AKS クラスターでの HDInsight の自動スケール
大事な
AKS 上の Azure HDInsight は、2025 年 1 月 31 日に廃止されました。 この発表 でについて詳しく学びましょう。
ワークロードの突然の終了を回避するには、ワークロードを Microsoft Fabric または同等の Azure 製品 に移行する必要があります。
大事な
この機能は現在プレビュー段階です。 Microsoft Azure プレビューの 追加使用条件 には、ベータ版、プレビュー版、または一般公開されていない Azure 機能に適用される、より多くの法的条件が含まれています。 この特定のプレビューの詳細については、AKS プレビュー情報 Azure HDInsightを参照してください。 ご質問や機能の提案については、AskHDInsight に詳細を記載した要求を送信し、Azure HDInsight Communityの更新についてフォローしてください。
ジョブのパフォーマンスを満たし、コストを事前に管理するためのクラスターのサイズ設定は、常に難しく、判断が困難です。 Data Lake House over Cloud を構築する利点の 1 つは弾力性です。つまり、自動スケール機能を使用して、手元のリソースの使用率を最大化します。 Kubernetes を使用した自動スケールは、コスト最適化エコシステムを確立するための 1 つの鍵です。 どの企業でもさまざまな使用パターンが存在する場合、クラスターの負荷が時間の経過と共に変化し、クラスターのプロビジョニング不足 (パフォーマンスが低下) または過剰プロビジョニング (アイドル 状態のリソースによる不要なコスト) につながる可能性があります。
AKS 上の HDInsight で提供される自動スケール機能では、クラスター内のワーカー ノードの数を自動的に増減できます。 自動スケールでは、顧客が使用するクラスター メトリックとスケーリング ポリシーが使用されます。
この機能は、ミッション クリティカルなワークロードに適しています。
- 可変または予測不可能なトラフィック パターンで、高パフォーマンスとスケールで SLA を必要とします。
- クラスターでジョブを正常に実行するために必要なワーカー ノードを使用できるようにするための事前に定義されたスケジュール。
AKS クラスター上の HDInsight を使用した自動スケールにより、クラスターのコスト効率と Azure でのエラスティック性が向上します。
