チュートリアル 2: 信用リスク モデルをトレーニングする - Machine Learning Studio (クラシック)
適用対象:  Machine Learning Studio (クラシック)
Machine Learning Studio (クラシック)  Azure Machine Learning
Azure Machine Learning
重要
Machine Learning Studio (クラシック) のサポートは、2024 年 8 月 31 日に終了します。 その日までに、Azure Machine Learning に切り替えすることをお勧めします。
2021 年 12 月 1 日以降、新しい Machine Learning Studio (クラシック) リソースは作成できません。 2024 年 8 月 31 日まで、既存の Machine Learning Studio (クラシック) リソースを引き続き使用できます。
- ML Studio (クラシック) から Azure Machine Learning への機械学習プロジェクトの移動に関する情報を参照してください。
- Azure Machine Learning についての詳細を参照してください
ML Studio (クラシック) のドキュメントは廃止予定であり、今後更新されない可能性があります。
このチュートリアルでは、予測分析ソリューションを開発するプロセスについて詳しく説明します。 Machine Learning Studio (クラシック) で単純なモデルを開発します。 その後、そのモデルを Machine Learning Web サービスとしてデプロイします。 このデプロイ モデルは、新しいデータを使用して予測を行うことができます。 このチュートリアルは、3 部構成のチュートリアル シリーズのパート 2 です。
クレジットの申請書に記入する情報に基づいて個人のクレジット リスクを予測する必要があるとします。
信用リスクの評価は複雑な問題ですが、このチュートリアルでは、それを少し簡略化してみます。 Machine Learning Studio (クラシック) を使用して予測分析ソリューションを作成する方法の例として使用してください。 このソリューションでは、Machine Learning Studio (クラシック) と Machine Learning Web サービスを使用します。
この 3 部構成のチュートリアルでは、まず、公表されている信用リスク データを使用します。 その後、予測モデルを開発してトレーニングします。 最後にそのモデルを Web サービスとしてデプロイします。
チュートリアルのパート 1 では、Machine Learning Studio (クラシック) ワークスペースを作成し、データをアップロードし、実験を作成しました。
チュートリアルのこのパートでは、次のことを行います。
- 複数のモデルをトレーニングする
- モデルにスコアを付け、評価する
チュートリアルのパート 3 では、モデルを Web サービスとしてデプロイします。
前提条件
このチュートリアルのパート 1 を完了しました。
複数のモデルをトレーニングする
