ独自のログ レコードが対応し、変更対象の構造と変更内容が記録されます。これは、必要に応じて変更を再現したり元に戻したりできるような方法で行われます。ログ レコードは、トランザクション ログと呼ばれる特殊なファイルに格納されます。トランザクション ログについては後でもっと詳しく説明しますが、今のところは順次アクセス ファイルと考えてかまいません。
このような 1 つ以上の一連の変更をまとめて、トランザクションにグループ化することができます (実際は必ずまとめられます)。ユーザー、アプリケーション開発者、DBA が変更を行う場合、このトランザクションがデータベースに行う変更の基本単位 (原子性) になります。トランザクションは、成功する (コミット) か、失敗したりキャンセルされたりする (ロールバック) かのいずれかです。成功すれば、トランザクション内で行われる操作がデータベースに反映されることが保証されます。失敗またはキャンセルされると、操作がデータベースに反映されないことが保証されます。
SQL Server のトランザクションには、明示的なトランザクションと暗黙のトランザクションがあります。明示的なトランザクションでは、ユーザーまたはアプリケーションから BEGIN TRANSACTION T-SQL ステートメントが発行され、そのセッションから関連する変更のグループの開始が通知されます。明示的なトランザクションは、COMMIT TRANSACTION ステートメントが発行され、変更のグループが正常に完了したことが通知されると成功します。ROLLBACK TRANSACTION ステートメントが発行された場合は、BEGIN TRANSACTION ステートメントの発行以降、そのセッションで行われた変更がすべて元に戻され (ロールバックされ)、トランザクションが中止されます。後で説明するように、データベースのディスク領域が不足した場合、サーバーがクラッシュした場合など、外部イベントによってトランザクションのロールバックが行われることもあります。
暗黙のトランザクションでは、T-SQL ステートメントの実行前にユーザーやアプリケーションから BEGIN TRANSACTION ステートメントが明示的に発行されません。ただし、データベースに行われる変更はすべてトランザクションとして実行される必要があるため、ストレージ エンジンによって内部で自動的にトランザクションが開始されます。その T-SQL ステートメントが完了すると、ユーザーのステートメントを含むように開始されたトランザクションがストレージ エンジンによって自動的にコミットされます。
1 つの T-SQL ステートメントからデータベースのストレージ構造に対して多数の変更が行われることはないため不要だと思われるかもしれませんが、ALTER INDEX REBUILD ステートメントのような例を考えてみてください。このステートメントを明示的なトランザクションに含めることはできませんが、このステートメントではデータベースに対して大量の変更が行われます。したがって、問題が発生した場合 (ステートメントがキャンセルされた場合など) に、すべての変更が正しく元に戻されるようにするメカニズムが必要です。
たとえば、1 行のテーブル行が暗黙のトランザクションによって更新されると、どうなるか考えてみましょう。整数型の列 c1 と文字型の列 c2 が含まれている単純なヒープ テーブルがあるとします。テーブルには 10,000 行あり、ユーザーが次のような更新クエリを送信します。
UPDATE SimpleTable SET c1 = 10 WHERE c2 LIKE '%Paul%';
すると、次のような操作が行われます。
- SimpleTable のデータ ページがディスクからメモリ (バッファ プール) に読み取られ、一致する行を検索できるようになります。3 ページ分のデータ ページに、WHERE 句の述語に一致する行が 5 行見つかります。
- ストレージ エンジンによって、暗黙のトランザクションが自動的に開始されます。
- 更新を実行できるように、3 ページ分のデータ ページと 5 行のデータ行がロックされます。
- メモリ内の 3 ページのデータ ページにある 5 つのデータ レコードに変更が行われます。
- 変更は、ディスク上のトランザクション ログ内のログ レコードにも記録されます。
- ストレージ エンジンによって、暗黙のトランザクションが自動的にコミットされます。