自動スケールを使用すると、ワークロードに影響を与えずにクラスターをスケールダウンできます。 これは、円滑な停止やクールダウン期間などの高度な機能が備わっています。 これらの機能により、ユーザーは、クラスターの現在の負荷に基づいてノードの追加と削除に関する情報に基づいた選択を行うことができます。
しくみ
この機能は、クラスターメトリックまたは定義されたスケールアップおよびスケールダウン操作のスケジュールに基づいて、事前設定された制限内のノード数をスケーリングすることによって機能します。 自動スケール イベントをトリガーする条件には、さまざまなクラスター パフォーマンス メトリックのしきい値ベースのトリガー (負荷ベースのスケーリングと呼ばれます) と時間ベースのトリガー (スケジュール ベースのスケーリングと呼ばれます) の 2 種類があります。
負荷ベースのスケーリングでは、最適な CPU 使用率を確保し、実行コストを最小限に抑えるために、設定した範囲内でクラスター内のノードの数が変更されます。
スケジュールベースのスケーリングでは、スケールアップ操作とスケールダウン操作のスケジュールに基づいて、クラスター内のノードの数が変更されます。
手記
自動スケールでは、既存のクラスターの SKU の種類の変更はサポートされていません。
クラスターの互換性
次の表では、自動スケール機能と互換性のあるクラスターの種類と、使用可能なクラスターまたは計画されている内容について説明します。
| ワークロード | 負荷ベース | スケジュールに基づく |
|---|---|---|
| Flink | 計画された | はい |
| Trino | はい** | はい** |
| 火花 | はい** | はい** |
優雅な停止は構成可能です。
スケーリング メソッド
スケジュール ベースのスケーリング:
ジョブが固定スケジュールで実行されることが予想される場合、または予測可能な期間、または特定の時間帯に使用率が低いことが予想される場合 (たとえば、勤務時間後のテスト環境や開発環境、一日の終わりのジョブなど)。
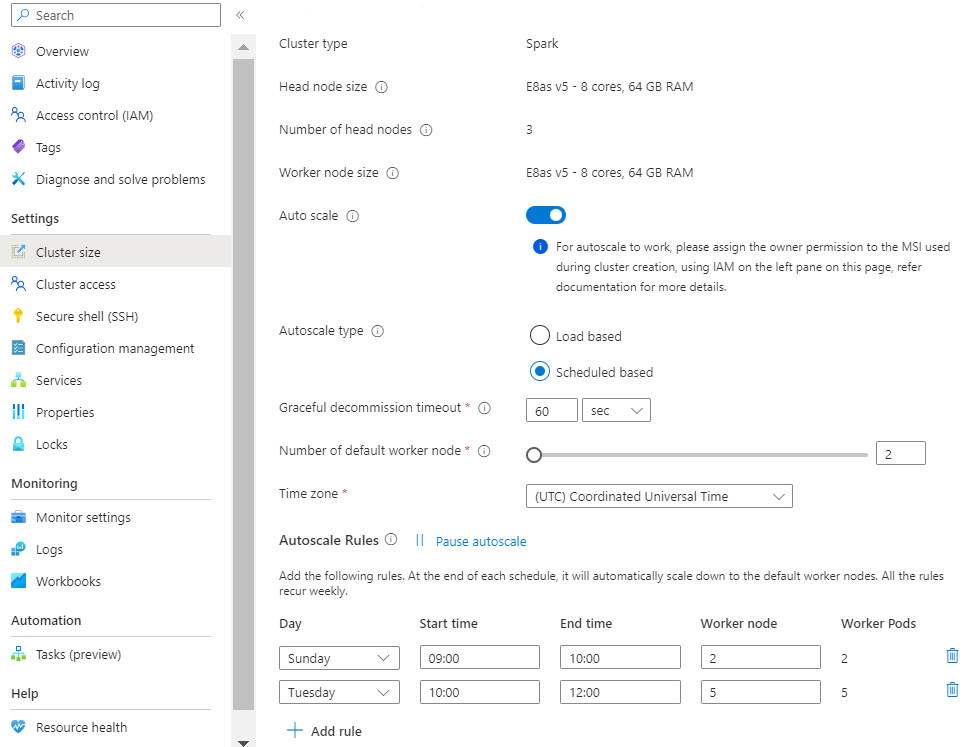
負荷ベースのスケール:
負荷パターンが 1 日の間に大きく予測不能に変動する場合 (たとえば、さまざまな要因に基づいて負荷パターンがランダムに変動する Order データ処理)。

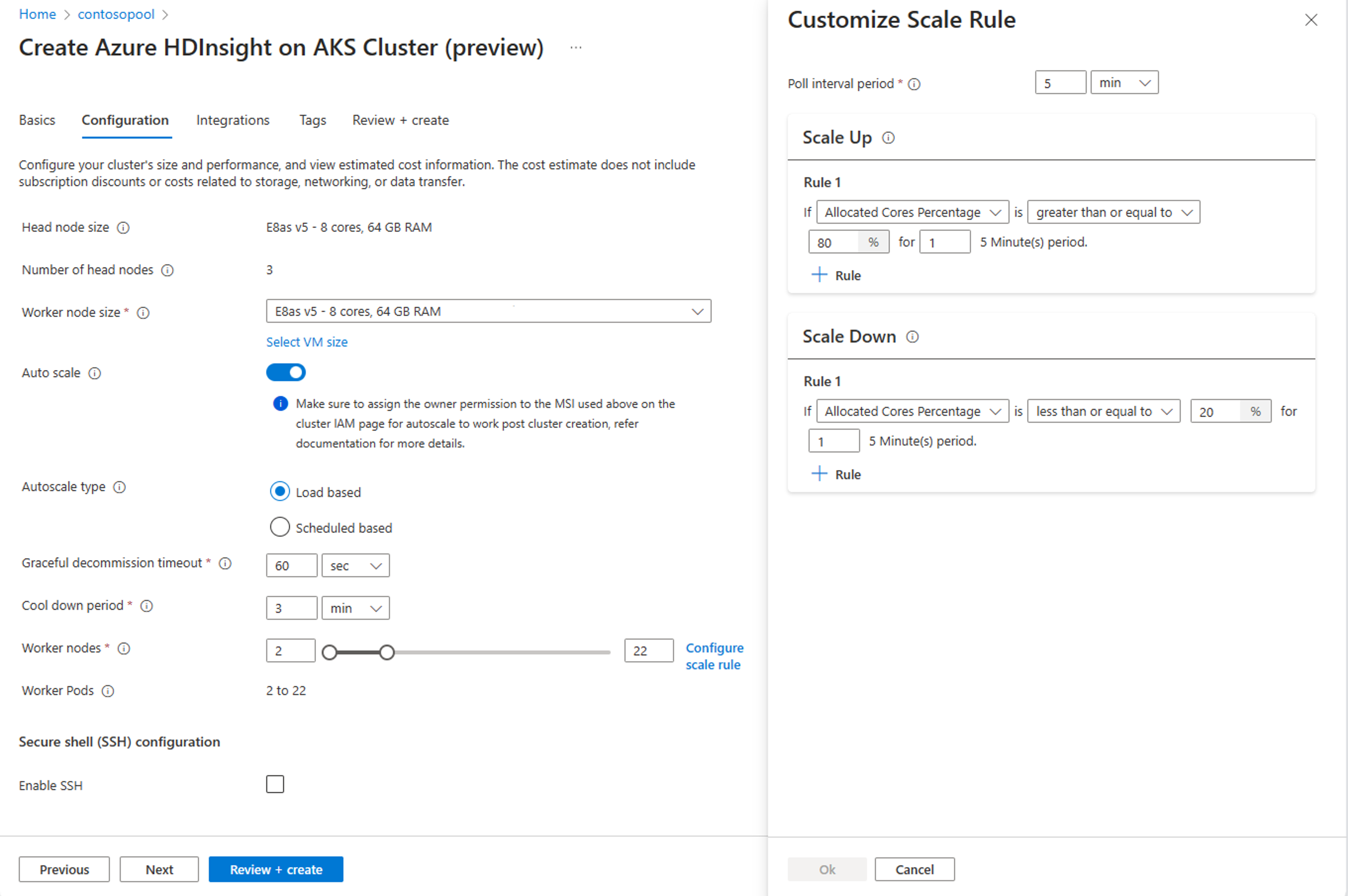
