AKS 上の HDInsight の Apache Spark™ とは (プレビュー)
大事な
AKS 上の Azure HDInsight は、2025 年 1 月 31 日に廃止されました。 この発表 でについてさらに知ることができます。
ワークロードの突然の終了を回避するには、ワークロードを Microsoft Fabric または同等の Azure 製品 に移行する必要があります。
重要
この機能は現在プレビュー段階です。 Microsoft Azure プレビューの 追加使用条件 には、ベータ版、プレビュー版、または一般公開されていない Azure 機能に適用される、より多くの法的条件が含まれています。 この特定のプレビューの詳細については、AKS プレビュー情報 Azure HDInsightを参照してください。 ご質問や機能の提案については、AskHDInsight に詳細を記載した要求を送信し、Azure HDInsight Community の詳細な更新プログラムについてお問い合わせください。
Apache Spark™ は、ビッグ データ分析アプリケーションのパフォーマンスを向上させるためにメモリ内処理をサポートする並列処理フレームワークです。
Apache Spark™ には、インメモリ クラスター コンピューティング用のプリミティブが用意されています。 Spark ジョブは、データをメモリに読み込んでキャッシュし、繰り返しクエリを実行できます。 メモリ内コンピューティングは、Hadoop 分散ファイル システム (HDFS) を介してデータを共有する Hadoop などのディスク ベースのアプリケーションよりも高速です。 Apache Spark を使用すると、Scala および Python プログラミング言語と統合して、ローカル コレクションなどの分散データ セットを操作できます。 マップ操作と reduce 操作としてすべてを構造化する必要はありません。
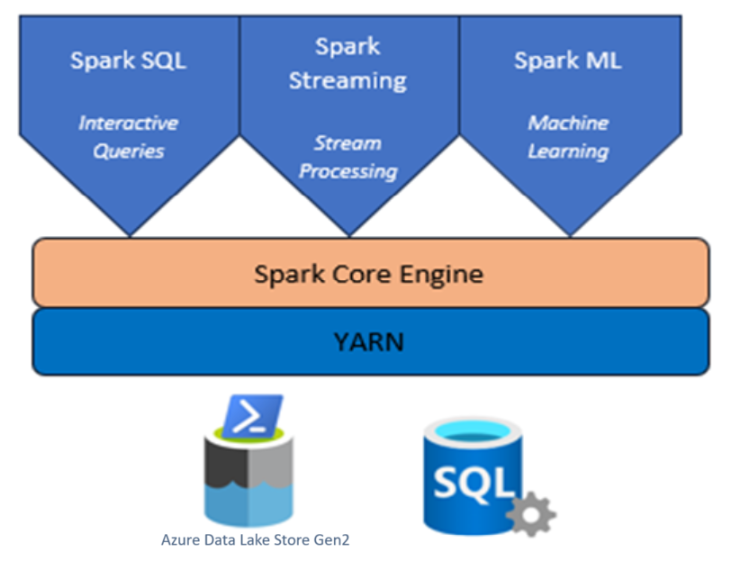
AKS 上の HDInsight を使用した Apache Spark クラスター
Azure HDInsight は、企業向けのマネージドで幅広いオープンソースの分析サービスです。
AKS 上の Azure HDInsight の Apache Spark™ は、Microsoft Azure のマネージド Spark サービスです。 AKS 上の Azure HDInsight の Apache Spark を使用すると、Azure 内のすべてのデータを格納して処理できます。 HDInsight の Spark クラスターは、Azure Data Lake Storage Gen2 と互換性があるか、既存のデータ ストアに Spark 処理を適用できます。
AKS 上の HDInsight 用 Apache Spark フレームワークを使用すると、インメモリ処理を使用した高速なデータ分析とクラスター コンピューティングが可能になります。 Jupyter Notebook を使用すると、データの操作、コードとマークダウン テキストの組み合わせ、簡単な視覚化を行うことができます。
HDInsight 上の AKS で稼働する Apache Spark は、複数のコンポーネントがポッドとして構成されています。
クラスター コントローラー
クラスター コントローラーは、それぞれのサービスのインストールと管理を担当します。 さまざまなコントローラーが Spark クラスターにインストールされ、管理されます。
Apache Spark サービス コンポーネント
Zookeeper サービス: 3 ノードの Zookeeper クラスターは、他のサービスの分散コーディネーターまたは高可用性ストレージとして機能します。
Yarn サービス: Hadoop Yarn クラスター、Spark ジョブは Yarn アプリケーションとしてクラスター内でスケジュールされます。
クライアント インターフェイス: AKS 上の HDInsight の Apache Spark クラスター、さまざまなクライアント インターフェイスを提供します。 Livy Server、Jupyter Notebook、Spark History Server は、AKS ユーザーの HDInsight に Spark サービスを提供します。
参考
- Apache、Apache Spark、Spark、および関連するオープンソースプロジェクト名は、Apache Software Foundation (ASF) の 商標です。