AKS 上の HDInsight での Apache Flink® 構成管理
大事な
AKS 上の Azure HDInsight は、2025 年 1 月 31 日に廃止されました。 についての詳しい情報は、このお知らせで確認してください。
ワークロードの突然の終了を回避するには、ワークロードを Microsoft Fabric または同等の Azure 製品 に移行する必要があります。
大事な
この機能は現在プレビュー段階です。 Microsoft Azure プレビューの 追加使用条件 には、ベータ版、プレビュー版、または一般公開されていない Azure 機能に適用される、より多くの法的条件が含まれています。 この特定のプレビューの詳細については、AKS プレビュー情報 Azure HDInsightを参照してください。 ご質問や機能の提案については、詳細を記載したリクエストを AskHDInsight まで送信し、Azure HDInsight Community の情報をフォローして最新情報をご確認ください。
AKS 上の HDInsight には、ほとんどのプロパティと、一般的なアプリケーション プロファイルに基づくいくつかの Apache Flink の既定の構成のセットが用意されています。 ただし、状態の使用、並列処理、またはメモリ設定を使用して特定のアプリケーションのパフォーマンスを向上させるために Flink 構成プロパティを調整する必要がある場合は、AKS クラスター上の HDInsight の Flink Jobs セクションを使用して Flink ジョブの構成を変更できます。
設定に移動 > Flinkジョブ > 更新をクリックします。
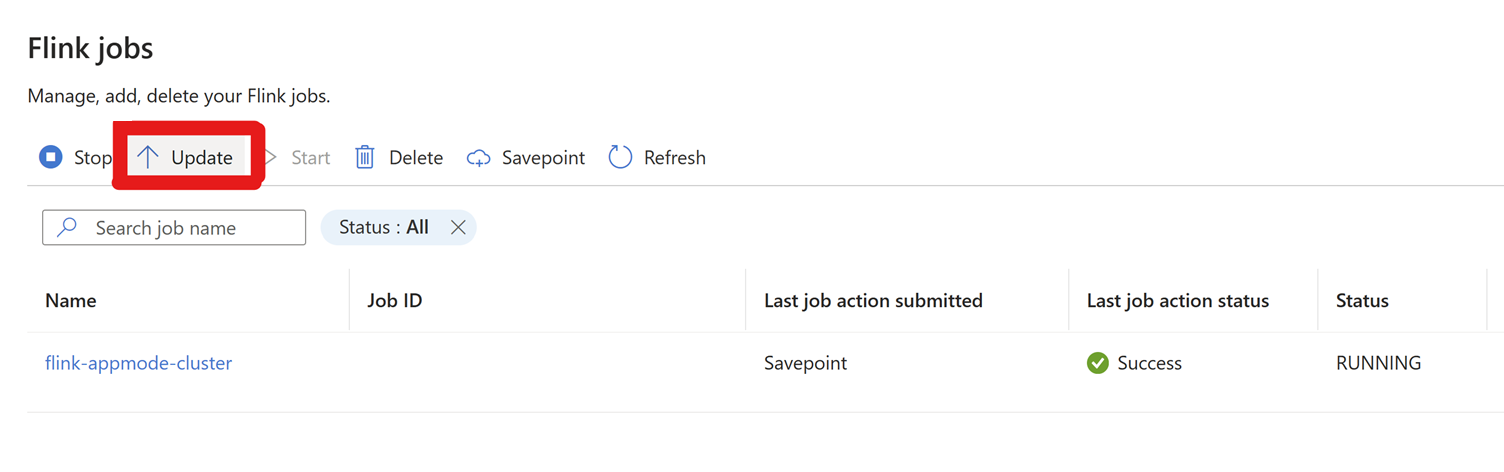
[+ 行 を追加] をクリックして構成を編集します。
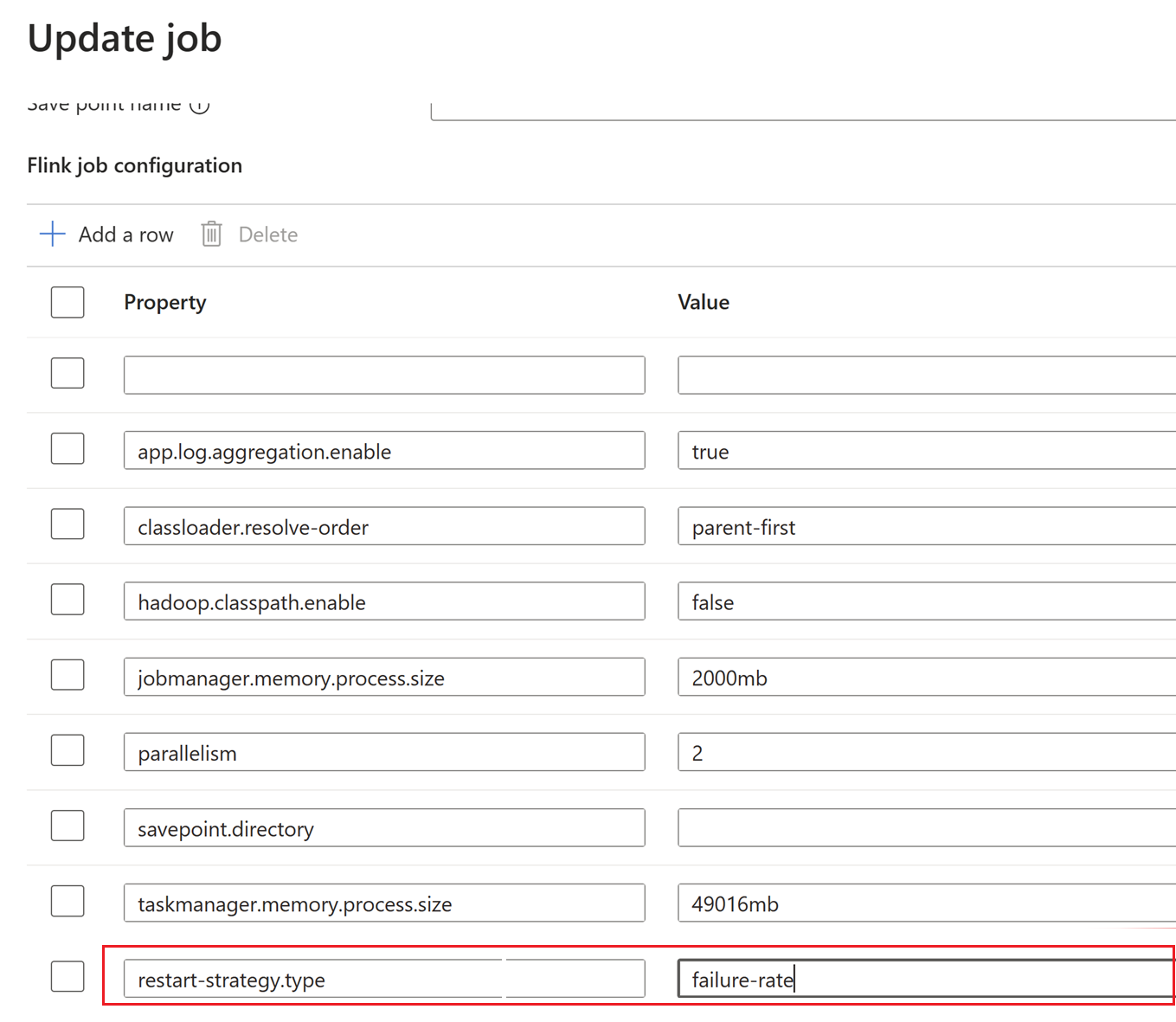