Machine Learning Studio (クラシック) を使用して機械学習モデルを作成することの利点の 1 つは、1 つの実験で複数種類のモデルを同時に試してそれらの結果を比較できることです。 このような実験は、問題の最善の解決策を見つけるのに役立ちます。
このチュートリアルで開発している実験では、2 種類の異なるモデルを作成し、それらのスコア結果を比較することで、最終的な実験で使用するアルゴリズムを決定します。
選択できるモデルは数多くあります。 これらのモデルを表示するには、モジュール パレットの [機械学習] ノードを展開して、[モデルの初期化] とその下にあるノードを展開します。 実験の目的に合わせて、2 クラス サポート ベクター マシン (SVM) モジュールと 2 クラス ブースト デシジョン ツリー モジュールを選択します。
2 クラス ブースト デシジョン ツリー モジュールと 2 クラス サポート ベクター マシン モジュールの両方を実験に追加します。
2 クラス ブースト デシジョン ツリー
まず、ブースト デシジョン ツリー モデルを以下の手順で設定します。
モジュール パレットで 2 クラス ブースト デシジョン ツリー モジュールを見つけ、キャンバスにドラッグします。
モデルのトレーニング モジュールを見つけてキャンバスにドラッグします。その後、2 クラス ブースト デシジョン ツリー モジュールの出力を、モデルのトレーニング モジュールの左側の入力ポート に接続します。
2 クラス ブースト デシジョン ツリー モジュールは汎用モデルを初期化し、トレーニング モデル モジュールはトレーニング データを使用してモデルをトレーニングします。
左側の R スクリプトの実行モジュールの左側の出力を、モデルのトレーニング モジュールの右側の入力ポートに接続します (このチュートリアルでは、データの分割モジュールの左側から出力されるデータをトレーニング用に使用しました)。
ヒント
この実験では、R スクリプトの実行モジュールの入力 2 つと出力 1 つは必要ないため、そのままにしておきます。
実験の一部は以下のようになっているはずです。
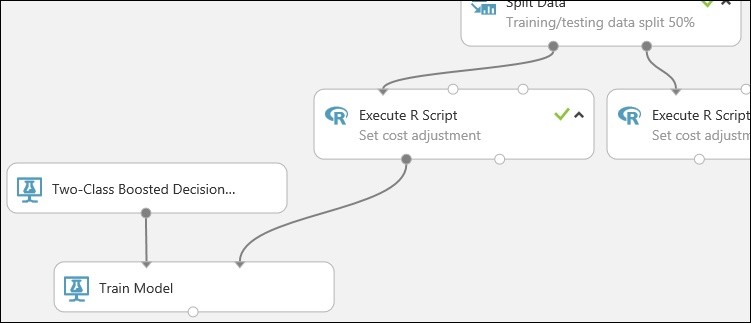
次に、モデルのトレーニング モジュールに対して、このモデルでは信用リスク値を予測するように通知する必要があります。
[モデルのトレーニング モジュール] を選択します。 [プロパティ] ウィンドウで、[列セレクターの起動] をクリックします。
[1 つの列の選択] ダイアログで、[使用可能な列] の下の検索フィールドに「Credit risk」と入力し、右矢印ボタン (>) をクリックして [Credit risk] を [選択した列] に移動します。

OK チェック マークをクリックします。
2 クラス サポート ベクター マシン
次に SVM モデルを設定します。