3 ページ分のデータ ページがディスクに再び書き込まれる手順を一覧に記載しなかったことに注目してください。これは、まだ書き込む必要がないためです。トランザクション ログ内のログ レコードでディスクに変更が行われると記録されている限り、変更は保護されます。このページを続けて読み取ったり再度変更したりする必要がある場合、ページの最新のコピーは既にメモリ内に存在しています。ディスク上には (まだ) ありません。データ ページがディスクに書き込まれるのは、次のチェックポイント操作が発生したときか、バッファ プールに使用されているメモリが別のページ イメージ用に必要になったときです。
チェック ポイントが存在する理由は 2 つあります。書き込み I/O をまとめてパフォーマンスを向上すること、およびクラッシュ復旧にかかる時間を短縮することです。パフォーマンスの面では、データ ページが更新されるたびにデータ ページがディスクに書き込まれると、負荷の高いシステムで行われる書き込み I/O の数で I/O サブシステムが簡単にいっぱいになってしまいます。ダーティ ページ (ディスクから読み取られた後で変更されたページ) を定期的に書き込む方が、変更後すぐにページを書き込むよりもパフォーマンスが向上します。チェックポイントの復旧に関する側面については、後で説明します。
チェックポイントに関するよくある誤解は、チェックポイントではコミットされたトランザクションから変更されたページだけが書き込まれるというものです。この考えは正しくありません。チェックポイントでは、ページを変更したトランザクションがコミットされたかどうかに関係なく、すべてのダーティ ページが書き込まれます。
先書きログとは、変更自体が書き込まれる前に、変更内容を記録したログ レコードがディスクに書き込まれるメカニズムです。このメカニズムによって、ACID 属性の持続性が確保されます。変更内容を記録するログ レコードがディスク上にある限り、クラッシュが発生してもログ レコード (つまり変更そのもの) を復旧できるため、トランザクションの効果は失われません。
復旧とは
ログ記録の目的は、SQL Server のさまざまな操作をサポートすることです。クラッシュが発生した場合は、コミットされたトランザクションがクラッシュ後のデータベースに正しく反映されます。コミットされていないトランザクションは正しくロールバックされ、クラッシュ後のデータベースには反映されません。実行中のトランザクションをキャンセルして、すべての操作をロールバックできます。データベースを復元できるようトランザクション ログのバックアップ コピーを作成でき、トランザクション ログのバックアップを再生して、トランザクションの一貫性が確保されていた特定の時点の状態にデータベースを戻すことができます。また、ログ記録ではレプリケーション、データベース ミラーリング、Change Data Capture など、トランザクション ログの読み取りに依存する機能がサポートされています。
ログ記録のこのような使用方法の大部分は、復旧と呼ばれるメカニズムに関係しています。復旧は、ログ レコードに記録されている変更内容をデータベースで再生したり元に戻したりする処理です。ログ レコードの再生は、復旧の再実行 (ロールフォワード) フェーズと呼ばれます。ログ レコードを元に戻すことは、復旧の元に戻す (ロールバック) フェーズと呼ばれます。つまり、復旧によって、トランザクションとその構成ログ レコードは、再実行されるか、元に戻されます。
復旧の簡単な形式は、1 つのトランザクションがキャンセルされた場合です。この場合はトランザクションが元に戻され、データベースに対する実質的な影響はありません。最も複雑な形式は、クラッシュ復旧です。この場合は、SQL Server が (なんらかの理由で) クラッシュし、トランザクション ログを復旧してデータベースをトランザクションの一貫性がある状態にする必要があります。つまり、クラッシュの時点でコミットされていたすべてのトランザクションをロールフォワードして、データベースでトランザクションの効果が保持されるようにする必要があります。また、クラッシュの時点でコミットされていなかった実行中の全トランザクションをロールバックして、データベースにトランザクションの影響が残らないようにする必要があります。
これは、SQL Server のトランザクションにはクラッシュ後も続行する機能が存在しないためです。したがって、部分的に完了したトランザクションの結果がロールバックされないと、データベースが一貫性のない状態のままになります (実行中だったトランザクションによっては、構造が破損する場合もあります)。