新しい [スケール ルールの構成] オプションを使用して、スケール ルールをカスタマイズできるようになりました。
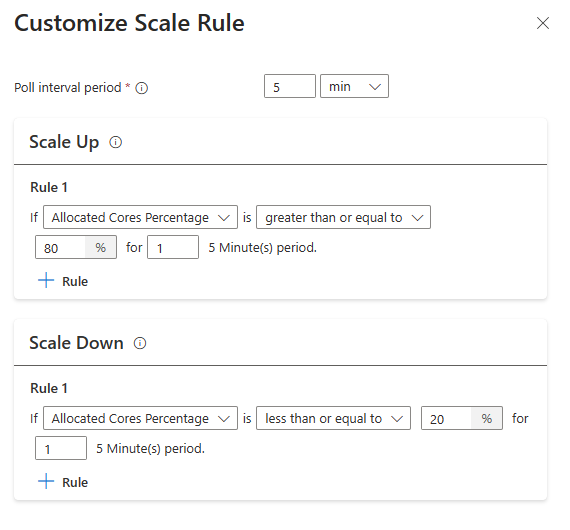
アドバイス
- スケールアップ ルールは、1 つ以上のルールがトリガーされたときに優先されます。 スケールアップの規則の 1 つだけがクラスターのプロビジョニング不足を示唆している場合でも、クラスターはスケールアップを試みます。 スケール ダウンを実行するには、スケールアップ ルールをトリガーする必要はありません。


負荷ベースのスケール条件
次の条件が検出されると、オートスケールによってスケール要求が行われます。
| スケールアップ | 縮小 |
|---|---|
| 割り当てられたコアは、5 分間のポーリング間隔 (1 分のチェック期間) で 80% を超えています | 割り当てられたコアは、5 分間のポーリング間隔 (1 分のチェック期間) で 20% 以下です |
スケールアップの場合、自動スケールでは、必要な数のノードを追加するスケールアップ要求が発行されます。 スケールアップは、現在の CPU とメモリの要件を満たすために必要な新しいワーカー ノードの数に基づいています。 この値は、設定されたワーカー ノードの最大数に制限されます。
スケールダウンの場合、自動スケールでは、一部のノードを削除する要求が発行されます。 スケール ダウンの考慮事項には、ノードあたりのポッド数、現在の CPU とメモリの要件、ワーカー ノードが含まれます。これは、現在のジョブの実行に基づく削除の候補です。 スケール ダウン操作では、最初にノードの使用を停止してから、クラスターから削除します。
大事な
自動スケール ルール エンジンは、システム メモリを最適化するために、30 分 ごとに古いイベントを事前にフラッシュします。 その結果、スケーリング ルールの間隔には上限の 30 分が存在します。 スケーリング アクションの一貫性と信頼性の高いトリガーを確保するには、スケーリング ルールの間隔を制限より小さい値に設定する必要があります。 このガイドラインに従うことで、システム リソースを効果的に管理しながら、スムーズで効率的なスケーリング プロセスを保証できます。
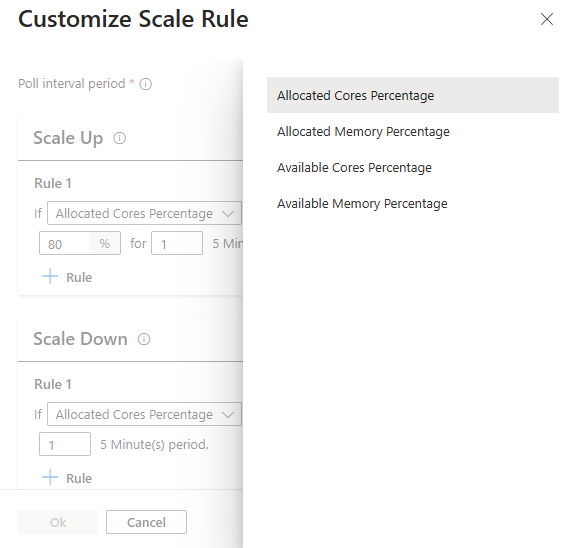
クラスター メトリック
