AKS 上の HDInsight 上の Apache Flink® で Azure Pipelines を使用する方法
重要
AKS 上の Azure HDInsight は、2025 年 1 月 31 日に廃止されました。 このお知らせ の詳細については、を参照してください。
ワークロードの突然の終了を回避するには、ワークロードを Microsoft Fabric または同等の Azure 製品 に移行する必要があります。
大事な
この機能は現在プレビュー段階です。 Microsoft Azure プレビューの 追加使用条件 には、ベータ版、プレビュー版、または一般公開されていない Azure 機能に適用される、より多くの法的条件が含まれています。 この特定のプレビューの詳細については、AKS プレビュー情報 Azure HDInsightを参照してください。 ご質問や機能の提案については、詳細を記載して AskHDInsight に要求を送信してください。また、Azure HDInsight Community をフォローして、最新情報をお受け取りください。
この記事では、AKS 上の HDInsight で Azure Pipelines を使用して、クラスターの REST API で Flink ジョブを送信する方法について説明します。 サンプルの YAML パイプラインと PowerShell スクリプトを使用したプロセスについて説明します。どちらも REST API の操作の自動化を効率化します。
前提 条件
Azure サブスクリプション。 Azure サブスクリプションをお持ちでない場合は、無料アカウントを作成します。
