複数の GPU とマシン
1.はじめに
CNTK では現在、4 つの並列 SGD アルゴリズムがサポートされています。
前提条件
並列トレーニングを実行するには、メッセージ パッシング インターフェイス (MPI) の実装がインストールされていることを確認します。
Windows では、 Microsoft MPI (MS-MPI) のバージョン 7 (7.0.12437.6) をインストールします。 [ダウンロード] ボタンをクリックし、実行時 (
MSMpiSetup.exe) を選択します。Linux では、OpenMPI バージョン 1.10.x をインストールします。 ここでの手順に従って、自分でビルドしてください。
2. Python での CNTK での並列トレーニングの構成
Python でデータ並列 SGD を使用するには、ユーザーが分散学習者を作成してトレーナーに渡す必要があります。
from cntk import distributed
...
learner = cntk.learner.momentum_sgd(...) # create local learner
distributed_after = epoch_size # number of samples to warm start with
distributed_learner = distributed.data_parallel_distributed_learner(
learner = learner,
num_quantization_bits = 32, # non-quantized gradient accumulation
distributed_after = 0) # no warm start
...
minibatch_source = MinibatchSource(...)
...
trainer = Trainer(z, ce, pe, distributed_learner)
...
session = training_session(trainer=trainer, mb_source=minibatch_source, ...)
session.train()
...
distributed.Communicator.finalize() # must be called to finalize MPI in case of successful distributed training
ユーザー定義のトレーニング ループ (training_sessionではなく) の場合、ユーザーは、異なる MPI ノードが (サンプルのnum_data_partitionspartition_index読み取り後distributed_afterに) 異なるデータ パーティションからデータをMinibatchSource.next_minibatch()読み取るように、メソッドに渡す必要があります。
分散トレーニングが Communicator.finalize() 正常に完了した場合にのみ呼び出す必要があることに注意してください。 分散ワーカーが失敗した場合は、このメソッドを呼び出さないでください。
完全に機能する例については、 ConvNet の例を参照してください。
3. BrainScript での CNTK での並列トレーニングの構成
CNTK BrainScript で並列トレーニングを有効にするには、まず、構成ファイルまたはコマンド ラインで次のスイッチをオンにする必要があります。
parallelTrain = true
第 2 に、 SGD 構成ファイル内のブロックには、次の引数を含むサブ ParallelTrain ブロックが含まれている必要があります。
parallelizationMethod: (必須) 正当な値はDataParallelSGD、、BlockMomentumSGDおよびModelAveragingSGD.これは、使用する並列アルゴリズムを指定します。
distributedMBReading: (省略可能) はブール値を受け入れます。trueまたはfalse、既定値はfalse各ワーカーの I/O コストを最小限に抑えるために、分散ミニバッチ読み取りをオンにすることをお勧めします。 CNTK テキスト形式リーダー、イメージ リーダー、または 複合データ リーダーを使用している場合は、distributedMBReading を true に設定する必要があります。
parallelizationStartEpoch: (省略可能) 整数値を受け取ります。既定値は 1 です。これは、エポック、並列トレーニングアルゴリズムが使用される開始点を指定します。その前に、すべてのワーカーが同じトレーニングを実行しますが、モデルの保存が許可されているワーカーは 1 つだけです。 このオプションは、並列トレーニングで何らかの "ウォーム スタート" ステージが必要な場合に便利です。
syncPerfStats: (省略可能) 整数値を受け取ります。既定値は 0 です。これは、パフォーマンス統計を出力する頻度を指定します。これらの統計には、同期期間中の通信や計算に費やされた時間が含まれます。これは、並列トレーニング アルゴリズムのボトルネックを理解するのに役立ちます。