自動スケールでは、クラスターが継続的に監視され、負荷ベースの自動スケールに関する次のメトリックが収集されます。
スケーリングの目的で使用できるクラスター メトリック
| メトリック | 説明 |
|---|---|
| 使用可能なコアの割合 | クラスター内のコアの合計数と比較した、クラスターで使用可能なコアの合計数。 |
| 使用可能なメモリの割合 | クラスターで使用可能なメモリの合計 (MB 単位) と、クラスター内のメモリの合計量。 |
| 割り当てられたコアの割合 | クラスターに割り当てられたコアの合計数と、クラスター内のコアの合計数。 |
| 割り当てられたメモリの割合 | クラスターに割り当てられたメモリの量と、クラスター内のメモリの合計量。 |
既定では、上記のメトリックは 300 秒 ごとにチェックされます。また、自動スケールのカスタマイズ オプションを使用してポーリング間隔をカスタマイズするときにも構成できます。 自動スケールでは、これらのメトリックに基づいてスケールアップまたはスケールダウンの決定が行われます。
手記
既定では、自動スケールでは、APACHE Spark 用 YARN の既定のリソース計算ツールが使用されます。 Apache Spark クラスターでは、負荷ベースのスケーリングを使用できます。
優雅な廃止
企業には、自動スケーリングを使用してペタバイト規模を実現し、不要になったときにリソースを適切に使用停止する方法が必要です。 このようなシナリオでは、円滑な利用停止機能が便利です。
正常なデコミッショニングにより、自動スケーリングでワーカーノードの使用停止がトリガーされた後も、ジョブを最後まで完了させることができます。 この機能を使用すると、ジョブが完了するまでノードのプロビジョニングを続行できます。
Trino: ワーカーでは、グレースフル 使用停止が既定で有効になっています。 コーディネーターは、ワーカーをクラスターから削除する前に、構成された時間内にワーカーがそのタスクを完了できるようにします。 タイムアウトは、ネイティブの Trino パラメーター
shutdown.grace-periodを使用するか、Azure portal サービス構成ページで構成できます。Apache Spark: スケールダウンは、クラスター内の実行中のジョブに影響を与える可能性があります。 Azure portal でグレースフル 使用停止設定を有効にすると、YARN ノードのグレースフル 使用停止が組み込まれており、ワーカー ノードで進行中の作業が完了してから、ノードが AKS クラスター上の HDInsight から削除されます。
