Azure Time Series Insights Gen1 の待機時間を短縮するために、スロットリングを監視し、軽減する。
手記
Time Series Insights サービスは、2024 年 7 月 7 日に廃止されます。 既存の環境をできるだけ早く別のソリューションに移行することを検討してください。 非推奨と移行の詳細については、
注意
これは Gen1 の記事です。
受信データの量が環境の構成を超えると、Azure Time Series Insights で待機時間や調整が発生する可能性があります。
分析するデータの量に合わせて環境を適切に構成することで、待機時間と調整を回避できます。
次の状況のとき、遅延と制限が発生する可能性が最も高くなります。
- 割り当てられたイングレス レートを超える可能性がある古いデータを含むイベント ソースを追加します (Azure Time Series Insights は追いつく必要があります)。
- 環境にイベント ソースを追加すると、追加のイベント (環境の容量を超える可能性があります) が急増します。
- 大量の履歴イベントをイベント ソースにプッシュすると、遅延が発生します (Azure Time Series Insights は追いつく必要があります)。
- 参照データをテレメトリと結合すると、イベント サイズが大きくなります。 許容される最大パケット サイズは 32 KB です。32 KB を超えるデータ パケットは切り捨てられます。
ビデオ
Azure Time Series Insights のデータイングレス動作とその計画方法について説明します。
アラートを使用して待機時間と調整を監視する
アラートは、環境内で発生する待機時間の問題を診断して軽減するのに役立ちます。
Azure portal で、Azure Time Series Insights 環境を選択します。 次に、アラートを選択します。
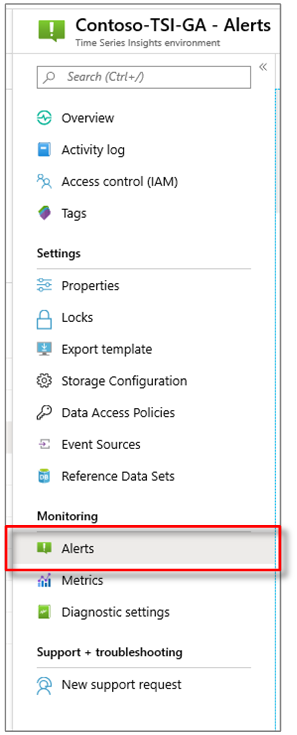
[+ 新しいアラート ルール] を選択します。 ルールを作成する パネルが次に表示されます。 [条件]の下で を選択し、[ を追加]します。
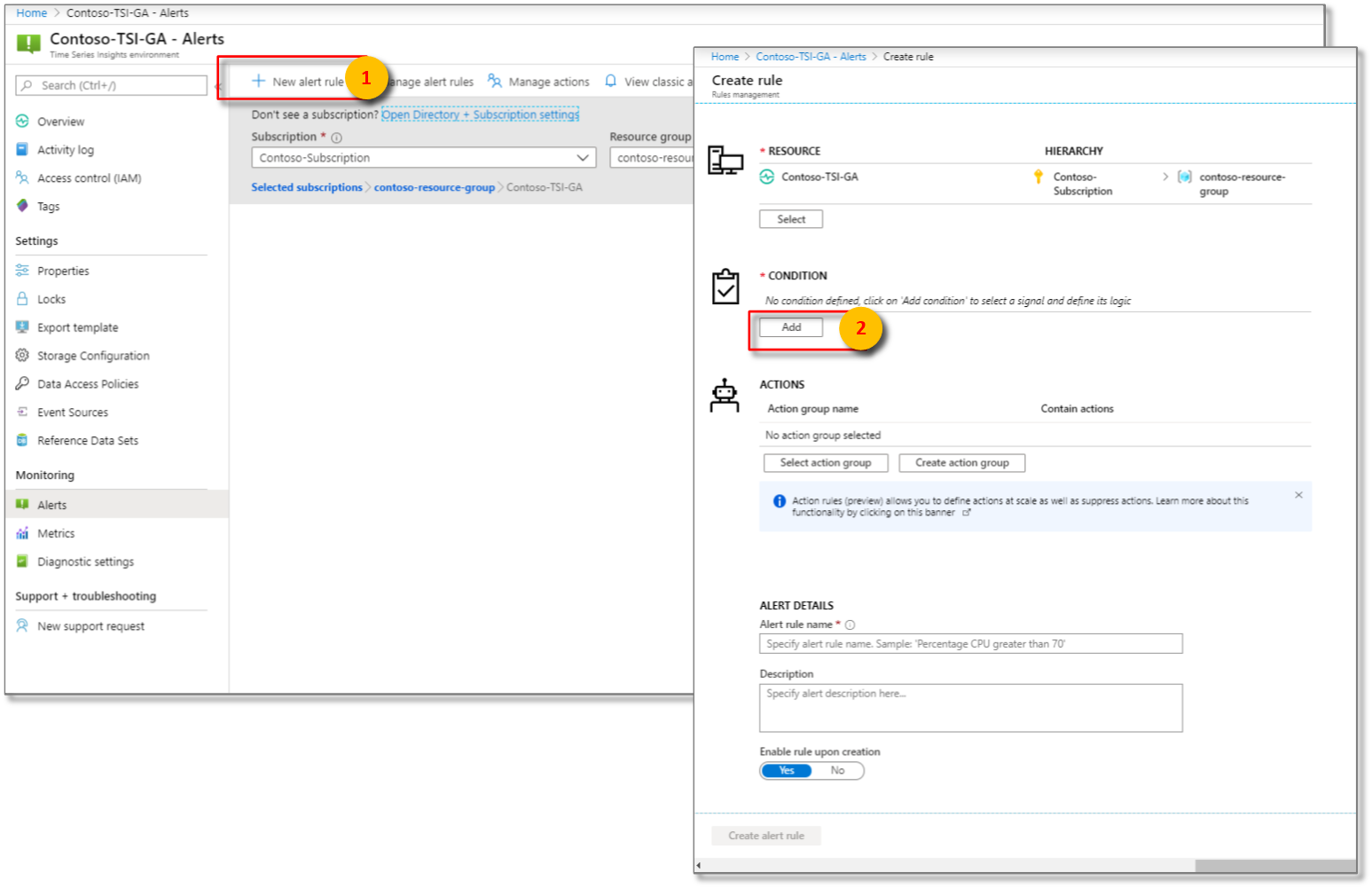
次に、シグナル ロジックの正確な条件を構成します。
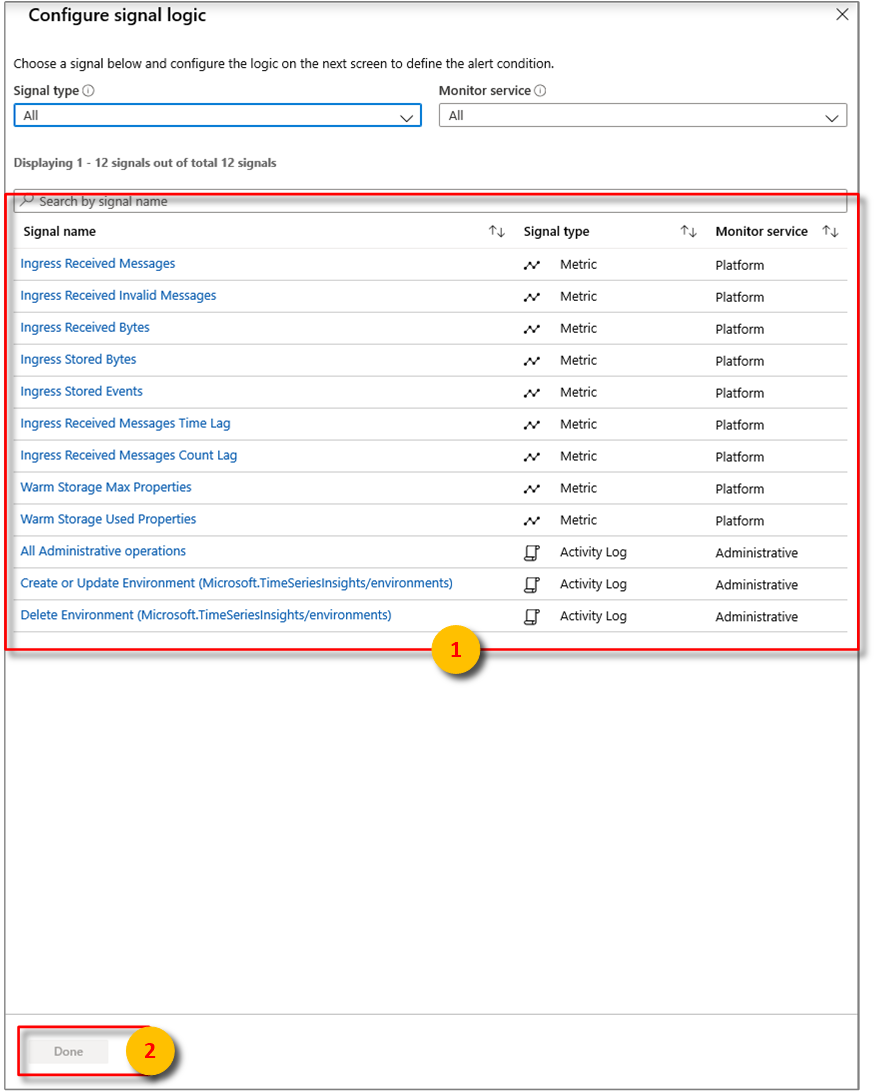 を構成する
を構成するそこから、次のいくつかの条件を使用してアラートを構成できます。
メトリック 説明 受信バイト数 イベント ソースから読み取られた未加工のバイト数。 生カウントには通常、プロパティの名前と値が含まれます。 無効なメッセージの受信を として記録しました すべての Azure Event Hubs または Azure IoT Hub イベント ソースから読み取られた無効なメッセージの数。 受信メッセージ を に入れる すべての Event Hubs または IoT Hubs イベント ソースから読み取られたメッセージの数。 イングレス の格納バイト数 格納され、クエリに使用できるイベントの合計サイズ。 