0 は、統計情報が出力されないという意味です。その他の値は、統計を出力する頻度を指定します。たとえば、
syncPerfStats=55 回の同期ごとに統計情報が出力されることを意味します。各並列トレーニング アルゴリズムの詳細を指定するサブブロック。 サブブロックの名前は次のようになります
parallelizationMethod。 (必須)
Python では、さまざまな並列化方法に対して、より柔軟な使用方法を以下に示します。
4. CNTK を使用した並列トレーニングの実行
CNTK での並列化は MPI を使用して実装されます。
4.1 BrainScript を使用した並列トレーニングの実行
上記のいずれかの並列トレーニング BrainScript 構成を使用すると、次のコマンドを使用して並列 MPI ジョブを開始できます。
Linux を使用した同じコンピューターでの並列トレーニング:
mpiexec --npernode $num_workers $cntk configFile=$configWindows を使用した同じコンピューターでの並列トレーニング:
mpiexec -n %num_workers% %cntk% configFile=%config%Linux を使用した複数のコンピューティング ノード間での並列トレーニング:
手順 1: お気に入りのエディターを使用してホスト ファイル$hostfileを作成する
# Comments are allowed after pound sign name_of_node1 slots=4 # we want 4 workers on node1 name_of_node2 slots=2 # we want 2 workers on node2
ここで、name_of_node(n) は単にワーカー ノードの DNS 名または IP アドレスです。
Step 2: Execute your workload
```
mpiexec -hostfile $hostfile $cntk configFile=$config
```
Windows を使用した複数のコンピューティング ノード間での並列トレーニング:
mpiexec --hosts %num_nodes% %name_of_node1% %num_workers_on_node1% ... %cntk% configFile=%config%
ここで $cntk 、CNTK 実行可能ファイルのパスを参照する必要があります ($x Linux シェルの環境変数の置き換え方法であり、Windows シェルの場合と同等 %x% です)。
4.2 Python を使用した並列トレーニングの実行
Python を使用した CNTK v2 の分散トレーニングの例については、次を参照してください。
CNTK v2 Python スクリプト training.py を使用すると、次のコマンドを使用して並列 MPI ジョブを開始できます。
Linux を使用した同じコンピューターでの並列トレーニング:
mpiexec --npernode $num_workers python training.pyWindows を使用した同じコンピューターでの並列トレーニング:
mpiexec -n %num_workers% python training.pyLinux を使用した複数のコンピューティング ノード間での並列トレーニング:
手順 1: お気に入りのエディターを使用してホスト ファイル$hostfileを作成する
# Comments are allowed after pound sign name_of_node1 slots=4 # we want 4 workers on node1 name_of_node2 slots=2 # we want 2 workers on node2
ここで、name_of_node(n) は単にワーカー ノードの DNS 名または IP アドレスです。
Step 2: Execute your workload
```
mpiexec -hostfile $hostfile python training.py
```
Windows を使用した複数のコンピューティング ノード間での並列トレーニング:
mpiexec --hosts %num_nodes% %name_of_node1% %num_workers_on_node1% ... python training.py
1 ビット SGD を使用した 5 Data-Parallel トレーニング
CNTK は、1 ビット SGD 手法 [1] を実装します。 この手法では、各ミニバッチをワーカーに K 分散できます。 結果として得られる部分グラデーションは、各ミニバッチの後に交換され、集計されます。 "1 ビット" とは、各グラデーション値に対して交換されるデータの量を 1 ビットに減らすために Microsoft で開発された手法を指します。
5.1 "1 ビット SGD" アルゴリズム
