特徴ハッシュ
重要
Machine Learning Studio (クラシック) のサポートは、2024 年 8 月 31 日に終了します。 その日までに、Azure Machine Learning に切り替えすることをお勧めします。
2021 年 12 月 1 日以降、新しい Machine Learning Studio (クラシック) リソースは作成できません。 2024 年 8 月 31 日まで、既存の Machine Learning Studio (クラシック) リソースを引き続き使用できます。
- ML Studio (クラシック) から Azure Machine Learning への機械学習プロジェクトの移動に関する情報を参照してください。
- Azure Machine Learning についての詳細を参照してください。
ML Studio (クラシック) のドキュメントは廃止予定であり、今後更新されない可能性があります。
Vowpal Wabbit ライブラリを使用してテキスト データをエンコードされた数値的な特徴に変換します
カテゴリ: Text Analytics
注意
適用対象: Machine Learning Studio (クラシック) のみ
類似のドラッグ アンド ドロップ モジュールは Azure Machine Learning デザイナーで使用できます。
モジュールの概要
この記事では、Machine Learning Studio (クラシック) で Feature Hashing モジュールを使用して、英語のテキストのストリームを整数として表される一連の特徴に変換する方法について説明します。 その後、このハッシュされた機能セットを機械学習アルゴリズムに渡して、テキスト分析モデルをトレーニングできます。
このモジュールで提供される機能ハッシュ機能は、Vowpal Wabbit フレームワークに基づいています。 詳細については、「 Vowpal Wabbit 7-4 モデルのトレーニング 」または 「Vowpal Wabbit 7-10 モデルのトレーニング」を参照してください。
機能ハッシュの詳細
特徴ハッシュは、一意のトークンを整数に変換することによって機能します。 これは、入力として提供された正確な文字列に対して作用し、言語分析や前処理は行いません。
たとえば、後にセンチメント スコアが付いた、次のような一連の単純な文を取り上げます。 このテキストを使用してモデルを作成するとします。
| ユーザー テキスト | センチメント |
|---|---|
| I loved this book | 3 |
| I hated this book | 1 |
| This book was great | 3 |
| I love books | 2 |
内部的には、 機能ハッシュ モジュールによって n-gram のディクショナリが作成されます。 たとえば、このデータセットの bigram の一覧表は次のようになります。
| 用語 (bigram) | 頻度 |
|---|---|
| This book | 3 |
| I loved | 1 |
| I hated | 1 |
| I loved | 1 |
N-gram のサイズは、N-gram プロパティを使用して制御できます。 bigram を選択した場合、unigram も計算されます。 したがって、辞書には次のような単一の用語も含まれます。
| 用語 (unigram) | 頻度 |
|---|---|
| book | 3 |
| I | 3 |
| books | 1 |
| was | 1 |
ディクショナリが構築されると、 フィーチャー ハッシュ モジュールは辞書の用語をハッシュ値に変換し、各ケースで機能が使用されたかどうかを計算します。 テキスト データの各行に対して、モジュールは、ハッシュした特徴ごとに 1 列ずつ、一連の列を出力します。
たとえば、ハッシュ後、特徴列は次のようになります。
| Rating | ハッシュする特徴 1 | ハッシュする特徴 2 | ハッシュする特徴 3 |
|---|---|---|---|
| 4 | 1 | 1 | 0 |
| 5 | 0 | 0 | 0 |
- 列の値が 0 の場合、行にはハッシュ機能が含まれていませんでした。
- 値が 1 の場合、行にはその特徴が含まれていました。
特徴ハッシュを使用する利点は、可変長のテキスト ドキュメントを等しい長さの数値特徴ベクトルとして表し、次元の削減を実現できることです。 一方、テキスト列をそのままトレーニングに使用しようとすると、カテゴリ特徴列として扱われ、多数の異なる値が含まれます。
数値として出力することで、分類、クラスタリング、情報の取得など、データに関して多くの異なる機械学習のメソッドを使用できます。 参照操作では、文字列の比較ではなく整数のハッシュを使用できるため、特徴の重みの取得もはるかに高速になります。
機能ハッシュを構成する方法