最初に、SVM について少し説明されます。 ブースト デシジョン ツリーはあらゆる種類の特徴で問題なく使うことができます。 ただし、SVM モジュールは線形分類子を生成するため、これによって生成されるモデルでは、すべての数値特徴のスケールが同一である場合に最適なテスト エラーが得られます。 すべての数値特徴を同じスケールに変換するには、"Tanh" 変換 (データの正規化モジュール) を使用します。 これによって特徴が [0,1] の範囲に変換されます。 文字列特徴は SVM モジュールによってカテゴリ特徴に変換され、バイナリ 0/1 特徴に変換されます。このため文字列特徴を手動で変換する必要はありません。 また、[Credit Risk] 列 (21 列目) は変換しません。これは数値ですが、トレーニングによってモデルが予測する値です。このため、この値はそのままにしておきます。
SVM モデルを設定するには、次の操作を行います。
モジュール パレットで 2 クラス サポート ベクター マシン モジュールを見つけ、キャンバスにドラッグします。
モデルのトレーニング モジュールを右クリックして [コピー] を選択し、キャンバスを右クリックして [貼り付け] を選択します。 モデルのトレーニング モジュールのコピーでも、元のモジュールと同じ列が選択されています。
2 クラス サポート ベクター マシン モジュールの出力を、2 つ目のモデルのトレーニング モジュールの左側の入力ポート に接続します。
データの正規化モジュールを見つけ、キャンバスにドラッグします。
左側の R スクリプトの実行モジュールの左側の出力を、このモジュールの入力に接続します (モジュールの出力ポートは、複数のモジュールに接続できることに注意してください)。
データの正規化モジュールの左側の出力ポートを、2 つ目のモデルのトレーニング モジュールの右側の入力ポートに接続します。
実験の一部は以下のようになっているはずです。
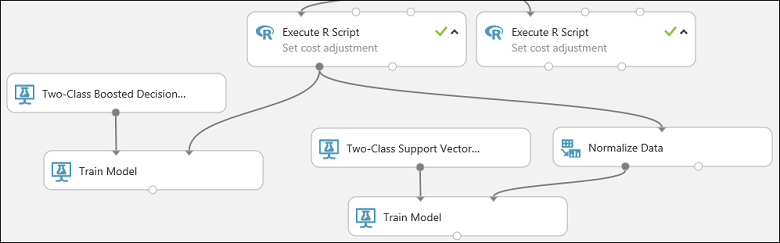
次に、データの正規化モジュールを構成します。
データの正規化モジュールをクリックして選択します。 [プロパティ] ウィンドウで、[変換メソッド] パラメーターに [Tanh] を選択します。
[列セレクターの起動] をクリックし、[が次の値で始まる] で [列なし] を選択し、最初のドロップダウンで [含める] を選択し、2 つ目のドロップダウンで [列の型] を選択します。3 つ目のドロップダウンで [数値] を選択します。 これによって、すべての数値列が (そして数値列のみが) 変換されます。
行の右側にあるプラス記号 (+) をクリックします。ドロップダウン リストの行が作成されます。 最初のドロップダウンで [除外] を選択し、2 つ目のドロップダウンで [列名] を選択し、テキスト フィールドに「Credit risk」と入力します。 これで [Credit Risk] 列を無視することが指定されます (この列は数値であり、指定がないと変換されてしまうため、この操作を行います)。
OK チェック マークをクリックします。
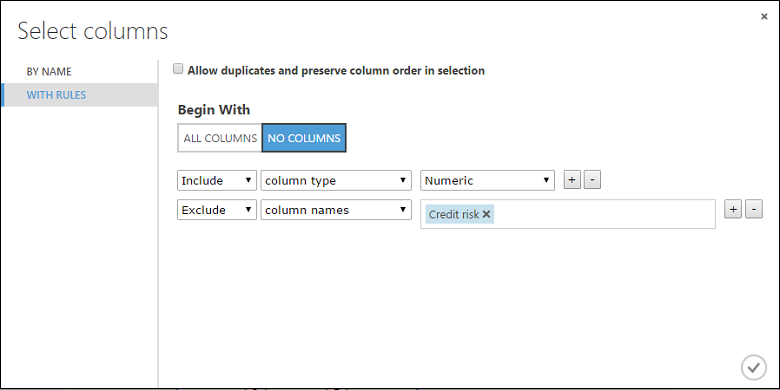
これで、データの正規化モジュールが、[Credit Risk] 列以外のすべての数値列で Tanh 変換を実行するように設定されました。
モデルにスコアを付け、評価する