各ミニバッチの後で部分的な勾配を直接交換するには、禁止的な通信帯域幅が必要です。 これに対処するために、1 ビット SGD は各グラデーション値を積極的に量子化します。...を値ごとに 1 ビット (!) に変換します。 実際には、これは大きなグラデーション値がクリップされるのに対し、小さな値は人為的に膨張することを意味します。 驚くべきことに、これは トリック が使用されている場合にのみ収束に害を与えません。
トリックは、各ミニバッチについて、アルゴリズムは量子化されたグラデーション(ワーカー間で交換される)と元のグラデーション値(交換されるはず)を比較することです。 2 つの差 ( 量子化誤差) が計算され、 残差として記憶されます。 次に、この残差が 次 のミニバッチに追加されます。
結果として、積極的な量子化にもかかわらず、各勾配値は最終的に完全な精度で交換されます。ちょうど遅れている。 実験では、このモデルがウォーム スタート (並列化なしでトレーニング データの小さなサブセットでトレーニングされたシード モデル) と組み合わされている限り、この手法は精度の損失がまったくまたは非常に小さいことを示している一方で、線形から遠すぎずに高速化を可能にしていることを示しています (小さすぎるサブバッチで計算すると GPU が非効率的になるという制限要因)。
最大限の効率を得るために、この技術を 自動ミニバッチスケーリングと組み合わせる必要があります。ここで、トレーナーはミニバッチサイズを増やそうとします。 今後のデータエポックの小さなサブセットを評価すると、トレーナーは収束に影響を与えない最大のミニバッチ サイズを選択します。 ここでは、CNTK がミニバッチ サイズに依存しない方法で学習率と運動量ハイパーパラメーターを指定すると便利です。
5.2 BrainScript での 1 ビット SGD の使用
1 ビット SGD 自体には、有効にする以外のパラメーターはなく、その後にエポックを開始する必要があります。 さらに、自動ミニバッチ スケーリングを有効にする必要があります。 これらは、SGD ブロックに次のパラメーターを追加することによって構成されます。
SGD = [
...
ParallelTrain = [
DataParallelSGD = [
gradientBits = 1
]
parallelizationStartEpoch = 2 # warm start: don't use 1-bit SGD for first epoch
]
AutoAdjust = [
autoAdjustMinibatch = true # enable automatic growing of minibatch size
minibatchSizeTuningFrequency = 3 # try to enlarge after this many epochs
]
]
Data-Parallel SGDは1ビット量子化なしでも使用できることに注意してください。 ただし、一般的なシナリオでは、特にフィードフォワード DNN のように各モデル パラメーターが 1 回だけ適用されるシナリオでは、通信帯域幅のニーズが高いため、これは効率的ではありません。
以下のセクション 2.2.3 は、音声タスクでの 1 ビット SGD の結果を、次に説明する Block-Momentum SGD メソッドと比較して示しています。 どちらの方法でも、ほぼ直線的な速度で精度が低下することも、ほとんど失われません。
5.3 Python での 1 ビット SGD の使用
Python でデータ並列 SGD (必要に応じて 1 ビット SGD) を使用するには、ユーザーは分散学習器を作成してトレーナーに渡す必要があります。
from cntk import distributed
...
learner = cntk.learner.momentum_sgd(...) # create local learner
distributed_after = epoch_size # number of samples to warm start with
distributed_learner = distributed.data_parallel_distributed_learner(
learner = learner,
num_quantization_bits = 1, # change to 32 for non-quantized gradient accumulation
distributed_after = distributed_after) # warm start: no parallelization is used for the first 'distributed_after' samples
...
minibatch_source = MinibatchSource(...)
...
trainer = Trainer(z, ce, pe, distributed_learner)
...
session = training_session(trainer=trainer, mb_source=minibatch_source, ...)
session.train()
...