クールダウン期間
継続的なスケールアップ操作を回避するために、自動スケール エンジンは構成可能な間隔を待機してから、別のスケール アップ操作のセットを開始します。 既定値は 180 秒 に設定
手記
- カスタム スケール ルールでは、トリガー間隔が 30 分を超えるルール トリガーはありません。 自動スケーリング イベントが発生した後、別のスケーリング ポリシーを適用するまでの待機時間。
- クラスター メトリックをリセットできるように、クール ダウン期間はポリシー間隔より大きくする必要があります。
作業の開始
自動スケールを機能させるためには、左側のウィンドウの IAM を使用して、所有者 または 共同作成者 アクセス許可をクラスター レベルで MSI に割り当てる必要があります (クラスターの作成時に使用)。
ロールの割り当てを追加する方法については、次の図と手順を参照してください
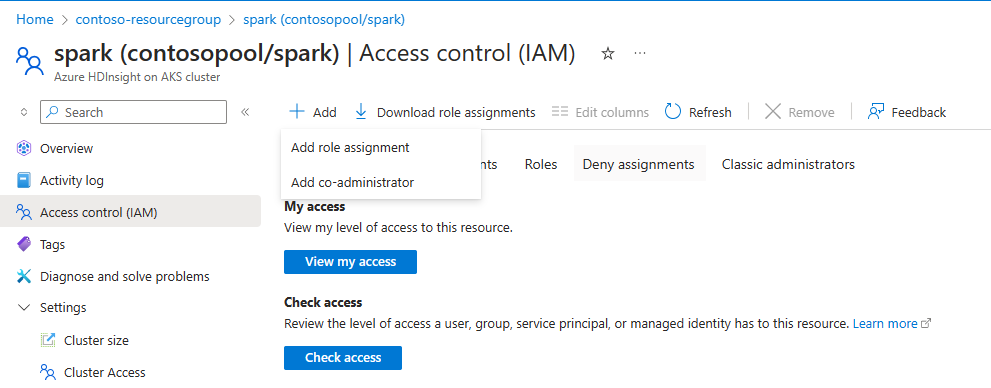
[役割の割り当てを追加] を選択します。
- 割り当ての種類: 特権管理者ロール
- ロール: 所有者 または コントリビューター
- メンバー: マネージド ID を選択し、クラスターの作成フェーズ中に指定されたユーザー割り当てマネージド ID を選択します。
- ロールを割り当てます。

スケジュール ベースの自動スケールを使用してクラスターを作成する
クラスター プールが作成されたら、目的のワークロード (クラスターの種類) で 新しいクラスター を作成し、通常のクラスター作成プロセスの一環として他の手順を完了します。
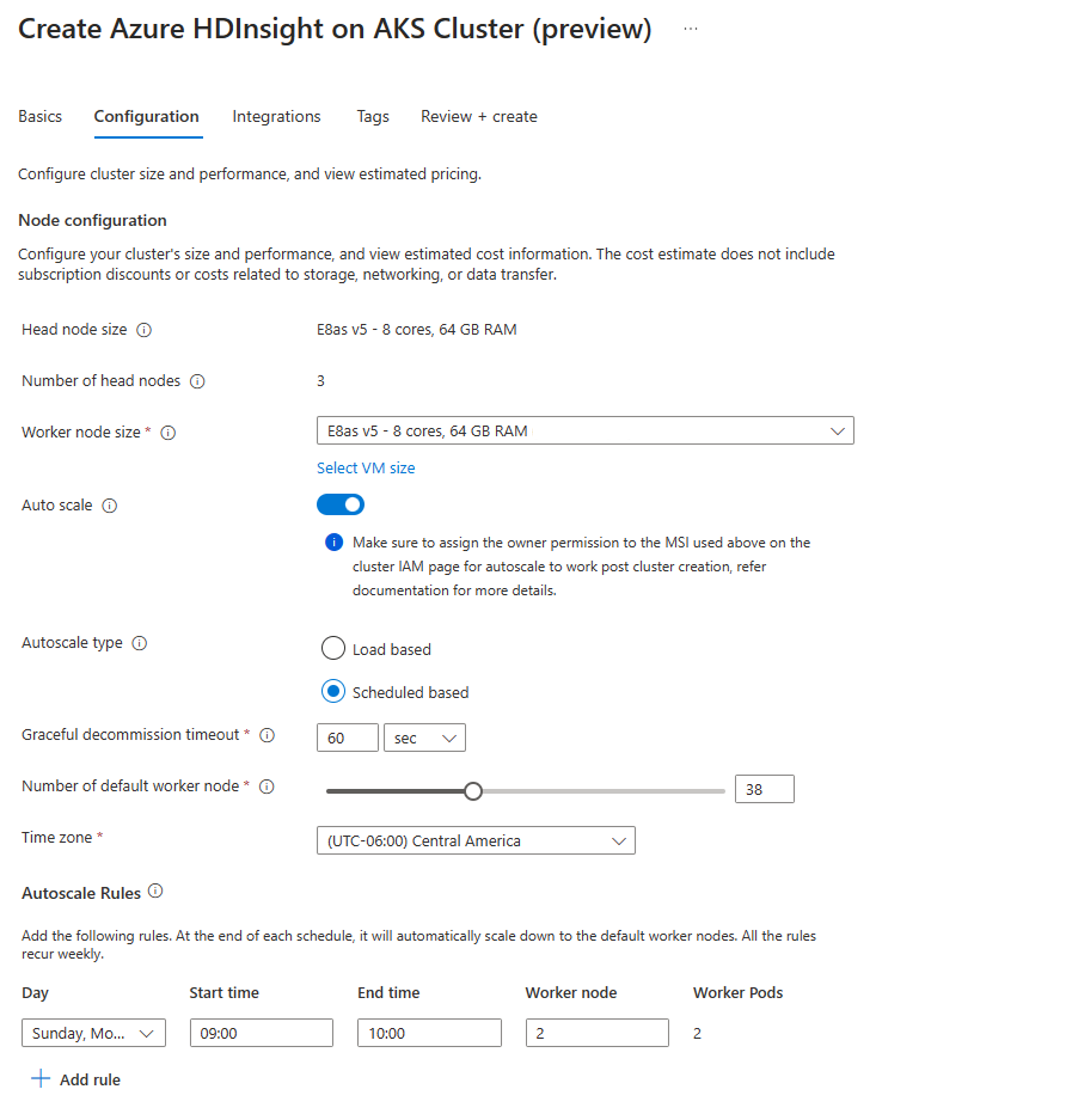
[構成] タブで、[自動スケール 切り替え 有効にします。
自動スケーリング 基づいてスケジュール 選択する
タイムゾーンを選択し、[+ ルール の追加] をクリックします。
新しい条件を適用する曜日を選択します。
条件が有効になる時間と、クラスターのスケールの対象となるノードの数を編集します。
手記
- 自動スケールを機能させるには、ユーザーにクラスター MSI の "所有者" または "共同作成者" ロールが必要です。
- 既定値は、作成時のクラスターの初期サイズを定義します。
- 2 つのスケジュールの違いは、既定で 30 分に設定されます。
- 時刻の値は 24 時間形式に従います