サイズは、プロパティ値でのみ計算されます。 イングレス の格納されたイベント 格納され、クエリに使用できるフラット化されたイベントの数。 受信メッセージのタイムラグ イベント ソースでメッセージがエンキューされる時間とイングレスで処理される時間の差 (秒)。 受信メッセージ数の遅延 イベント ソース パーティション内の最後にエンキューされたメッセージのシーケンス番号と、イングレスで処理されるメッセージのシーケンス番号の違い。 選択します 。完了
目的のシグナル ロジックを構成したら、選択したアラート ルールを視覚的に確認します。
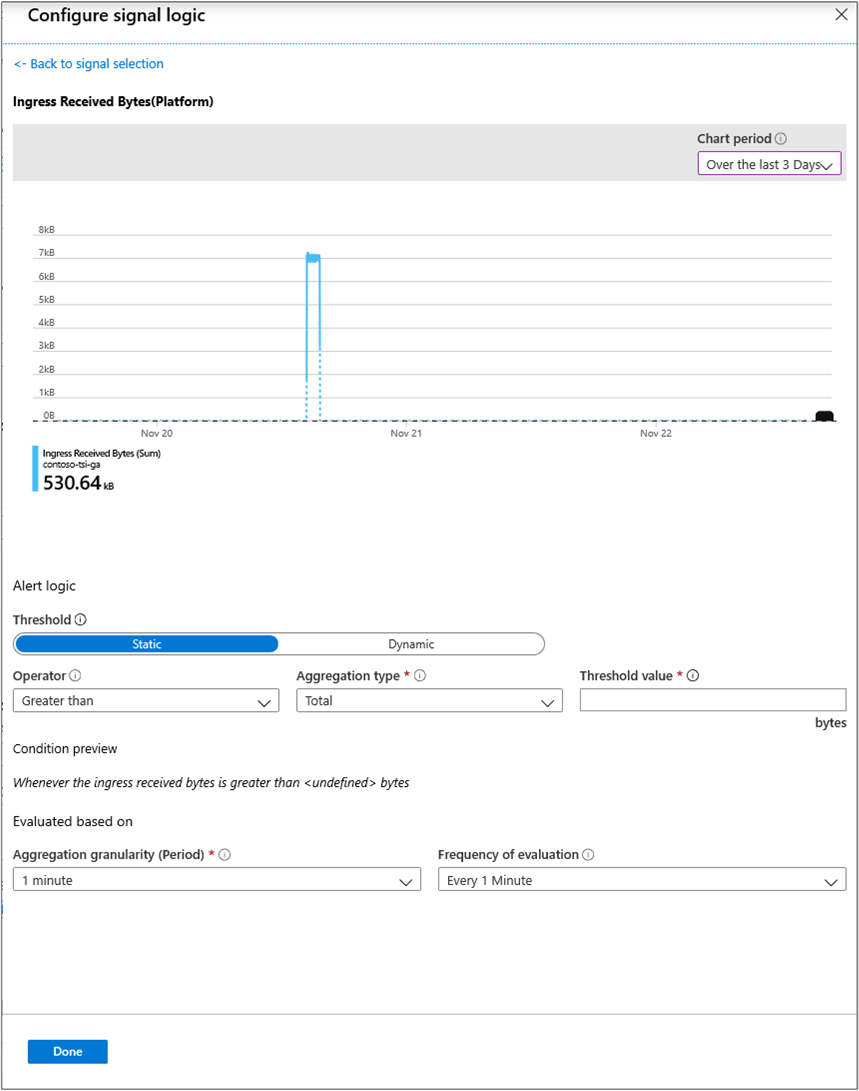




スロットリングとイングレス管理
スロットリングされている場合、Ingress 受信メッセージ遅延時間 の値が登録され、メッセージがイベントソースに到達した実時間からどれだけ遅延しているか (インデックス作成時間約30~60秒を除く) が、Azure Time Series Insights 環境に表示されます。
イングレス受信メッセージ数ラグ も値を持つ必要があります。それによって、どれだけメッセージが遅れているかを判定できます。 キャッチアップする最も簡単な方法は、環境の容量を、その違いを克服できるサイズに増やすことです。