distributed.Communicator.finalize() # must be called to finalize MPI in case of successful distributed training
distributed_learnerの作成時にnum_quantization_bitsを 32 に変更すると、SGD Data-Parallel非量子化が使用されます。 この場合、ウォーム スタートは必要ありません。
6 Block-Momentum SGD
ブロックモメンタム SGD は、"ブロックごとのモデルの更新とフィルター処理" (BMUF アルゴリズム、短い ブロック モメンタム [2]) の実装です。
6.1 Block-Momentum SGD アルゴリズム
次の図は、Block-Momentum アルゴリズムの手順をまとめたものです。

6.2 BrainScript での Block-Momentum SGD の構成
SGD Block-Momentum使用するには、次のオプションを持つブロック内にSGDサブブロックを指定BlockMomentumSGDする必要があります。
syncPeriod. これは、モデル同期をsyncPeriod実行する頻度を指定する inModelAveragingSGDと似ています。 既定値BlockMomentumSGDは 120,000 です。resetSGDMomentum. つまり、すべての同期ポイントの後に、ローカル SGD で使用される滑らかなグラデーションは 0 に設定されます。 この変数の既定値は true です。useNesterovMomentum. つまり、Nesterov スタイルのモメンタム更新がブロック レベルに適用されます。 詳細については、[2] を参照してください。 この変数の既定値は true です。
ブロックモメンタムとブロック学習率は、通常、使用されるワーカーの数に応じて自動的に設定されます。
block_momentum = 1.0 - 1.0/num_of_workers
block_learning_rate = 1.0
私たちの経験は、これらの設定は、多くの場合、私たちが実行した最大の実験である64 GPUまでの標準的なSGDアルゴリズムと同様の収束を生み出すことが示されています。 次のオプションを使用して、これらのパラメーターを手動で指定することもできます。
blockMomentumAsTimeConstantは、ブロック レベルのモデル更新におけるローパス フィルターの時間定数を指定します。 次のように計算されます。blockMomentumAsTimeConstant = -syncPeriod / log(block_momentum) # or inversely block_momentum = exp(-syncPeriod/blockMomentumAsTimeConstant)blockLearningRateは、ブロック学習率を指定します。
SGD 構成セクションの例Block-Momentum次に示します。
learningRatesPerSample=0.0005
# 0.0005 is the optimal learning rate for single-GPU training.
# Use it for BlockMomentumSGD as well
ParallelTrain = [
parallelizationMethod = BlockMomentumSGD
distributedMBReading = true
syncPerfStats = 5
BlockMomentumSGD=[
syncPeriod = 120000
resetSGDMomentum = true
useNesterovMomentum = true
]
]
BrainScript でのBlock-Momentum SGD の使用
1. 学習パラメータの再チューニング
ワーカーごとに同様のスループットを実現するには、ワーカーの数に比例してミニバッチ内のサンプルの数を増やす必要があります。 これは、フレーム モードのランダム化を
minibatchSize使用するかどうかに応じて調整するか、またはnbruttsineachrecurrentiter行うことで実現できます。学習率を調整する必要はありません (Model-Averaging SGD とは異なり、以下を参照してください)。
