AKS 上の HDInsight の Apache Spark™ クラスターでジョブを送信および管理する
大事な
AKS 上の Azure HDInsight は、2025 年 1 月 31 日に廃止されました。 このお知らせ により、について詳しく知ることができます。
ワークロードの突然の終了を回避するには、ワークロードを Microsoft Fabric または同等の Azure 製品 に移行する必要があります。
大事な
この機能は現在プレビュー段階です。 Microsoft Azure プレビューの 追加使用条件 には、ベータ版、プレビュー版、または一般公開されていない Azure 機能に適用される、より多くの法的条件が含まれています。 この特定のプレビューの詳細については、AKS プレビュー情報 Azure HDInsightを参照してください。 ご質問や機能の提案については、詳細を記載したリクエストを AskHDInsight に送信してください。また、最新情報を入手するために Azure HDInsight Communityをフォローしてください。
クラスターが作成されると、ユーザーはさまざまなインターフェイスを使用してジョブを送信および管理できます。
- Jupyter の使用
- Zeppelin の使用
- ssh の使用 (spark-submit)
Jupyter の使用
前提 条件
AKS 上の HDInsight 上の Apache Spark™ クラスター。 詳細については、「Apache Spark クラスターの作成」を参照してください。
Jupyter Notebook は、さまざまなプログラミング言語をサポートする対話型ノートブック環境です。
Jupyter Notebook を作成する
Apache Spark™ クラスター ページに移動し、の [概要] タブを開きます。Jupyter をクリックすると、Jupyter Web ページを認証して開くように求められます。

Jupyter Web ページで、[新規] > PySpark を選択してノートブックを作成します。
新しいノートブックが作成され、
Untitled(Untitled.ipynb)という名前で開かれます。手記
PySpark または Python 3 カーネルを使用してノートブックを作成すると、最初のコード セルの実行時に Spark セッションが自動的に作成されます。 セッションを明示的に作成する必要はありません。
Jupyter Notebook の空のセルに次のコードを貼り付け、Shift キーを押しながら Enter キーを押してコードを実行します。 Jupyter の詳細なコントロールについては、の を参照してください。
%matplotlib inline import pandas as pd import matplotlib.pyplot as plt data1 = [22,40,10,50,70] s1 = pd.Series(data1) #One-dimensional ndarray with axis labels (including time series). data2 = data1 index = ['John','sam','anna','smith','ben'] s2 = pd.Series(data2,index=index) data3 = {'John':22, 'sam':40, 'anna':10,'smith':50,'ben':70} s3 = pd.Series(data3) s3['jp'] = 32 #insert a new row s3['John'] = 88 names = ['John','sam','anna','smith','ben'] ages = [10,40,50,48,70] name_series = pd.Series(names) age_series = pd.Series(ages) data_dict = {'name':name_series, 'age':age_series} dframe = pd.DataFrame(data_dict) #create a pandas DataFrame from dictionary dframe['age_plus_five'] = dframe['age'] + 5 #create a new column dframe.pop('age_plus_five') #dframe.pop('age') salary = [1000,6000,4000,8000,10000] salary_series = pd.Series(salary) new_data_dict = {'name':name_series, 'age':age_series,'salary':salary_series} new_dframe = pd.DataFrame(new_data_dict) new_dframe['average_salary'] = new_dframe['age']*90 new_dframe.index = new_dframe['name'] print(new_dframe.loc['sam'])給与と年齢を X 軸と Y 軸としてグラフをプロットする
同じノートブックで、Jupyter Notebook の空のセルに次のコードを貼り付け、shift キー 押しながら Enter キーを押してコードを実行します。
%matplotlib inline import pandas as pd import matplotlib.pyplot as plt plt.plot(age_series,salary_series) plt.show()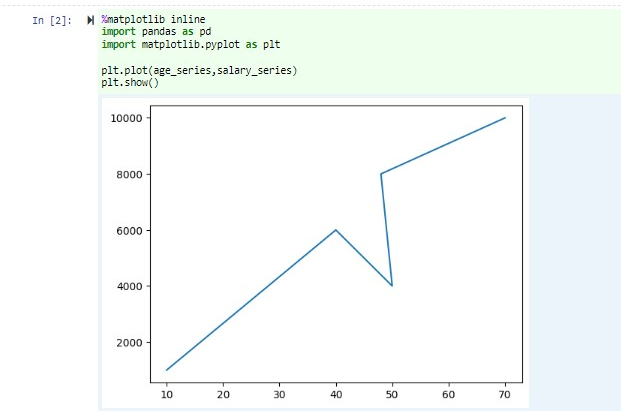