では、復旧では、実行すべき処理がどのようにして決定されるのでしょうか。すべての復旧処理は、各ログ レコードにログ シーケンス番号 (LSN) が設定されている点に基づいています。ログ シーケンス番号は、常に増加する、3 つの部分から構成される番号で、トランザクション ログ内のログ レコードの位置を一意に定義します。トランザクションの各ログ レコードはトランザクション ログに順番に格納され、トランザクション ID とそのトランザクションの直前のログ レコードの LSN を含みます。つまり、トランザクションの一部として記録される各操作には、直前の操作に戻る "リンク" があります。
1 つのトランザクションがロールバックされるような単純な例では、復旧メカニズムによりログに記録された操作のチェーンを最近の操作から最初の操作に向けて簡単にすばやくさかのぼり、実行とは逆の順序で操作の効果を元に戻すことができます。トランザクションの影響を受けたデータベース ページは、まだバッファ プールに残っているか、ディスクに書き込まれたかのいずれかです。どちらの場合でも、使用できるページのイメージは、トランザクションの効果が反映されていることが保証されており、元に戻す必要があります。
クラッシュ復旧中のメカニズムはもっと複雑です。トランザクションがコミットされた時点ではデータベース ページがディスクに書き込まれていないため、ディスク上のデータベース ページのセットが (コミットされたトランザクションでもコミットされていないトランザクションでも) トランザクション ログに記録されている一連の変更内容を正確に反映しているとは限りません。ただし、皆さんにはまだお伝えしていないパズルの最後の 1 ピースがあります。すべてのデータベース ページには、ページ ヘッダー (ページに関するメタデータが含まれた 8192 バイトのページの中の 96 バイト部分) にフィールドがあり、このフィールドにページに影響を与えた最後のログ レコードの LSN が格納されています。復旧システムではこのヘッダーを使用して、復旧が必要な特定のログ レコードへの対応を次のように決定できます。
- コミットされたトランザクションのログ レコードで、データベース ページの LSN がログ レコードの LSN 以上の場合は、何も実行する必要はありません。ログ レコードの結果は、既にディスク上のページに保存されています。
- コミットされたトランザクションのログ レコードで、データベース ページの LSN がログ レコードの LSN 未満の場合は、トランザクションの結果を保存するためにログ レコードを再実行する必要があります。
- コミットされていないトランザクションのログ レコードで、データベース ページの LSN がログ レコードの LSN 以上の場合は、トランザクションの結果が保存されないようにログ レコードを元に戻す必要があります。
- コミットされていないトランザクションのログ レコードで、データベース ページの LSN がログ レコードの LSN 未満の場合は、何も実行する必要はありません。ログ レコードの結果はディスク上のページには保存されていないため、元に戻す必要はありません。
クラッシュ復旧によってトランザクション ログが読み取られ、コミットされたすべてのトランザクションの結果がすべてデータベースに保存されるようになり、コミットされていないすべてのトランザクションの結果はまったくデータベースに残らないようになります。これらの処理をそれぞれ再実行フェーズと元に戻すフェーズと言います。クラッシュ復旧が完了すると、データベースのトランザクションが一貫性のある状態になり、データベースを使用できるようになります。
既に述べましたが、チェックポイント操作の用途の 1 つは、クラッシュ復旧にかかる時間の短縮です。すべてのダーティ ページを定期的にフラッシュすることで、コミットされたトランザクションによって変更されているのにディスクに保存されていないイメージのページ数が減少します。この結果、クラッシュ復旧中に再実行フェーズを適用する必要があるページ数が減少します。
トランザクション ログ
クラッシュ復旧を実行できるのは、トランザクション ログが破損していない場合だけです。実際、トランザクション ログは、データベースの最も重要な部分です。クラッシュした場合、データベースに対するすべての変更内容が記録されている保証があるのは、ここだけです。
クラッシュ後にトランザクション ログが欠落または破損していると、クラッシュ復旧を完了できず、データベースの信頼性が低下します。その場合、データベースをバックアップから復元したり、緊急モードでの修復などのあまり望ましくない手段を使用して復旧したりする必要があります (これらの手順についてはこの記事では扱いませんが、今年の記事で詳しく取り上げる予定です)。