ウォーム スタート モデルBlock-Momentum SGD を使用することをお勧めします。 音声認識タスクでは、標準 SGD を使用して 24 時間 (860 万サンプル) から 120 時間 (4,320 万サンプル) のデータにトレーニングされたシード モデルから開始すると、妥当な収束が実現されます。
2. ASR 実験
ここでは、Block-Momentum SGD と Data-Parallel (1 ビット) SGD アルゴリズムを使用して、2600 時間の音声認識タスクで DNN と LSTM をトレーニングし、単語認識の精度と高速化の要因を比較しました。 結果 (*)を次の表と図に示します。
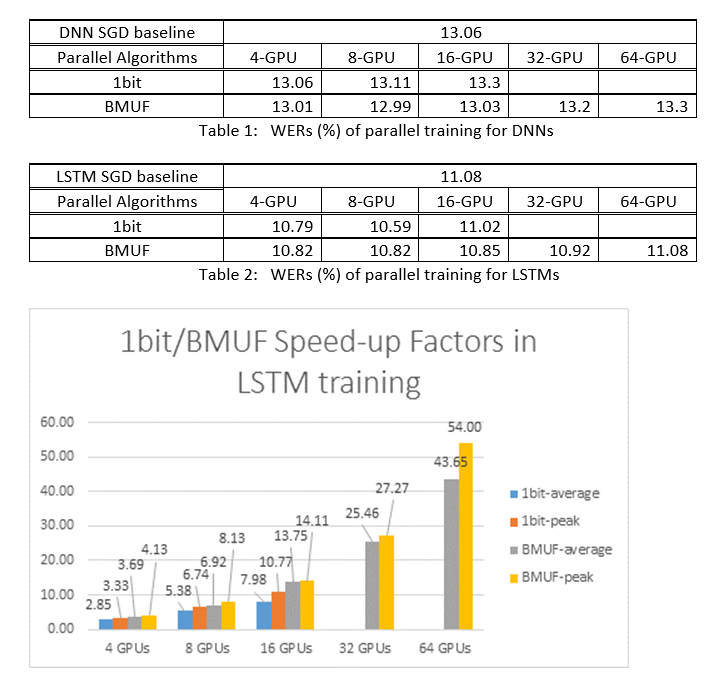
(*):ピーク高速化係数:1ビットSGDについて、1つのミニバッチで達成された最大高速化係数(SGDベースラインと比較して)によって測定される。ブロックモメンタムの場合、1つのブロックで達成された最大速度で測定されます。平均高速化係数: SGD ベースラインの経過時間を、観測された経過時間で割った値です。 これら 2 つのメトリックは、I/O の待機時間が、特にミニ バッチ レベルで同期が実行される場合に、平均速度アップ 係数の測定に大きく影響する可能性があるために導入されます。 同時に、最大高速化率は比較的堅牢です。
3. 注意事項
true に設定
resetSGDMomentumすることをお勧めします。それ以外の場合は、多くの場合、トレーニング条件の相違につながります。 各モデルの同期後に SGD モメンタムを 0 にリセットすると、基本的に最後のミニバッチからの寄与が遮断されます。 したがって、大きな SGD モメンタムを使用しないことをお勧めします。 たとえば、syncPeriod120,000 の場合、SGD に使用されるモメンタムが 0.99 の場合、精度が大幅に低下します。 SGD モメンタムを 0.9、0.5 に減らすか、完全に無効にしても、標準の SGD アルゴリズムで実現できるのと同様の精度が得られる。SGD の遅延をBlock-Momentumし、後続のブロック間で 1 つのブロックからモデルの更新を分散します。 そのため、トレーニングでモデルの同期が十分に頻繁に実行されるようにする必要があります。 クイック チェックでは、次の項目を使用
blockMomentumAsTimeConstantします。 一意のトレーニング サンプルの数は、N次の式を満たすことをお勧めします。N >= blockMomentumAsTimeConstant * num_of_workers ~= syncPeriod * num_of_workers^2
近似は、次の事実に由来します: (1) ブロックモメンタムは、多くの場合、次のように (1-1/num_of_workers)設定されます。(2) log(1-1/num_of_workers)~=-num_of_workers.
6.4 Python でのBlock-Momentumの使用
Python でBlock-Momentumを有効にするには、1 ビット SGD と同様に、ユーザーはブロックモメンタム分散学習者を作成してトレーナーに渡す必要があります。
from cntk import distributed
...
learner = cntk.learner.momentum_sgd(...) # create local learner
distributed_learner = cntk.distributed.block_momentum_distributed_learner(learner, block_size=block_size)
...
minibatch_source = MinibatchSource(...)
...
trainer = Trainer(z, ce, pe, distributed_learner)
...
session = training_session(trainer=trainer, mb_source=minibatch_source, ...)
session.train()
...