たとえば、S1 環境で 5,000,000 メッセージのラグが示されている場合は、環境のサイズを 1 日あたり 6 ユニットに増やして追い付く可能性があります。 より速く追いつくためにさらに増やすことができる。 キャッチアップ期間は、環境を最初にプロビジョニングする場合、特にイベントが既に含まれているイベント ソースに接続するとき、または大量の履歴データを一括アップロードする場合に一般的に発生します。
もう 1 つの手法は、イングレス ストアド イベント アラート >= 2 時間の合計環境容量をわずかに下回るしきい値を設定することです。 このアラートは、容量が常に最大かどうかを把握するのに役立ち、それは待機時間が発生する可能性が高いことを示します。
たとえば、3 つの S1 ユニット (または 1 分間に 2100 イベントのイングレス容量) がプロビジョニングされている場合は、>= 1900 イベントの イングレス 格納イベント アラートを 2 時間設定できます。 このしきい値を常に超えているため、アラートをトリガーする場合は、プロビジョニングが不足している可能性があります。
調整されていると思われる場合は、受信メッセージ をイベント ソースのエグレス メッセージと比較できます。 Event Hub へのイングレスが の受信メッセージよりも多い場合は、Azure Time Series Insights が制限されている可能性があります。
パフォーマンスの向上
スロットリングや遅延を減らすためには、環境の容量を増やすことが最も効果的な方法です。
分析するデータの量に合わせて環境を適切に構成することで、待機時間と調整を回避できます。 環境に容量を追加する方法の詳細については、「環境のスケーリング」を参照してください。