Studio (クラシック) の実験に フィーチャー ハッシュ モジュールを追加します。
分析するテキストが含まれているデータセットを接続します。
ヒント
特徴ハッシュではステミングや切り捨てなどの字句操作は行われないため、特徴ハッシュを適用する前にテキストの前処理を実行すると、より良い結果が得られる場合があります。 提案については、 ベスト プラクティス と テクニカル ノート のセクションを参照してください。
[ターゲット列] で、ハッシュフィーチャに変換するテキスト列を選択します。
列は文字列データ型である必要があり、 フィーチャー 列としてマークする必要があります。
入力として使用する複数のテキスト列を選択すると、特徴の次元に大きな影響を与える可能性があります。 たとえば、1 つのテキスト列に 10 ビット ハッシュを使用する場合、出力には 1024 列が含まれます。 2 つのテキスト列に 10 ビット ハッシュを使用する場合、出力には 2048 列が含まれます。
注意
既定では、Studio (クラシック) ではほとんどのテキスト列が機能としてマークされるため、すべてのテキスト列を選択すると、実際にはフリー テキストではない列を含む列が多すぎる可能性があります。 他のテキスト列がハッシュされないようにするには、[メタデータの編集] の [クリア] 機能オプションを使用します。
[Hashing bitsize]\(ハッシュのビットサイズ\) を使用して、ハッシュ表を作成するときに使用するビット数を指定します。
既定のビット サイズは 10 です。 多くの問題では、この値は十分ですが、データに十分かどうかは、トレーニング テキストの n-grams ボキャブラリのサイズによって異なります。 ボキャブラリが大きい場合は、衝突を避けるためにより多くのスペースが必要になる場合があります。
このパラメーターには別のビット数を使用し、機械学習ソリューションのパフォーマンスを評価することをお勧めします。
[N-grams]\(N-gram\) には、トレーニング辞書に追加する N-gram の最大長を定義する数値を入力します。 N-gram は、一意の単位として扱われる、n 個の単語のシーケンスです。
N-grams = 1: ユニグラム、または単一の単語。
N-grams = 2: Bigrams、または 2 ワード シーケンスとユニグラム。
N-grams = 3: トリグラム、または 3 ワード シーケンス、およびビグラムとユニグラム。
実験を実行します。
結果
処理が完了すると、モジュールによって変換後のデータセットが出力されます。元のテキスト列が複数の列に変換され、各列はテキスト内の特徴を表します。 ディクショナリの大きさによっては、結果のデータセットが非常に大きくなる場合があります。
| 列名 1 | 列の種類 2 |
|---|---|
| ユーザー テキスト | 元のデータ列 |
| センチメント | 元のデータ列 |
| ユーザー テキスト - ハッシュする特徴 1 | ハッシュされた特徴列 |
| ユーザー テキスト - ハッシュする特徴 2 | ハッシュされた特徴列 |
| ユーザー テキスト - ハッシュする特徴 n | ハッシュされた特徴列 |
| ユーザー テキスト - ハッシュする特徴 1024 | ハッシュされた特徴列 |
変換されたデータセットを作成したら、モデルの トレーニング モジュールへの入力として、 2 クラス サポート ベクター マシンなどの優れた分類モデルと共に使用できます。
ベスト プラクティス
テキスト データのモデリング中に使用できるベスト プラクティスの一部を、実験を表す次の図で示します。
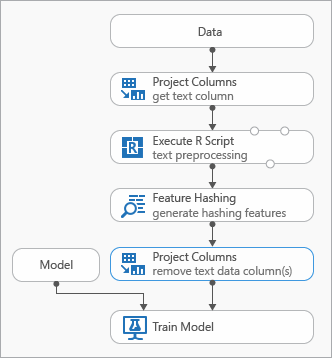
入力テキストを事前処理するため、特徴ハッシュを使用する前に、R スクリプトの実行モジュールを追加する必要がある場合があります。 R スクリプトでは、カスタム語彙またはカスタム変換を柔軟に使用することもできます。
出力データ セットからテキスト列を削除するには、機能ハッシュ モジュールの後にデータセットの列の選択モジュールを追加する必要があります。 ハッシュ機能が生成された後は、テキスト列は必要ありません。
または、[ メタデータの編集] モジュールを使用して、テキスト列から機能属性をクリアすることもできます。
また、結果を簡略化し、精度を向上させるために、次のテキスト前処理オプションを使用することを検討してください。
- 単語区切り
- 単語の削除を停止する
- case の正規化
- 句読点と特殊文字の削除
- ステミング。
個々のソリューションに適用される最適な前処理方法のセットは、ドメイン、ボキャブラリ、およびビジネス ニーズによって異なります。 データを試して、最も効果的なカスタム テキスト処理方法を確認することをお勧めします。
例
テキスト分析に機能ハッシュを使用する方法の例については、 Azure AI ギャラリーを参照してください。