データの分割モジュールによって分離されたテスト データを使用して、トレーニング済みのモデルにスコアを付けます。 その後、2 つのモデルの結果を比較して、どちらのモデルがより適した結果を生成したかを判断します。
モデルのスコア付けモジュールを追加する
モデルのスコア付けモジュールを見つけ、キャンバスにドラッグします。
2 クラス ブースト デシジョン ツリー モジュールに接続されているモデルのトレーニング モジュールを、モデルのスコア付けモジュールの左側の入力ポートに接続します。
右側の R スクリプトの実行モジュール (テスト データ) を、モデルのスコア付けモジュールの右側の入力ポートに接続します。
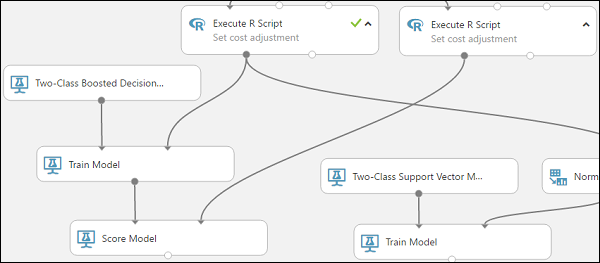
これで、モデルのスコア付けモジュールがテスト データから信用情報を取得し、モデルで実行し、テスト データの実際の信用リスク列を使用して生成されたモデルの予測と比較することができます。
モデルのスコア付けモジュールをコピーして貼り付けることで、2 つ目のコピーを作成します。
SVM モデルの出力 (つまり、2 クラス サポートベクター マシン モジュールに接続されたモデルのトレーニング モジュールの出力ポート) を、2 つ目のモデルのスコア付けモジュールの入力ポートに接続します。
SVM モデルでは、トレーニング用データに対する変換と同様の変換を、テスト用データにも実行する必要があります。 このため、データの正規化モジュールをコピーして貼り付けることで 2 つ目のコピーを作成し、それを R スクリプトの実行モジュールの右側に接続します。
2 つ目のデータの正規化モジュールの左側の出力を、2 つ目のモデルのスコア付けモジュールの右側の入力ポートに接続します。
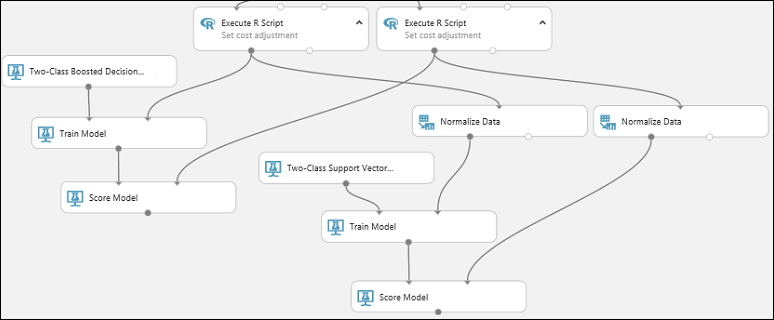
モデルの評価モジュールを追加する
2 つのスコア付けの結果を評価して比較するには、モデルの評価モジュールを使用します。
モデルの評価モジュールを見つけ、キャンバスにドラッグします。
ブースト デシジョン ツリー モデルに関連付けられたモデルのスコア付けモジュールの出力ポートを、モデルの評価モジュールの左側の入力ポートに接続します。
もう一方のモデルのスコア付けモジュールを、右側の入力ポートに接続します。
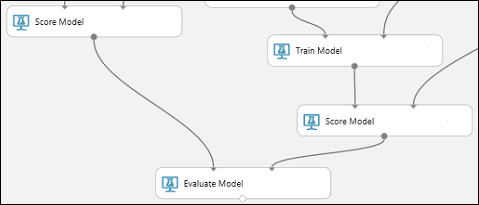
実験を実行して結果を確認する
実験を実行するには、キャンバスの下の [実行] ボタンをクリックします。 これには数分かかることがあります。 実行中であることを示す各モジュールのインジケーターが回転して、モジュールが完了すると、緑色のチェック マークが表示されます。 すべてのモジュールにチェック マークが付いたら、実験の実行は完了しています。
実験は以下のようになっているはずです。
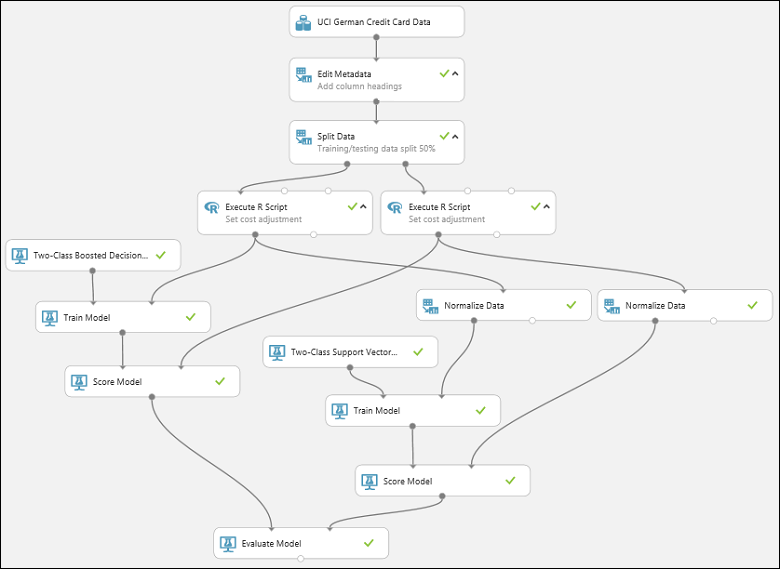
結果を確認するには、モデルの評価モジュールの出力ポートをクリックし、[視覚化] を選択します。