ノートブックを保存する
ノートブックのメニュー バーから、[ファイル] > [保存とチェックポイント] に移動します。
ノートブックをシャットダウンしてクラスター リソースを解放します。ノートブックのメニュー バーから、[ファイル] > [閉じて停止] に移動します。 examples フォルダーの下にある任意のノートブックを実行することもできます。


Apache Zeppelin ノートブックの使用
AKS 上の HDInsight の Apache Spark クラスターには、Apache Zeppelin ノートブックが含まれます。 ノートブックを使用して Apache Spark ジョブを実行します。 この記事では、AKS クラスター上の HDInsight で Zeppelin ノートブックを使用する方法について説明します。
前提 条件
AKS 上の HDInsight 上の Apache Spark クラスター。 手順については、「Apache Spark クラスターを作成する」を参照してください。
Apache Zeppelin ノートブックを起動する
Apache Spark クラスターの [概要] ページに移動し、クラスター ダッシュボードから Zeppelin ノートブックを選択します。 認証を求め、Zeppelin ページを開きます。
新しいノートブックを作成します。 ヘッダー ウィンドウで、[ノートブック] > [新しいメモの作成] に移動します。 ノートブック ヘッダーに接続状態が表示されていることを確認します。 右上隅に緑色の点が表示されます。
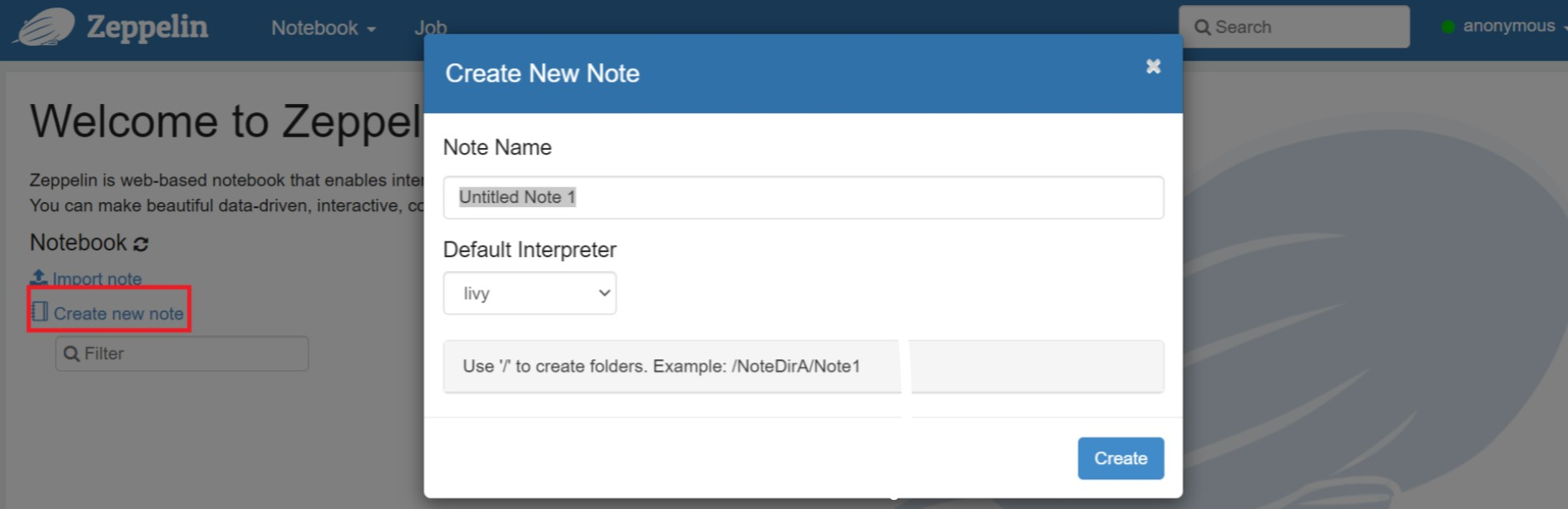
Zeppelin Notebook で次のコードを実行します。
%livy.pyspark import pandas as pd import matplotlib.pyplot as plt data1 = [22,40,10,50,70] s1 = pd.Series(data1) #One-dimensional ndarray with axis labels (including time series). data2 = data1 index = ['John','sam','anna','smith','ben'] s2 = pd.Series(data2,index=index) data3 = {'John':22, 'sam':40, 'anna':10,'smith':50,'ben':70} s3 = pd.Series(data3) s3['jp'] = 32 #insert a new row s3['John'] = 88 names = ['John','sam','anna','smith','ben'] ages = [10,40,50,48,70] name_series = pd.Series(names) age_series = pd.Series(ages) data_dict = {'name':name_series, 'age':age_series} dframe = pd.DataFrame(data_dict) #create a pandas DataFrame from dictionary dframe['age_plus_five'] = dframe['age'] + 5 #create a new column dframe.pop('age_plus_five') #dframe.pop('age') salary = [1000,6000,4000,8000,10000] salary_series = pd.Series(salary) new_data_dict = {'name':name_series, 'age':age_series,'salary':salary_series} new_dframe = pd.DataFrame(new_data_dict) new_dframe['average_salary'] = new_dframe['age']*90 new_dframe.index = new_dframe['name'] print(new_dframe.loc['sam'])段落の [再生] ボタンを選択してスニペットを実行します。 段落の右上隅の状態は、READY、PENDING、RUNNING から FINISHED に進む必要があります。 出力は、同じ段落の下部に表示されます。 スクリーンショットは次の図のようになります。