ニュースの分類: 機能ハッシュを使用して、記事を定義済みのカテゴリの一覧に分類します。
類似企業: ウィキペディアの記事のテキストを使用して企業を分類します。
テキスト分類: この 5 部構成のサンプルでは、Twitter メッセージのテキストを使用してセンチメント分析を実行します。
テクニカル ノート
このセクションには、実装の詳細、ヒント、よく寄せられる質問への回答が含まれています。
ヒント
特徴ハッシュの使用に加えて、他のメソッドを使用してテキストから特徴を抽出することもできます。 次に例を示します。
- [テキストの前処理] モジュールを使用して、スペル ミスなどのアーティファクトを削除したり、ハッシュの準備を簡略化したりします。
- 自然言語処理を使用して フレーズを抽出するには、キー フレーズ の抽出を使用します。
- 名前付きエンティティ認識を使用して、重要なエンティティを識別します。
Machine Learning Studio (クラシック) には、特徴の抽出に機能ハッシュ モジュールを使用する手順を示すテキスト分類テンプレートが用意されています。
実装の詳細
Feature Hashing モジュールでは、Vowpal Wabbit と呼ばれる高速な機械学習フレームワークを使用し、murmurhash3 と呼ばれる一般的なオープンソース ハッシュ関数を使用して特徴単語をインメモリ インデックスにハッシュします。 このハッシュ関数は、テキスト入力を整数にマッピングする非暗号化ハッシュ アルゴリズムを使用し、キーをランダムに正しく割り当てるため、一般的に使用されています。 暗号化ハッシュ関数とは異なり、敵対者が簡単に逆引きできるため、暗号化目的には適さない可能性があります。
ハッシュの目的は、可変長のテキスト文書を等しい長さの数値特徴ベクトルに変換し、次元削減をサポートして特徴の重みをすばやく参照できるようにすることです。
各ハッシュ機能は、ビット数 (k で表される) とパラメーターとして指定された n-gram の数に応じて、1 つ以上の n-gram テキスト特徴 (ユニグラムまたは個々の単語、バイグラム、トリグラムなど) を表します。 機能名は、murmurhash v3 (32 ビットのみ) アルゴリズムを使用してマシン アーキテクチャの符号なし単語に投影され、その後 (2^k)-1 で AND-ed されます。 つまり、ハッシュ値は最初の k 個の下位ビットに投影され、残りのビットはゼロになります。指定したビット数が 14 の場合、ハッシュ テーブルは 2つの 14-1 (または 16,383) エントリを保持できます。
多くの問題では、既定のハッシュ テーブル (bitsize = 10) が十分ではありません。ただし、トレーニング テキストの n-grams ボキャブラリのサイズによっては、競合を回避するためにより多くの領域が必要になる場合があります。 Hashing bitsize パラメーターに異なるビット数を使用し、機械学習ソリューションのパフォーマンスを評価することをお勧めします。
想定される入力
| 名前 | Type | 説明 |
|---|---|---|
| データセット | データ テーブル | 入力データセット |
モジュールのパラメーター
| 名前 | Range | Type | Default | 説明 |
|---|---|---|---|---|
| 対象列 | Any | ColumnSelection | StringFeature | ハッシュを適用する列を選択します。 |
| ハッシュ ビットサイズ | [1;31] | Integer | 10 | 選択した列をハッシュ化する場合に使用するビット数を入力します |
| N-grams (N-gram) | [0;10] | Integer | 2 | ハッシュ時に生成される N グラムの数を指定します。 既定では、unigram および bigram の両方が抽出されます |
出力
| 名前 | Type | 説明 |
|---|---|---|
| 変換されたデータセット | データ テーブル | ハッシュされた列を含む出力データセット |
例外
| 例外 | 説明 |
|---|---|
| エラー 0001 | データ セットで指定した列のうち 1 つまたは複数が見つからない場合、例外が発生します。 |
| エラー 0003 | 1 つまたは複数の入力が null または空の場合、例外が発生します。 |
| エラー 0004 | パラメーターが特定の値以下の場合、例外が発生します。 |
| エラー 0017 | 指定した 1 つ以上の列の型が現在のモジュールでサポートされていない場合に、例外が発生します。 |
Studio (クラシック) モジュールに固有のエラーの一覧については、「Machine Learningエラー コード」を参照してください。
API の例外の一覧については、「REST API エラー コードMachine Learning」を参照してください。