distributed.Communicator.finalize() # must be called to finalize MPI in case of successful distributed training
完全に機能する例については、 ConvNet の例を参照してください。
7 Model-Averaging SGD
モデル平均 SGD は、自然勾配を使用せずに [3,4] で詳しく説明されているモデル平均アルゴリズムの実装です。 ここでの考え方は、各ワーカーがデータのサブセットを処理できるようにすることですが、指定した期間が経過した後に各ワーカーのモデル パラメーターを平均化することです。
Model-Averaging SGD は一般に、1 ビット SGD と Block-Momentum SGD と比較して、より低速で最適に収束するため、推奨されなくなりました。
SGD Model-Averaging使用するには、次のオプションを使用して、ブロック内にサブブロックの名前 ModelAveragingSGD を SGD 付ける必要があります。
syncPeriodは、モデルの平均化が実行される前に各ワーカーが処理する必要があるサンプルの数を指定します。 既定値は 40,000 です。
BrainScript でのModel-Averaging SGD の使用
Model-Averaging SGD を最大限に効果的かつ効率的にするために、ユーザーはいくつかのハイパーパラメーターを調整する必要があります。
minibatchSizeまたはnbruttsineachrecurrentiter。 ワーカーがModel-Averaging SGD 構成に参加している場合n、現在の分散読み取り実装では、ミニバッチの -th が各ワーカーに読み込まれる1/nとします。 したがって、各ワーカーが標準の SGD と同じスループットを生成するようにするには、ミニバッチ サイズnを拡大する必要があります。 フレーム モードのランダム化を使用してトレーニングされたモデルの場合、これは時間単位でn拡大minibatchSizeすることで実現できます。モデルの場合は、RNN などのシーケンス モードのランダム化を使用してトレーニングします。一部のリーダーでは、代わりに増加nbruttsineachrecurrentiternする必要があります。learningRatesPerSample. 私たちの経験は、標準SGDと同様の収束を得るには、時間ごとにn増加learningRatesPerSampleする必要があることを示しています。 説明は [2] にあります。 学習率が上がるので、トレーニングが分岐しないように注意する必要があります。これは実際にはSGDModel-Averaging主な注意点です。 トレーニング条件の増加がAutoAdjust観察された場合は、この設定を使用して前の最適なモデルを再読み込みできます。ウォーム スタート。 通常、標準の SGD アルゴリズム (並列化なし) によってトレーニングされたシード モデルから開始した場合、Model-Averaging SGD の方が収束が良いことがわかります。 音声認識タスクでは、標準 SGD を使用して 24 時間 (860 万サンプル) から 120 時間 (4,320 万サンプル) のデータにトレーニングされたシード モデルから開始すると、妥当な収束が実現されます。
構成セクションの例を次に ModelAveragingSGD 示します。
learningRatesPerSample = 0.002
# increase the learning rate by 4 times for 4-GPU training.
# learningRatesPerSample = 0.0005
# 0.0005 is the optimal learning rate for single-GPU training.
ParallelTrain = [
parallelizationMethod = ModelAveragingSGD
distributedMBReading = true
syncPerfStats = 20
ModelAveragingSGD = [
syncPeriod=40000
]
]
7.2 Python でのModel-Averaging SGD の使用
この記事は作成中です。
8 Data-Parallel パラメーター サーバーを使用したトレーニング