アウトプット:





Sparkジョブの送信を使用する
次のコマンド '#vim samplefile.py' を使用してファイルを作成する
このコマンドを実行すると、vim ファイルが開きます。
次のコードを vim ファイルに貼り付けます
import pandas as pd import matplotlib.pyplot as plt From pyspark.sql import SparkSession Spark = SparkSession.builder.master('yarn').appName('SparkSampleCode').getOrCreate() # Initialize spark context data1 = [22,40,10,50,70] s1 = pd.Series(data1) #One-dimensional ndarray with axis labels (including time series). data2 = data1 index = ['John','sam','anna','smith','ben'] s2 = pd.Series(data2,index=index) data3 = {'John':22, 'sam':40, 'anna':10,'smith':50,'ben':70} s3 = pd.Series(data3) s3['jp'] = 32 #insert a new row s3['John'] = 88 names = ['John','sam','anna','smith','ben'] ages = [10,40,50,48,70] name_series = pd.Series(names) age_series = pd.Series(ages) data_dict = {'name':name_series, 'age':age_series} dframe = pd.DataFrame(data_dict) #create a pandas DataFrame from dictionary dframe['age_plus_five'] = dframe['age'] + 5 #create a new column dframe.pop('age_plus_five') #dframe.pop('age') salary = [1000,6000,4000,8000,10000] salary_series = pd.Series(salary) new_data_dict = {'name':name_series, 'age':age_series,'salary':salary_series} new_dframe = pd.DataFrame(new_data_dict) new_dframe['average_salary'] = new_dframe['age']*90 new_dframe.index = new_dframe['name'] print(new_dframe.loc['sam'])次の方法でファイルを保存します。
- [エスケープ] ボタンを押す
- コマンド
:wqを入力します
次のコマンドを実行してジョブを実行します。
/spark-submit --master yarn --deploy-mode cluster <filepath>/samplefile.py

AKS 上の HDInsight の Apache Spark クラスターでクエリを監視する
Spark 履歴 UI
[概要] タブで Spark History Server UI をクリックします。