リポジトリを作成できる GitHub アカウント。 無料の用に作成します。
.pipelineディレクトリを作成し、flink-azure-pipelines.yml と を にコピーし、flink-job-azure-pipeline.ps1 します。Azure DevOps 組織。 無料で作成します。 チームに既にチームがある場合は、使用する Azure DevOps プロジェクトの管理者であることを確認します。
Microsoft でホストされているエージェントでパイプラインを実行する機能。 Microsoft でホストされるエージェントを使用するには、Azure DevOps 組織が Microsoft でホストされている並列ジョブにアクセスできる必要があります。 並列ジョブを購入するか、または無料の交付金を申請することができます。
Flink クラスター。 まだお持ちでない場合は、AKS上の HDInsight で Flink クラスターを作成してください。
クラスター ストレージ アカウントに 1 つのディレクトリを作成して、ジョブ jar をコピーします。 このディレクトリは、後で、ジョブ jar の場所 (<JOB_JAR_STORAGE_PATH>) 用にパイプライン YAML で構成する必要があります。
パイプラインを設定する手順
Azure Pipelines のサービス プリンシパルを作成する
Azure にアクセスするための Microsoft Entra サービス プリンシパル を作成します – AKS クラスター上の HDInsight にアクセスするための権限を「共同作成者」ロールで付与し、応答からアプリID、パスワード、およびテナントIDを記録してください。