ここで、チェックポイント間隔はクラスター レベルの 変更されます。
[OK] クリックし、[保存] をして変更を更新します。
保存すると、新しい構成は数分 (最大 5 分) で更新されます。
構成。構成管理設定を使用して更新できます。
processMemory size:ジョブ マネージャーとタスク マネージャーのプロセス メモリ サイズの既定の設定は、クラスターの作成時にユーザーが構成したメモリになります。
このサイズは、次の構成プロパティを使用して構成できます。 タスク マネージャーのプロセス メモリを変更するには、この構成を使用します。
taskmanager.memory.process.size : <value>例:
taskmanager.memory.process.size : 2000mbジョブマネージャー用
jobmanager.memory.process.size : <value>手記
構成可能な最大プロセス メモリは、
jobmanager/taskmanager用に構成されたメモリと同じです。


チェックポイント間隔
チェックポイント間隔によって、Flink がチェックポイントをトリガーする頻度が決まります。 ミリ秒単位で定義され、次の構成プロパティを使用して設定できます
execution.checkpoint.interval: <value>
既定の設定は 60,000 ミリ秒 (1 分) です。この値は必要に応じて変更できます。
ステートバックエンド
状態バックエンドは、Flink がアプリケーションの状態を管理および保持する方法を決定します。 チェックポイントの格納方法に影響します。 'state バックエンドは、次のプロパティを使用して構成できます。
state.backend: <value>
既定では、AKS 上の HDInsight の Apache Flink クラスターでは、Rocks DB が使用されます。