同じアプリケーション ID を使用して、UI から最近実行した実行を選択します。
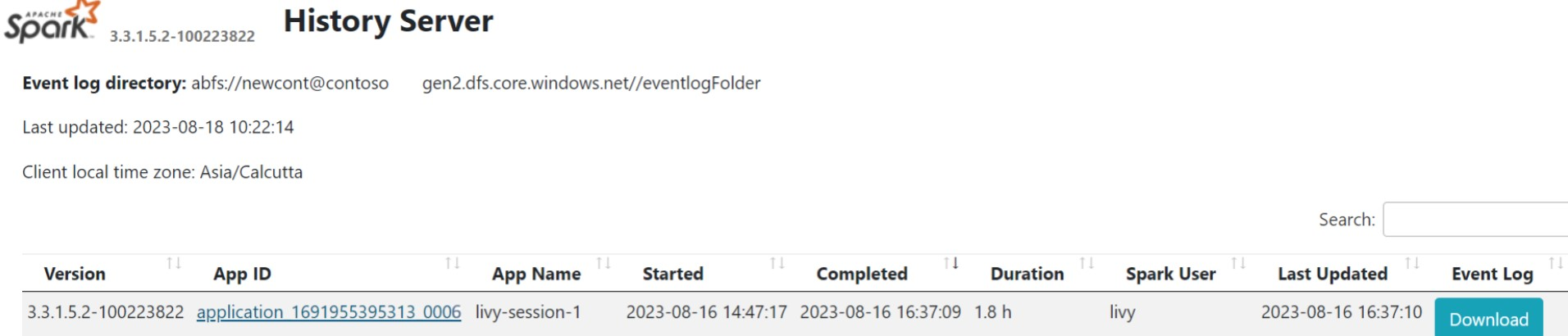
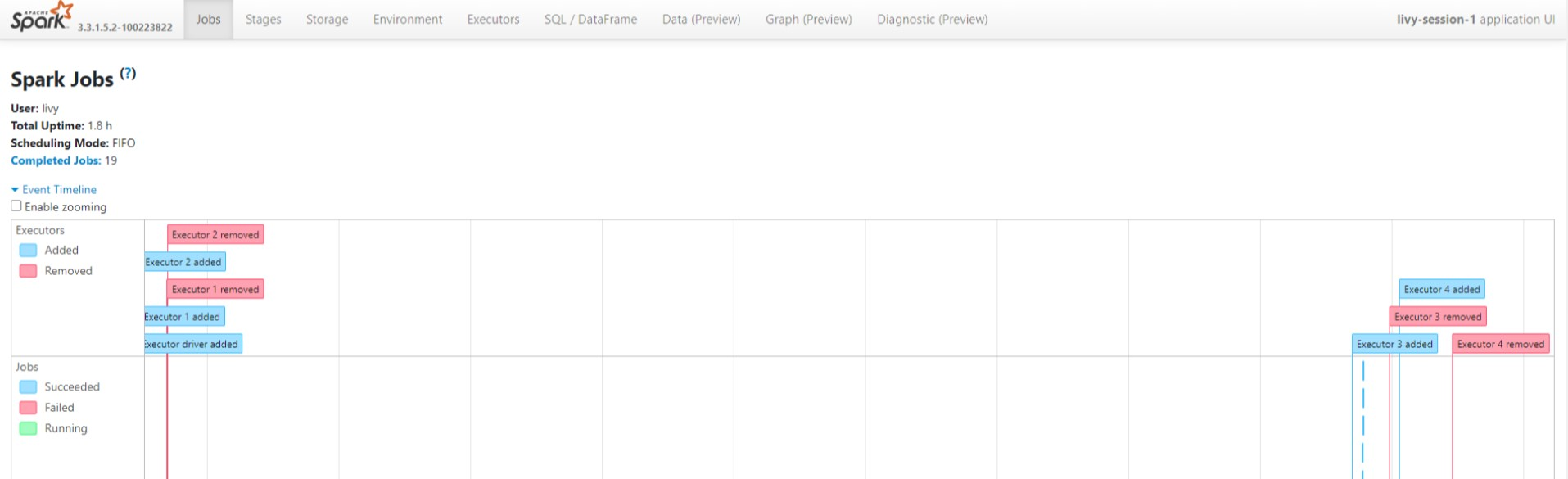
Spark History サーバー UI で、有向非循環グラフ のサイクルとジョブのステージを表示します。