az ad sp create-for-rbac -n <service_principal_name> --role Contributor --scopes <Flink Cluster Resource ID>`
例:
az ad sp create-for-rbac -n azure-flink-pipeline --role Contributor --scopes /subscriptions/abdc-1234-abcd-1234-abcd-1234/resourceGroups/myResourceGroupName/providers/Microsoft.HDInsight/clusterpools/hiloclusterpool/clusters/flinkcluster`
参考
手記
Apache、Apache Flink、Flink、および関連するオープンソースプロジェクト名は、Apache Software Foundation (ASF) の商標です。
キー保管庫を作成する
Azure Key Vault を作成するには、このチュートリアル に従って、新しい Azure Key Vault を作成してください。
3 つのシークレットを作成する
ストレージ キーの cluster-storage-key を します。
principal クライアントID または アプリID の サービス プリンシパル キー。
サービス プリンシパル シークレット を、プリンシパル シークレット のために設定します。
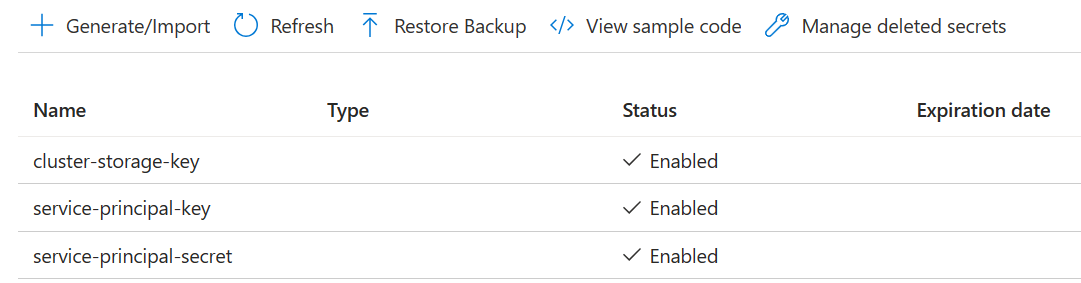