パラメーター サーバーは、分散機械学習で広く使用されているフレームワークです [5][6][7]。 最も重要な利点は、多くのワーカーとの非同期並列トレーニングです。 分散モデル ストアとしてパラメーター サーバーが導入されます。 パラメーター サーバー フレームワークは、AllReduce プリミティブを直接利用してワーカー間でパラメーター更新を同期する代わりに、"追加" や "Get" などのインターフェイスをユーザーに提供し、ローカル ワーカーがパラメーター サーバーからグローバル パラメーターを更新および取得できるようにします。 このように、ローカルワーカーはトレーニングプロセス中に互いを待つ必要はありません。これにより、特にワーカー数が多い場合に多くの時間を節約できます。
さらに、パラメーター サーバーはモデル パラメーターを格納する分散フレームワークであるため、ワーカーはミニバッチ トレーニング プロセス中にのみ必要なパラメーターを取得できるため、分散トレーニング方法の設計に非常に優れた柔軟性がもたらされ、スパース モデルの更新を使用してトレーニングを行う際の効率も向上します。 このリリースでは、最初に非同期並列トレーニングに焦点を当て、後でパラメーター サーバー フレームワークを活用してスパース更新による効率的なモデル トレーニングを行う方法について詳しく説明します。
8.1 Data-Parallel ASGD の使用
- 非同期 SGD (ASGD として abbr. ) にパラメーター サーバーを使用するには、 Multiverso がサポートされている CNTK を構築する必要があります。Multiverso は、Microsoft Research Asia チームによって開発された分散機械学習タスクの一般的なパラメーター サーバー フレームワークです。
Clone Code: 次を使用して、CNTK のルート フォルダーの下にコードを複製してください。
git submodule update --init Source/Multiverso
Linux: 構成プロセスでビルド--asgd=yesしてください。Windows: システム環境に追加CNTK_ENABLE_ASGDし、値をtrue
- ウォーム スタート。 場合によっては、シード モデル (標準 SGD アルゴリズムによってトレーニング) から非同期モデル トレーニングを開始することをお勧めします。 ある意味では、非同期 SGD では、ワーカー間の非同期性からの更新が遅れているため、トレーニングのノイズが増えます。 一部のモデルは、最初にこのようなノイズに非常に敏感であり、モデルのトレーニングが分散する可能性があります。 このような状況では、 ウォーム スタート が必要です。
8.2 BrainScript での Data-Parallel ASGD の構成
CNTK Data-Parallel ASGD を使用するには、次のオプションを使用して、SGD ブロックにサブブロック DataParallelASGD が必要です。
-
syncPeriodPerWorkers. 各ワーカーがパラメーター サーバーと通信する前に処理する必要があるサンプルの数を指定します。 既定値は 256 です。 ミニバッチのサイズとしてお勧めします。 同期が頻繁に行われると、通信コストが大幅に高くなるのは明らかです。 このテストでは、ほとんどの場合、値を 1 に設定する必要はありません。
-
usePipeline. モデル取得とローカル計算のパイプラインを有効にするかどうかを指定します。 パイプラインをオンにすると、通信コストの一部または全部が非表示になるため、トレーニングの全体的なスループットが大幅に向上します。 ただし、パイプラインを追加することでより多くの遅延が発生するため、収束率が低下する場合があります。 全体的に見ると、ほとんどの場合、パイプラインを使用してクロック時間が節約されます。
-
AdjustLearningRateAtBeginning. 最近発表された論文[5]によると、トレーニングASGDは安定性が低く、トレーニング損失の時折爆発を避けるためにはるかに小さな学習率を使用する必要があるため、学習プロセスは効率的ではなくなります。 ただし、すべてのタスクで低い学習率を使用する必要はないことがわかりました。 また、最初に機密性の高いタスクに対しては、トレーニングを小さな学習率で開始し、トレーニング プロセスの最初の段階で、通常の SGD で使用される初期学習率に達するまで徐々に拡大します。 このようにして、最終的な精度はSGDとASGDの速度と一致します。 そのため、ASGD ユーザーがこのトリックを活用するために、このオプションを提供します。 これは DataParallelASGD のサブブロックであり、 adjustCoefficient と adjustNBMiniBatch という 2 つのパラメーターがあります。 ロジックは、学習率が SGD 初期学習率の adjustCoefficient から始まり、adjustNBMiniBatch ミニバッチごとに SGD 初期学習率の adjustCoefficient によって増加することです。