- 日数が 24 時間を超える連続期間の場合、自動スケール スケジュールを日単位で設定する必要があります。自動スケールでは、22:00 から 23:59、00:00 から 02:00 から 02:00 の 2 日間にわたる 23:59 を 00:00 (同じノード数) と想定します。
- 既定では、スケジュールは世界協定時刻 (UTC) で設定されます。 使用可能なドロップダウンでは、ローカル タイム ゾーンに対応するタイム ゾーンにいつでも更新できます。 夏時間を監視するタイム ゾーンでは、スケジュールが自動的に調整されない場合は、それに応じてスケジュールの更新を管理する必要があります。

負荷ベースの自動スケールを使用してクラスターを作成する
クラスター プールが作成されたら、目的のワークロード (クラスターの種類) で 新しいクラスター を作成し、通常のクラスター作成プロセスの一環として他の手順を完了します。
[構成] タブで、[自動スケール 切り替え 有効にします。
ロード ベース 自動スケーリングを選択します
ワークロードの種類に応じて、グレースフルな停止タイムアウトと クールダウン期間 を追加するオプションがあります。
最小 と 最大 ノードを選択し、必要に応じてスケール ルールを構成 、ニーズに合わせて自動スケールをカスタマイズ。
ヒント
- サブスクリプションには、リージョンごとに容量クォータがあります。 ヘッド ノードのコアの合計数とワーカー ノードの最大数は、容量クォータを超えることはできません。 ただし、このクォータはソフト制限です。いつでもサポート チケットを作成して、簡単に増やすことができます。
- コア クォータの合計制限を超えた場合は、
The maximum node count you can select is {maxCount} due to the remaining quota in the selected subscription ({remaining} cores)というエラー メッセージが表示されます。 - スケールアップ ルールは、1 つ以上のルールがトリガーされたときに優先されます。 スケールアップの規則の 1 つだけがクラスターのプロビジョニング不足を示唆している場合でも、クラスターはスケールアップを試みます。 スケール ダウンを実行するには、スケールアップ ルールをトリガーする必要はありません。
- パブリック プレビューでは、AKS 上の HDInsight では、クラスター内の最大 500 ノードがサポートされます。