サービス プリンシパルに "Key Vault Secrets Officer" ロールを持つ Azure Key Vault にアクセスするためのアクセス許可を付与します。

パイプラインのセットアップ
プロジェクトに移動し、[プロジェクトの設定] をクリックします。
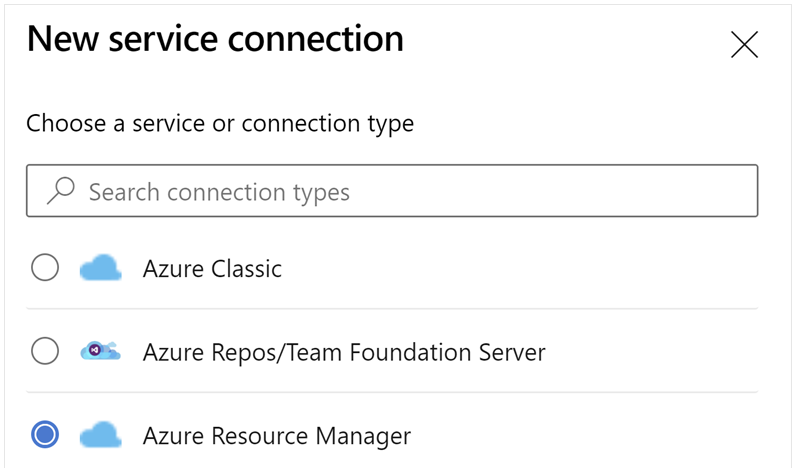
下にスクロールし、[サービス接続]、[新しいサービス接続] の順に選択します。
[Azure Resource Manager] を選択します。

認証方法で、サービス プリンシパル (手動) を選択します。
サービス接続のプロパティを編集します。 最近作成したサービス プリンシパルを選択します。
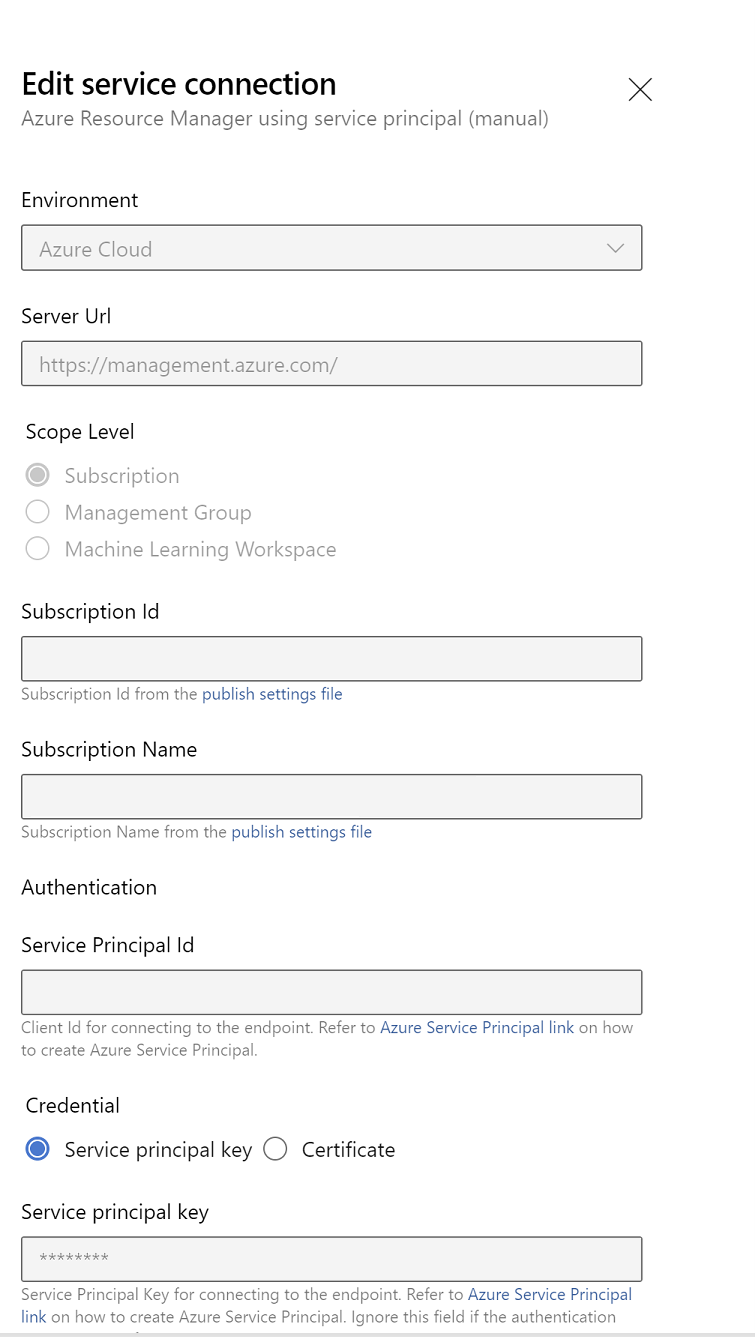
[確認] をクリックして、接続が正しく設定されているかどうかを確認します。 次のエラーが発生した場合:

次に、閲覧者ロールをサブスクリプションに割り当てる必要があります。
その後、検証が成功するはずです。
サービス接続を保存します。

パイプラインに移動し、[新しいパイプライン] をクリックします。

コードの場所として GitHub を選択します。
リポジトリを選択します。 GitHub でリポジトリ を作成する方法 参照してください。 GitHubレポジトリ画像を選択する。
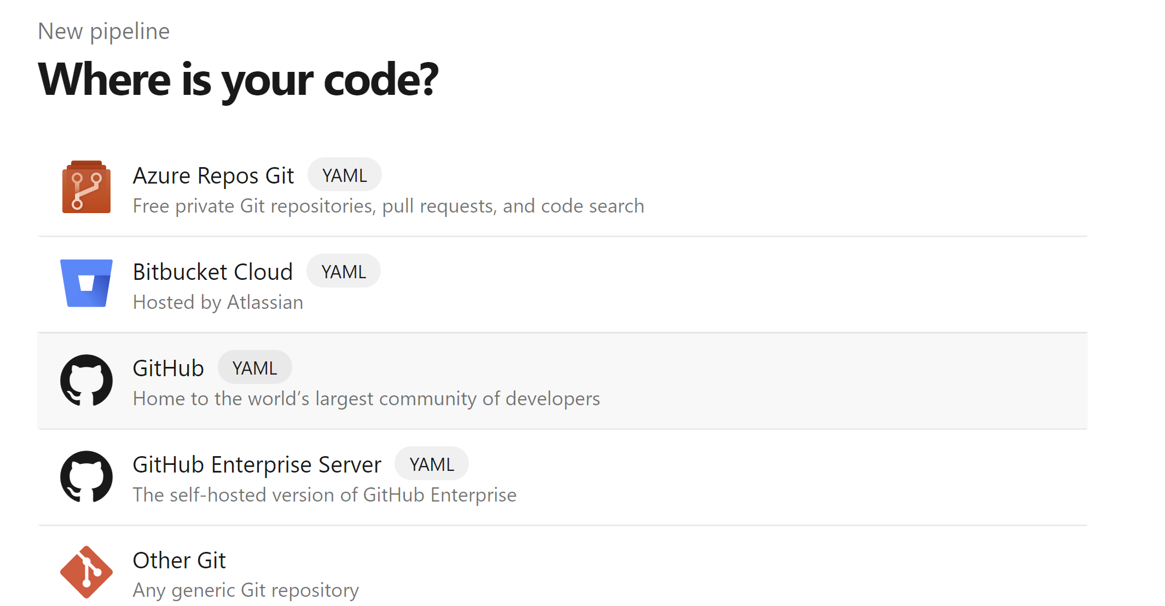
リポジトリを選択します。 詳細については、「GitHub でリポジトリを作成する方法」参照してください。