トランザクション ログは、データベースが正常に機能するために各データベースに必要な特殊なファイルです。このファイルには、ログ記録によって作成されたログ レコードが格納され、復旧中にログ レコードを再読み取りするために使用されます (または既に説明したようなログ記録の他のいずれかの用途に使用されます)。ログ レコード自体に必要な領域だけでなく、トランザクションがキャンセルされてロールバックを実行しなければならない場合に必要なログ レコードの領域もトランザクション ログ内に確保されます。つまり、たとえばデータベース内の 50 MB のデータを更新するトランザクションに実際は 100 MB のトランザクション ログ領域が必要になる場合があります。
新しいデータベースを作成した時点では、トランザクション ログは事実上空です。トランザクションが実行されると、ログ レコードがトランザクション ログに順番に書き込まれます。つまり、非常に誤解されやすい点ですが、複数のトランザクション ログ ファイルを作成してもパフォーマンスは向上しません。トランザクション ログでは、各ログ ファイルが順番に使用されます。
同時に実行される複数のトランザクションのログ レコードは、トランザクション ログ内に分散していることがあります。1 つのトランザクションのログ レコードは、その LSN によってリンクされるため、トランザクションのすべてのログ レコードが同一ログ内にグループとしてまとめられている必要はありません。LSN は、タイムスタンプのようなものと考えてもよいでしょう。
トランザクション ログの物理アーキテクチャは、図 1 のとおりです。トランザクション ログは、内部で仮想ログ ファイル (VLF) と呼ばれる小さいまとまりに分けられています。VLF は、単にトランザクション ログの内部管理を容易にするためのものです。ログ記録は VLF がいっぱいになると、自動的にトランザクション ログの次の VLF を使用するようになります。この説明ではトランザクション ログ領域が最終的には不足すると思われるかもしれませんが、この点こそトランザクション ログがデータ ファイルと異なっている部分です。
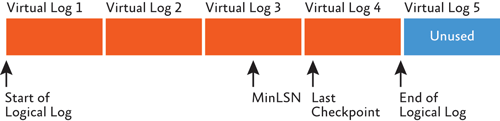
図 1 トランザクション ログの物理アーキテクチャ
トランザクション ログは、実際には循環ファイルです。ただし、トランザクション ログの先頭のログ レコードが切り捨てられて (クリアされて) いる場合に限ります。ログ記録がトランザクション ログの末尾に到達すると、再びファイルの先頭に戻って、以前のデータへの上書きを開始します。
では、どのようにログ レコードを切り捨てて、ログ レコードに使用されていた領域を再利用できるようにしているのでしょうか。次の条件がすべて満たされていれば、ログ レコードはトランザクション ログで不要になります。
- そのログ レコードが含まれているトランザクションがコミットされている。
- そのログ レコードによって変更されたデータベース ページがチェックポイントによってすべてディスクに書き込まれている。
- バックアップ (完全バックアップ、差分バックアップ、またはログ バックアップ) でそのログ レコードが必要ない。
- ログを読み取るあらゆる機能 (データベース ミラーリング、レプリケーションなど) でそのログ レコードが必要ない。
まだ必要なログ レコードは "アクティブ" と呼ばれ、アクティブなログ レコードが少なくとも 1 つある VLF も "アクティブ" と呼ばれます。満杯になった VLF のすべてのログ レコードがアクティブかどうかについて、トランザクション ログが頻繁に確認されます。ログ レコードがすべて非アクティブな場合、VLF は切り捨てられた (つまり、トランザクション ログが先頭に戻ったらその VLF を上書きできる) とマークされます。VLF は、切り捨てられるときに、上書きされたりゼロ クリアされたりすることはありません。切り捨てられたとマークされて再利用できるようになるだけです。
この処理が "ログの切り捨て" と呼ばれます。トランザクション ログのサイズを実際に圧縮することと混同しないように注意してください。ログを切り捨ててもトランザクション ログの物理サイズは変化しません。トランザクション ログのその部分がアクティブかどうかが切り替わるだけです。図 2 は、切り捨てが行われた後の図 1 のトランザクション ログを示しています。
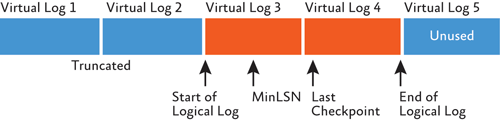
図 2 切り捨て後のトランザクション ログ