Resource Manager テンプレートを使用してクラスターを作成する
スケジュールに基づく自動スケール
azure Resource Manager テンプレートを使用してスケジュールベースの自動スケールを使用して AKS クラスター上に HDInsight を作成するには、clusterProfile -> autoscaleProfile セクションに自動スケールを追加します。
自動スケール ノードには、変更が行われるタイミングを説明するタイムゾーンとスケジュールを持つ繰り返しが含まれています。 完全な Resource Manager テンプレートについては、JSON のサンプルを参照してください
{
"autoscaleProfile": {
"enabled": true,
"autoscaleType": "ScheduleBased",
"gracefulDecommissionTimeout": 60,
"scheduleBasedConfig": {
"schedules": [
{
"days": [
"Monday",
"Tuesday",
"Wednesday"
],
"startTime": "09:00",
"endTime": "10:00",
"count": 2
},
{
"days": [
"Sunday",
"Saturday"
],
"startTime": "12:00",
"endTime": "22:00",
"count": 5
},
{
"days": [
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday"
],
"startTime": "22:00",
"endTime": "23:59",
"count": 6
},
{
"days": [
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday"
],
"startTime": "00:00",
"endTime": "05:00",
"count": 6
}
],
"timeZone": "UTC",
"defaultCount": 110
}
}
}
ヒント (if referring to a piece of advice) or チップ (if referring to a gratuity) depending on context.