チェックポイント ストレージ パス
既定では、永続的なチェックポイントを許可するには、ユーザーが構成した abfs ストレージにチェックポイントを格納します。 ジョブが失敗した場合でも、チェックポイントは永続化されるため、最新のチェックポイントで簡単に開始できます。
state.checkpoints.dir: <path> チェックポイントが格納されている目的のパスに <path> を置き換えます。
既定では、ユーザーによって構成されたストレージ アカウント (ABFS) に格納されます。 この値は、Flink ポッドがアクセスできる限り、任意のパスに変更できます。
最大同時チェックポイント数
次のプロパティを設定することで、同時実行チェックポイントの最大数を制限できます: checkpoint.max-concurrent-checkpoints: <value>
<value> を、必要な同時実行チェックポイントの最大数に置き換えます。 たとえば、一度に 1 つのチェックポイントのみを許可する場合は 1 です。
保持されるチェックポイントの最大数
保持するチェックポイントの最大数を制限するには、次のプロパティを設定します。
state.checkpoints.num-retained: <value>
<value> を目的の最大数に置き換えます。 既定では、最大 5 つのチェックポイントが保持されます。
セーブポイント記憶領域パス
既定では、永続的なセーブポイントを許可するには、セーブポイントを (ユーザーが構成した) abfs ストレージに格納します。 ユーザーが停止し、後で特定のセーブポイントでジョブを開始する場合は、この場所を構成できます。
state.checkpoints.dir: <path> <path> を、セーブポイントが格納されている目的のパスに置き換えます。