アクティブな VLF で構成されているのが論理ログ、つまりトランザクション ログのすべてのアクティブなログ レコードが含まれている部分です。ログのアクティブな部分に含まれているログ レコードをクラッシュ復旧で読み取り始める箇所は、データベース自体が認識しており、ログで最も古いアクティブなトランザクションの開始点、つまり MinLSN です (これはデータベース ブート ページに格納されています)。
クラッシュ復旧では、ログ レコードの読み取りを終了する箇所が不明なので、トランザクション ログのゼロになっているセクション (トランザクション ログが先頭に戻っていない場合)、またはパリティ ビットが直前のログ レコードのシーケンスと一致しないログ レコードに到達するまで読み取り続けます。
VLF が切り捨てられて新しい VLF がアクティブになるに従って、論理ログは物理トランザクション ログ ファイル内を移動し、最終的に先頭に戻ります (図 3 参照)。
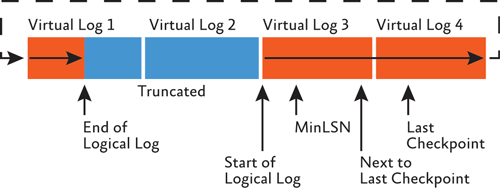
図 3 トランザクション ログの循環性
次のいずれかの状況でログを切り捨てられるかどうかを確認します。
- 単純復旧モデル、または完全バックアップが行われていないその他の復旧モデルでチェックポイントが発生するとき (後者の復旧モデルは、データベースが単純復旧モデルから切り替えられた後、データベースの完全バックアップが実行されるまで擬似的に単純復旧モデルのままになっていることを意味します)。
- ログのバックアップが完了するとき。
さまざまな理由からログ レコードをアクティブなままにしておく必要があり、ログを切り捨てられない場合があります。ログを切り捨られない場合、VLF を切り捨てられず、最終的にはトランザクション ログのサイズが増加します (または、別のトランザクション ログ ファイルが追加されます)。トランザクション ログのサイズが大きくなりすぎると、VLF の断片化と呼ばれる現象によってパフォーマンスの問題が発生する場合があります。VLF の断片化を解消すると、ログに関連する処理のパフォーマンスが劇的に向上することもあります。
詳細については、Kimberly Tripp のブログ記事「8 Steps to Better Transaction Log Throughput (トランザクション ログのスループットを高める 8 つの手順)」を参照してください。Kimberly は、トランザクション ログの容量計画、管理、およびパフォーマンスの向上に関するベスト プラクティスを紹介しています。これは非常に読む価値の高い記事です。
主に次の 2 つの問題からログを切り捨てられなくなります。
- 長時間実行されているアクティブなトランザクション。最も古いアクティブなトランザクションを先頭ログ レコードとするトランザクション ログ全体は、そのトランザクションがコミットまたはアボートされるまで切り捨てることができません。
- 完全復旧モデルに切り替え、完全バックアップを行ってから、ログ バックアップをまったく行っていない場合。トランザクション ログ全体がアクティブなままになり、ログ バックアップによるバックアップを待機しています。
ログを切り捨てられなくなる要因と、その特定方法の説明の完全な一覧については、SQL Server オンラインブックの「ログの切り捨てが遅れる原因となる要因」を参照してください。また、管理されていないトランザクション ログのサイズの増加の影響と VLF の断片化の解消方法について説明しているビデオ デモンストレーションも作成しました。technetmagazine.com/videos でこのビデオ スクリーンキャスト (および SQL に関するトピックの以前のスクリーンキャスト) をご覧ください。
トランザクション ログのサイズが容量いっぱいまで増加して、それ以上増加できなくなると、エラー 9002 が報告されます。このような場合、ログ ファイルのサイズを増加する、別のログ ファイルを追加する、ログの切り捨てを妨げている要因を取り除くなど、領域を増やすための対策を講じる必要があります。
どのような場合であっても、トランザクション ログの削除、公開されていないコマンドを使用したトランザクション ログの再構築、または BACKUP LOG の NO_LOG オプションや TRUNCATE_ONLY オプション (どちらも SQL Server 2008 で削除) を使用した切り捨てを行わないでください。これらのオプションを使用すると、トランザクションの不整合 (おそらくは破損) が発生するか、データベースを正常に復旧できる見込みがなくなります。