- スケーリング操作の失敗を回避するために、ARM デプロイを使用して競合しないスケジュールを設定する必要があります。
負荷ベースの自動スケール
Azure Resource Manager テンプレートを使用して負荷ベースの自動スケーリングを使用して AKS クラスター上に HDInsight を作成するには、clusterProfile -> autoscaleProfile セクションに自動スケールを追加します。
自動スケール ノードには、次の値が含まれます。
- ポーリング間隔、クールダウン期間、
- スムーズな廃止
- 最小ノードと最大ノード、
- 標準しきい値ルール、
- 変更が行われるタイミングを示すスケーリング メトリック。
完全な Resource Manager テンプレートについては、次のサンプル JSON を参照してください。
{
"autoscaleProfile": {
"enabled": true,
"autoscaleType": "LoadBased",
"gracefulDecommissionTimeout": 60,
"loadBasedConfig": {
"minNodes": 2,
"maxNodes": 157,
"pollInterval": 300,
"cooldownPeriod": 180,
"scalingRules": [
{
"actionType": "scaleup",
"comparisonRule": {
"threshold": 80,
"operator": " greaterThanOrEqual"
},
"evaluationCount": 1,
"scalingMetric": "allocatedCoresPercentage"
},
{
"actionType": "scaledown",
"comparisonRule": {
"threshold": 20,
"operator": " lessThanOrEqual"
},
"evaluationCount": 1,
"scalingMetric": "allocatedCoresPercentage"
}
]
}
}
}
REST API の使用
REST API を使用して実行中のクラスターで自動スケールを有効または無効にするには、自動スケール エンドポイントに PATCH 要求を行います:https://management.azure.com/subscriptions/{{USER_SUB}}/resourceGroups/{{USER_RG}}/providers/Microsoft.HDInsight/clusterpools/{{CLUSTER_POOL_NAME}}/clusters/{{CLUSTER_NAME}}?api-version={{HILO_API_VERSION}}
- 要求ペイロードで適切なパラメーターを使用します。 json ペイロードを使用して自動スケールを有効にすることができます。
- ペイロード (autoscaleProfile: null) を使用するか、フラグ (有効、false) を使用してオートスケールを無効にします。
- リファレンスについては、上記の手順で説明した JSON サンプルを参照してください。
実行中のクラスターの自動スケールを一時停止する
自動スケールで一時停止機能が導入されました。 これで、Azure portal を使用して、実行中のクラスターで自動スケールを一時停止できます。 次の図は、自動スケールの一時停止と再開を選択する方法を示しています

自動スケール操作を再開したいときに、再開できます。

ヒント
複数のスケジュールを構成し、自動スケールを一時停止しても、次のスケジュールはトリガーされません。 ノードが使用停止状態であっても、ノード数は変わりません。
自動スケール構成のコピー
Azure portal を使用すると、クラスター プール全体で同じクラスター図形に対して同じ自動スケール構成をコピーできるようになりました。この機能を使用して、同じ構成をエクスポートまたはインポートできます。

オートスケール活動の監視
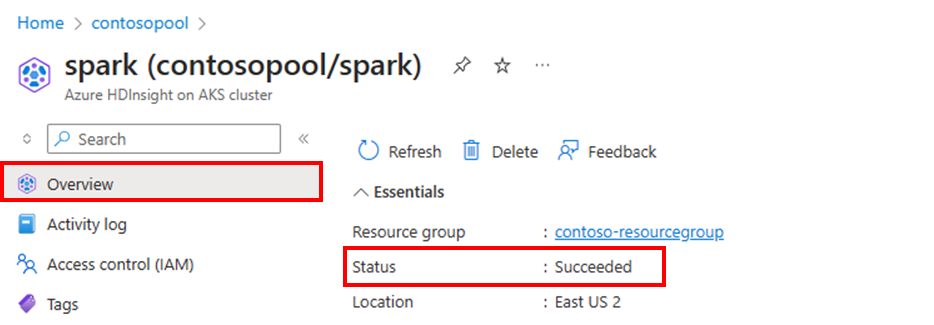
クラスターの状態
Azure portal に一覧表示されているクラスターの状態は、自動スケール アクティビティの監視に役立ちます。 表示される可能性があるクラスターのステータス メッセージはすべて、一覧で説明されています。
| クラスターの状態 | 説明 |
|---|---|
| 成功 | クラスターは正常に動作しています。 以前のすべての自動スケール アクティビティが正常に完了しました。 |
| 受け入れられた | クラスター操作 (スケールアップなど) が受け入れられ、操作が完了するのを待ちます。 |
| 失敗 しました | これは、何らかの理由で現在の操作が失敗したことを意味し、クラスターが機能していない可能性があります。 |
| キャンセル | 現在の操作は取り消されました。 |
クラスター内の現在のノード数を表示するには、クラスターの [の概要] ページの クラスター サイズ グラフに移動します。

操作履歴
クラスターメトリックの一部として、クラスターのスケールアップとスケールダウンの履歴を表示できます。 過去 1 日、1 週間、またはその他の期間のすべてのスケーリング アクションを一覧表示することもできます。

その他のリソース
手動スケール - AKS 上の Azure HDInsight