構成セクションの例を次に DataParallelASGD 示します。
learningRatesPerSample = 0.0005
ParallelTrain = [
parallelizationMethod = DataParallelASGD
distributedMBReading = true
syncPerfStats = 20
DataParallelASGD = [
syncPeriodPerWorker=256
usePipeline = true
AdjustLearningRateAtBeginning = [
adjustCoefficient = 0.2
adjustNBMiniBatch = 1024
# Learning rate will be adjusted to original one after ((1 / adjustCoefficient) * adjustNBMiniBatch) samples
# which is 5120 in this case
]
]
]
8.3 Python での Data-Parallel ASGD の構成
この記事は作成中です。
8.4 実験
次の図は、CIFAR-10 データセットで ASGD をテストする実験を示しています。 この実験で使用されるモデルは、20 層の ResNet です。 非同期アルゴリズムを使用すると、すべてのワーカー ノードを待機するときのコストが削減されます。 この場合、ASGD は MA や SSGD などの同期アルゴリズムよりも明らかに高速です。 *実験では、すべての並列モードは、反復ごとにパラメーターを同期します (ミニバッチ更新)。 SSGD では、32 ビットのパラメーター更新を使用しました。 非同期アルゴリズムは、特に作業ノード数が 16 に上がる場合に、サンプル処理速度によって測定されるトレーニング スループットの点で大きな利点を得ます。
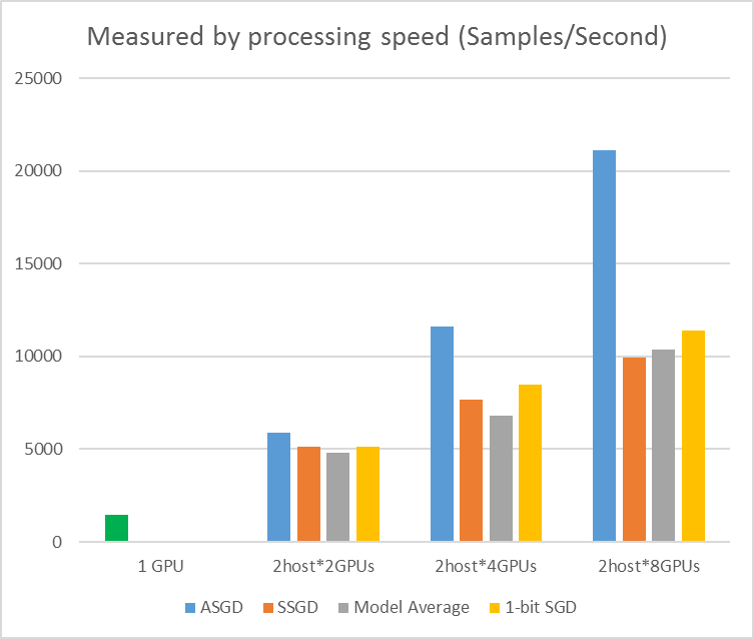 図 2.4 さまざまなトレーニング方法の高速化
図 2.4 さまざまなトレーニング方法の高速化
リファレンス
[1] F. Seide, Hao Fu, Jasha Droppo, Gang Li, Dong Yu, "1 ビット確率的勾配降下と音声 DNN のデータ並列分散トレーニングへの応用", Interspeech, 2014.
[2] 陳敬と Q. Huo, "ブロック内並列最適化とブロックごとのモデル更新フィルター処理による増分ブロック トレーニングによるディープ ラーニング マシンのスケーラブルなトレーニング", ICASSP の議事録, 2016.
[3] M. Zinkevich, M. Weimer, L. Li, A. J. Smola, "並列確率勾配降下" in NIPS の進歩の議事録, 2010, pp. 2595-2603.
[4] D. Povey, X. Zhang, S.Khdanpur, "自然勾配とパラメーター平均を持つ DNN の並列トレーニング", 学習表現に関する国際会議の議事録, 2014.
[5]Chen J、Monga R、Bengio S ら。分散同期 SGD の再検討。 ICLR、2016。
[6]ディーン・ジェフリー、グレッグ・コラード、ラジャット・モンガ、カイ・チェン、マチュー・デヴィン、マーク・マオ、Andrew Senior ら。大規模な分散ディープ ネットワーク。 ニューラル情報処理システムの進歩, pp. 1223-1231. 2012.
[7]Li Mu, Li Zhou, Zichao Yang, Aaron Li, Fei Xia, David G. Andersen, and Alexander Smola. "分散機械学習用のパラメーター サーバー"ビッグラーニングNIPSワークショップ,vol. 6, p. 2. 説明されています。