既定では、ユーザーによって構成されたストレージ アカウントに格納されます。 (ABFS をサポートしています)。 この値は、Flink ポッドがアクセスできる限り、任意のパスに変更できます。
ジョブ マネージャーの高可用性
AKS 上の HDInsight では、Flink はバックエンドとして Kubernetes を使用します。 既知または不明な問題が原因でジョブ マネージャーが失敗した場合でも、数秒以内にポッドが再起動されます。 そのため、この問題が原因でジョブが再起動した場合でも、ジョブは 最新のチェックポイントから復旧されます。
FAQ
ジョブが途中で失敗するのはなぜですか? ジョブが突然失敗した場合でも、チェックポイントが継続的に発生している場合、ジョブは既定で最新のチェックポイントから再起動されます。
途中でジョブ戦略を変更しますか? いくつかのジョブ レベルのバグにより、運用環境でジョブを変更する必要があるユース ケースがあります。 その間、ユーザーはジョブを停止できます。このジョブは自動的にセーブポイントを取得し、セーブポイントの場所に保存します。
savepointをクリックし、savepointが完了するまで待ちます。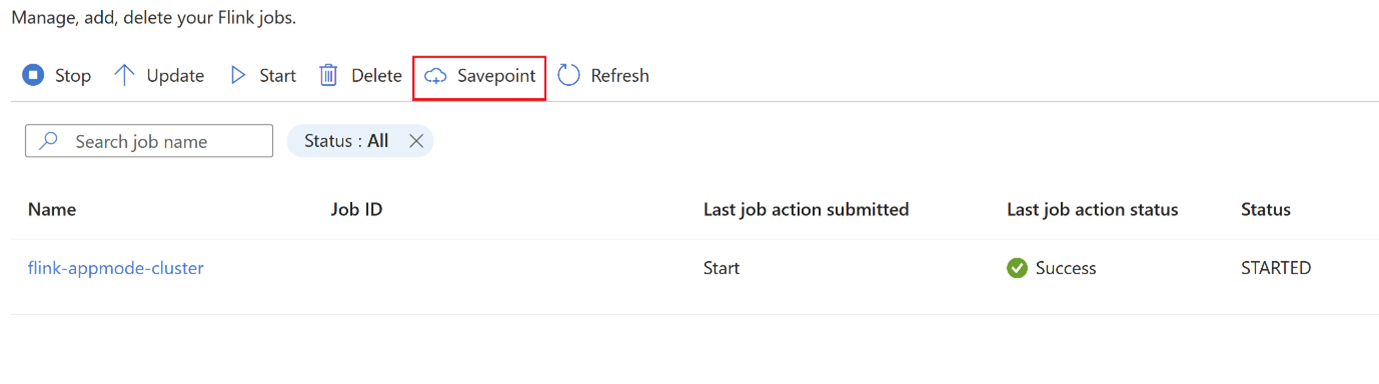
セーブポイントが完了したら、[開始] をクリックすると、[ジョブの開始] タブが表示されます。 ドロップダウンからセーブポイント名を選択します。 必要に応じて、構成を編集します。 OK をクリックします。
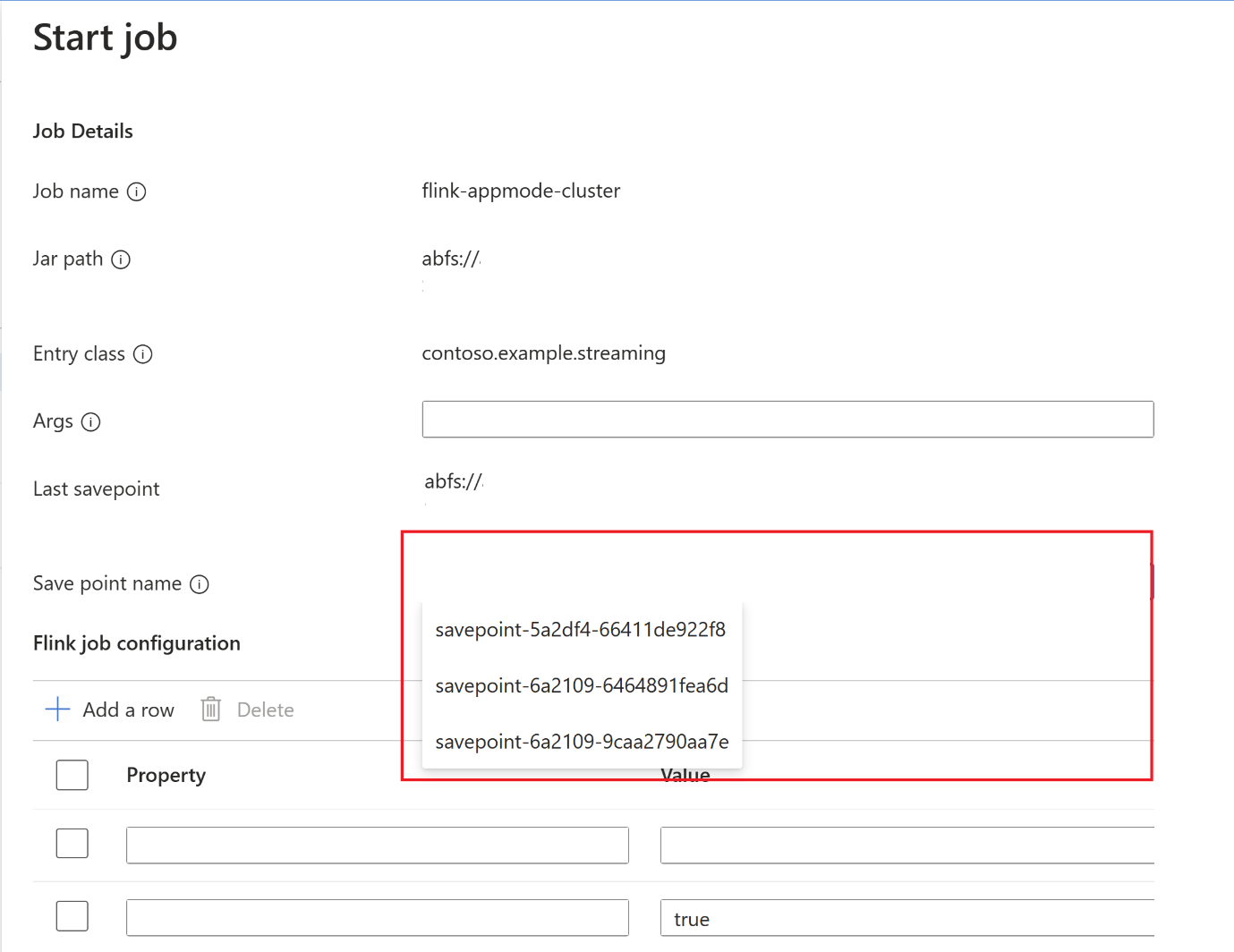


セーブポイントはジョブで提供されるため、Flink はデータの処理を開始する場所を認識します。
参考
- Apache Flink の設定
- Apache、Apache Kafka、Kafka、Apache Flink、Flink、および関連するオープン ソース プロジェクト名は、Apache Software Foundation (ASF) の 商標です。