満杯になったトランザクション ログのトラブルシューティング方法の詳細については、オンライン ブックの「満杯になったトランザクション ログのトラブルシューティング (エラー 9002)」を参照してください。
復旧モデル
既におわかりのように、トランザクション ログの動作は、データベースで使用している復旧モデルによって部分的に異なります。使用できる復旧モデルは 3 種類あり、すべての復旧モデルは、トランザクション ログの動作、操作のログ記録方法、またはその両方に影響を及ぼします。
完全復旧モデルでは、すべての操作のすべての部分がログ記録されます (完全なログ記録と呼ばれます)。完全復旧モデルでデータベースの完全バックアップが行われると、ログ バックアップが行われるまでトランザクション ログの切り捨ては自動的には行われません。ログ バックアップ、およびデータベースを特定の時点に戻す機能を使用する必要がない場合は、完全復旧モデルを使用しないでください。ただし、データベース ミラーリングを実行する場合は、完全復旧モデルしかサポートされないので選択の余地はありません。
一括ログ復旧モデルのトランザクション ログの切り捨てセマンティクスは完全復旧モデルと同じですが、一部の操作は部分的にログ記録できます (最小ログ記録と呼ばれます)。最小ログ記録の対象になるのは、たとえば、インデックスの再構築や一部の一括読み込み操作です。完全復旧モデルでは、すべての操作がログ記録されます。
しかし、一括ログ復旧モデルの場合、アロケーションの変更のみがログ記録されるため、作成されるログ レコードの数が大幅に減少し、トランザクション ログのサイズが大きくなる可能性が少なくなります。最小ログ記録の対象となる操作の詳細については、オンライン ブックの「最小ログ記録が可能な操作」を参照してください。
最後に、単純復旧モデルのログ記録動作は、実質的に一括ログ復旧と同じですが、トランザクション ログの切り捨てセマンティクスがかなり異なっています。単純復旧モデルではログをバックアップできないので、チェックポイントが発生すると (他の要因によってログ レコードがアクティブなままになっていない限り)、ログは切り捨てられます。これらの各復旧モデルには、バックアップ可能かどうか (必要かどうか)、およびさまざまな時点に復旧する機能について、賛否両論あります (この点については今年の別の記事で扱います)。
まとめ
この記事では、SQL Server の重要な部分のしくみについて非常に学術的に説明しました。皆さんの誤解を解くことができていればさいわいです。この記事で初めてログ記録と復旧について触れた方のために述べると、この記事から学んでいただきたい重要なポイントは次のとおりです。
- パフォーマンスの向上にはつながらないので、ログ ファイルを複数作成しない。
- データベースで使用している復旧モデル、および復旧モデルのトランザクション ログに対する影響 (特に、チェックポイントの発生時に、トランザクション ログを自動的に切り捨てられるかどうか) に注意する。
- トランザクション ログのサイズが増加する可能性、サイズの増加につながる要因、および制御を取り戻す方法に注意する。
- 満杯になったトランザクション ログのトラブルシューティングを行う際のヘルプの参照先を知る。
私のブログでは、トランザクション ログ、およびトランザクション ログに影響を与える要因に関する詳しい情報を掲載しています。詳細については、「Shrinking the database before taking a backup (バックアップの作成前にデータベースを圧縮する)」を参照してください。トランザクション ログに関するオンライン ブックのさまざまなトピックも非常に役立ちます。まずは、「トランザクション ログの管理」をご覧ください。
いつものように、ご意見やご質問は Paul@SQLskills.com (英語のみ) までお寄せください。
この記事の技術校閲者を務めてくれた Kimberly L. Tripp に感謝します。
Paul S. Randal は SQLskills.com の代表取締役であり、SQL Server MVP でもあります。1999 年から 2007 年までは、マイクロソフトの SQL Server ストレージ エンジン チームに所属していました。また、『DBCC CHECKDB/repair for SQL Server 2005』を執筆し、SQL Server 2008 の開発時にはコア ストレージ エンジンを担当していました。Paul は障害回復、高可用性、およびデータベース メンテナンスの専門家であり、世界中のカンファレンスで定期的に発表を行っています。彼のブログは SQLskills.com/blogs/paul で公開されています。