モデルの評価モジュールによって生成される曲線と測定値のペアを使用して、スコア付けされた 2 つのモデルの結果を比較できるようになります。 結果は、Receiver Operator Characteristic (ROC) 曲線、Precision/Recall 曲線、または Lift 曲線で表示できます。 表示されるその他の情報には、混同行列、累積の AUC (曲線下面積) 値、その他の測定値があります。 スライダーを左右に移動してしきい値を変更することで、変更が測定値に与える影響を確認することもできます。
グラフの右側の [スコア付けされたデータセット] または [スコア付けされた比較対象のデータセット] をクリックすると、関連付けられた曲線が強調表示され、関連する測定値が下に表示されます。 曲線の凡例では、[スコア付けされたデータセット] は、モデルの評価モジュールの左側の入力ポート (ここでは、ブースト デシジョン ツリー モデル) に対応しています。 [スコア付けされた比較対象のデータセット] は、右側の入力ポート (この場合、SVM モデル) に対応しています。 いずれかのラベルをクリックすると、そのモデルの曲線が強調表示され、次の図に示すように、関連する測定値が表示されます。
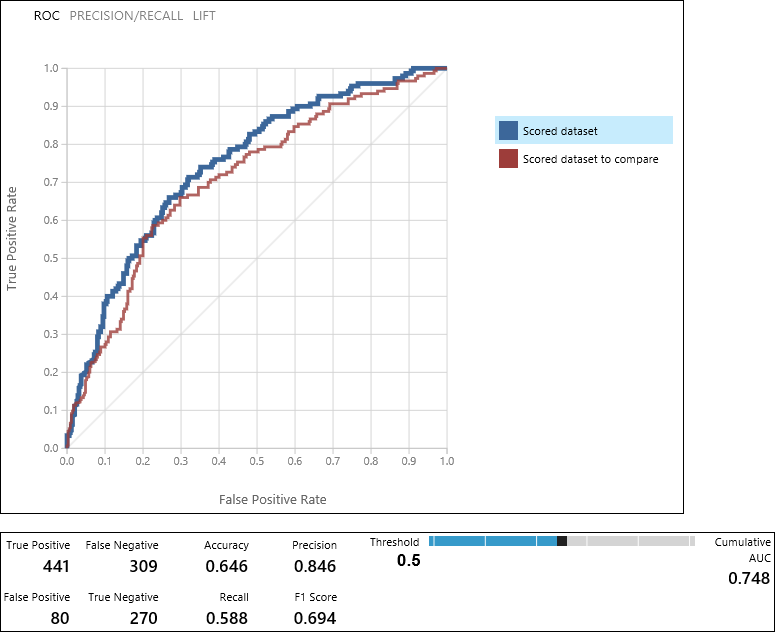
これらの値を検証することで、求めている結果に最も近い結果が得られるモデルを判断することができます。 モデルとパラメーター値を変えて実験を再度実行することもできます。
結果の解釈とモデルのパフォーマンスの調整に関するサイエンスとアートは、このチュートリアルの範囲外です。 詳細については、次の記事を参照してください。
- Machine Learning Studio (クラシック) でモデルのパフォーマンスを評価する方法
- Machine Learning Studio (クラシック) でアルゴリズムを最適化するパラメーターを選択する
- Machine Learning Studio (クラシック) でモデルの結果を解釈する
ヒント
実験を実行するたびに、イテレーションの記録が実行履歴に保存されます。 キャンバスの下にある [実行履歴を表示] をクリックすると、これらのイテレーションをいつでも表示し、いつでも実験に戻ることができます。 また、[プロパティ] ウィンドウの [前回の実行] をクリックすると、現在開いているイテレーションの前のイテレーションがすぐに表示されます。
キャンバスの下にある [名前を付けて保存] をクリックすることで、実験のイテレーションのコピーを作成できます。 実験の [概要] と [説明] のプロパティを使用して、実験のイテレーションで行った内容を記録します。
詳細については、Machine Learning Studio (クラシック) での実験イテレーションの管理に関するページを参照してください。
リソースをクリーンアップする
この記事を使用して作成したリソースが不要になった場合は、料金の発生を避けるために削除してください。 方法については、製品内ユーザー データのエクスポートと削除に関するページを参照してください。
次のステップ
このチュートリアルでは、次の手順を完了しました。
- 実験の作成
- 複数のモデルをトレーニングする
- モデルにスコアを付け、評価する
これで、このデータのモデルをデプロイする準備が整いました。