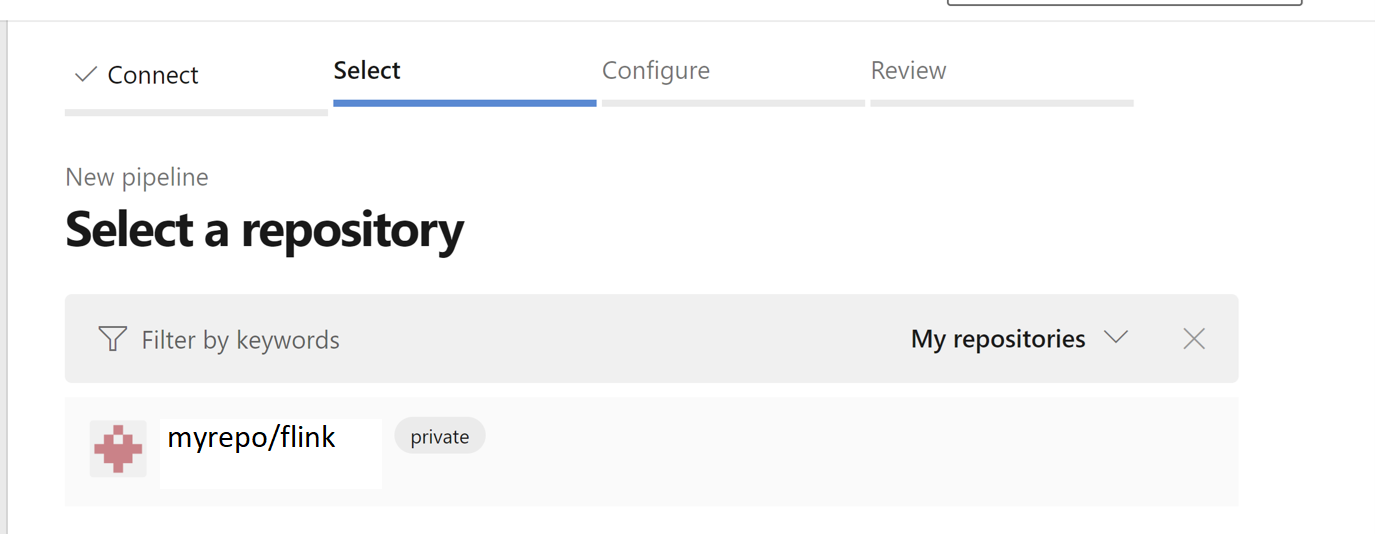
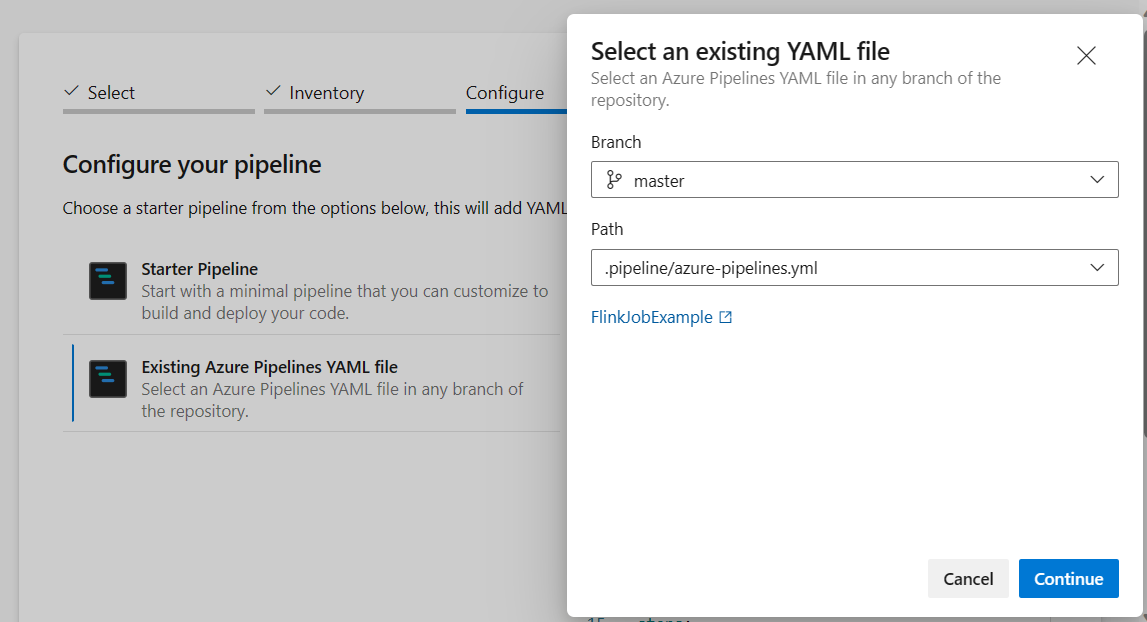
パイプラインの設定オプションで、既存の Azure Pipelines YAML ファイルを選択できます。 先ほどコピーした分岐スクリプトとパイプライン スクリプトを選択します。 (.pipeline/flink-azure-pipelines.yml)
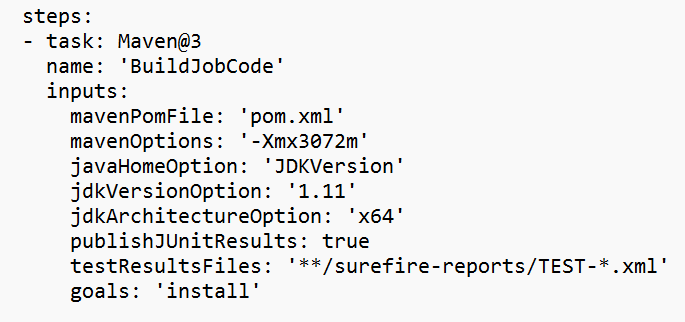
変数セクションの値を置き換えます。

要件に基づいてコード ビルド セクションを修正し、ジョブ jar ローカル パスの変数セクションで <JOB_JAR_LOCAL_PATH> を構成します。
パイプライン変数 "action" を追加し、値 "RUN" を構成します。
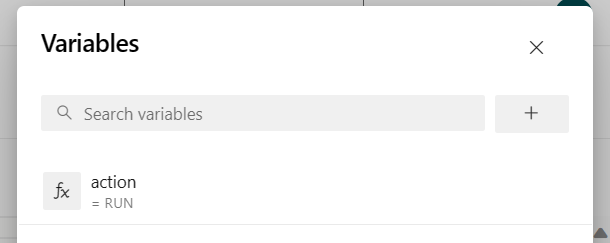
パイプラインを実行する前に変数の値を変更できます。
NEW: この値は既定値です。 新しいジョブが起動し、ジョブが既に実行されている場合は、実行中のジョブを最新の jar で更新します。
SAVEPOINT: この値は、ジョブ実行用のセーブポイントを取得します。
DELETE: 実行中のジョブを取り消すか削除します。
パイプラインを保存して実行します。 [Flink Job]\(Flink ジョブ\) セクションで、ポータルで実行中のジョブを確認できます。








手記
これは、パイプラインを使用してタスクを送信する例です。 Flink REST API ドキュメントに従って、ジョブを送信する独自のコードを記述できます。