Livy セッション UI
Livy セッション UI を開くには、ブラウザーに次のコマンドを入力
https://<CLUSTERNAME>.<CLUSTERPOOLNAME>.<REGION>.projecthilo.net/p/livy/ui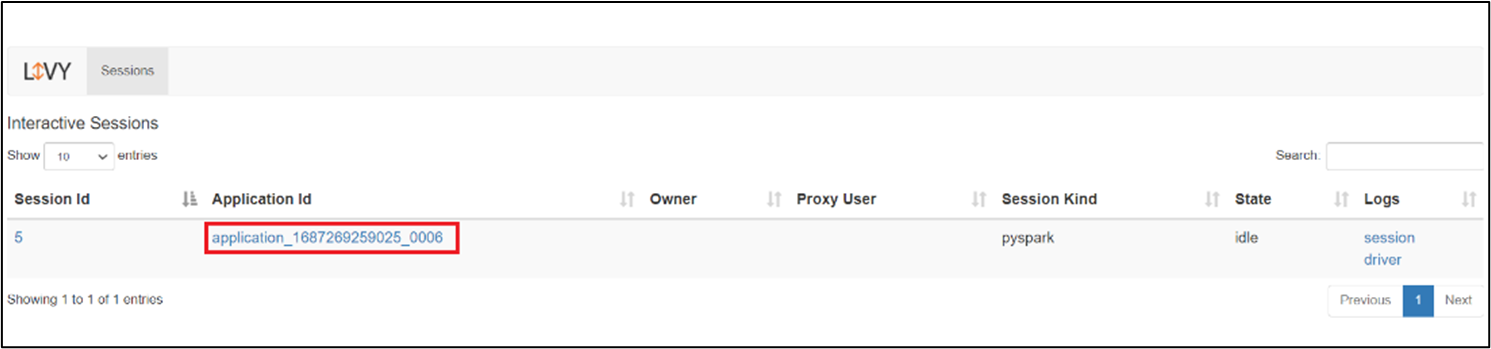
[ログ] の下にあるドライバー オプションをクリックして、ドライバー ログを表示します。

Yarn UI
[概要] タブで [Yarn] をクリックし、Yarn UI を開きます。
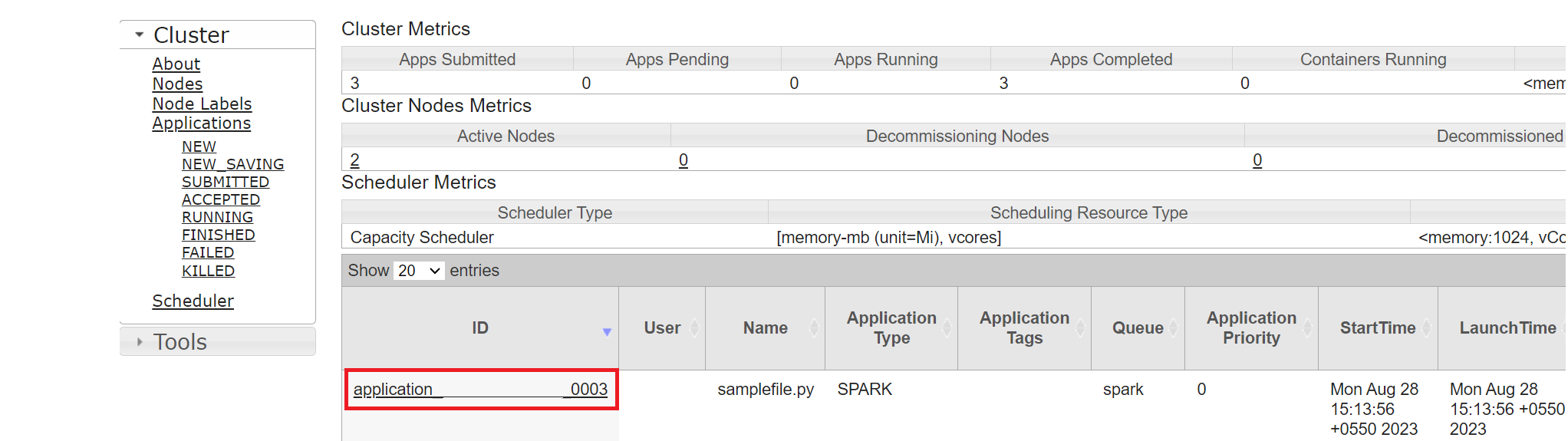
最近実行したジョブは、同じアプリケーション ID で追跡できます。
Yarn のアプリケーション ID をクリックして、ジョブの詳細なログを表示します。


参考
- Apache、Apache Spark、Spark、及び関連するオープンソースプロジェクト名は、Apache Software Foundation (ASF) の商標です。