Apache Flink® DataStream API を使用して Azure Data Lake Storage Gen2 にイベント メッセージを書き込む
大事な
AKS 上の Azure HDInsight は、2025 年 1 月 31 日に廃止されました。 こちらのお知らせ で、の詳細を確認してください。
ワークロードの突然の終了を回避するには、ワークロードを Microsoft Fabric または同等の Azure 製品 に移行する必要があります。
大事な
この機能は現在プレビュー段階です。 Microsoft Azure プレビューの 追加使用条件 には、ベータ版、プレビュー版、または一般公開されていない Azure 機能に適用される、より多くの法的条件が含まれています。 この特定のプレビューの詳細については、AKS プレビュー情報 Azure HDInsightを参照してください。 ご質問や機能の提案がある場合は、AskHDInsight に詳細を記入してリクエストを送信してください。また、追加の情報については、Azure HDInsight Communityをフォローしてください。
Apache Flink は、ファイルシステムを使用してデータを消費し、アプリケーションの結果を永続的に保存します。また、フォールトトレランスと回復のためにもデータを保存します。 この記事では、DataStream API を使用して Azure Data Lake Storage Gen2 にイベント メッセージを書き込む方法について説明します。
前提 条件
- AKS 上の HDInsight での Apache Flink クラスター
-
HDInsight での Apache Kafka クラスター
- HDInsight での Apache Kafka の使用に関するの説明に従って、ネットワーク設定を確実に管理する必要があります。 AKS クラスターと HDInsight クラスター上の HDInsight が同じ仮想ネットワーク内にあることを確認します。
- MSI を使用して ADLS Gen2 にアクセスする
- AKS Virtual Network 上の HDInsight の Azure VM での開発のための IntelliJ
Apache Flink FileSystem コネクタ
このファイルシステム コネクタは、BATCH と STREAMING の両方で同じ保証を提供し、STREAMING の実行に対して 1 回だけセマンティクスを提供するように設計されています。 詳細については、「Flink DataStream ファイルシステムの 」を参照してください。
Apache Kafka コネクタ
Flink は、Kafka トピックとの間でデータを読み取り、Kafka トピックに書き込むための Apache Kafka コネクタを 1 回だけ保証します。 詳細については、「Apache Kafka Connector」を参照してください。
Apache Flink 用のプロジェクトをビルドする
IntelliJ IDEA のpom.xml
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<flink.version>1.17.0</flink.version>
<java.version>1.8</java.version>
<scala.binary.version>2.12</scala.binary.version>
<kafka.version>3.2.0</kafka.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-java -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-files -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<appendAssemblyId>false</appendAssemblyId>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
ADLS Gen2 シンク の プログラム
abfsGen2.java
手記
hdInsight クラスター上 Apache Kafka bootStrapServers を Kafka 3.2 用の独自のブローカーに置き換える
package contoso.example;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.configuration.MemorySize;
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy;
import java.time.Duration;
public class KafkaSinkToGen2 {
public static void main(String[] args) throws Exception {
// 1. get stream execution env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Configuration flinkConfig = new Configuration();
flinkConfig.setString("classloader.resolve-order", "parent-first");
env.getConfig().setGlobalJobParameters(flinkConfig);
// 2. read kafka message as stream input, update your broker ip's
String brokers = "<update-broker-ip>:9092,<update-broker-ip>:9092,<update-broker-ip>:9092";
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers(brokers)
.setTopics("click_events")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStream<String> stream = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
stream.print();
// 3. sink to gen2, update container name and storage path
String outputPath = "abfs://<container-name>@<storage-path>.dfs.core.windows.net/flink/data/click_events";
final FileSink<String> sink = FileSink
.forRowFormat(new Path(outputPath), new SimpleStringEncoder<String>("UTF-8"))
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(Duration.ofMinutes(2))
.withInactivityInterval(Duration.ofMinutes(3))
.withMaxPartSize(MemorySize.ofMebiBytes(5))
.build())
.build();
stream.sinkTo(sink);
// 4. run stream
env.execute("Kafka Sink To Gen2");
}
}
パッケージ化した jar を作成し、Apache Flink に送信します。
jar を ABFS にアップロードします。
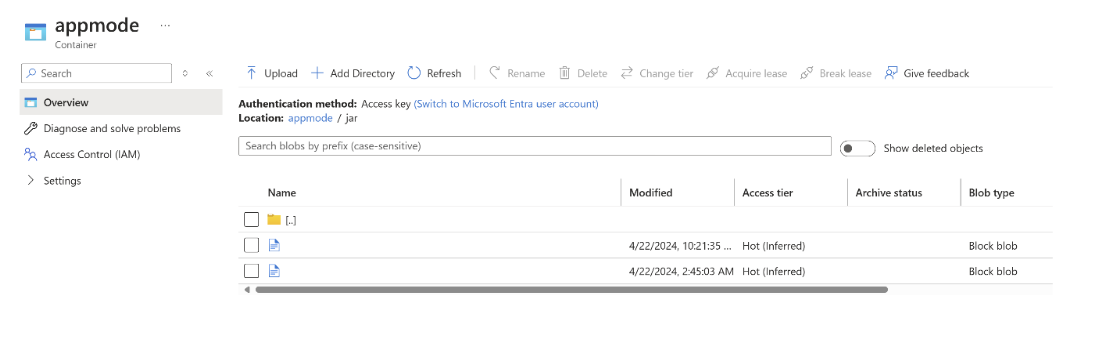
クラスター
AppModeの作成時に、ジョブ jar 情報を渡します。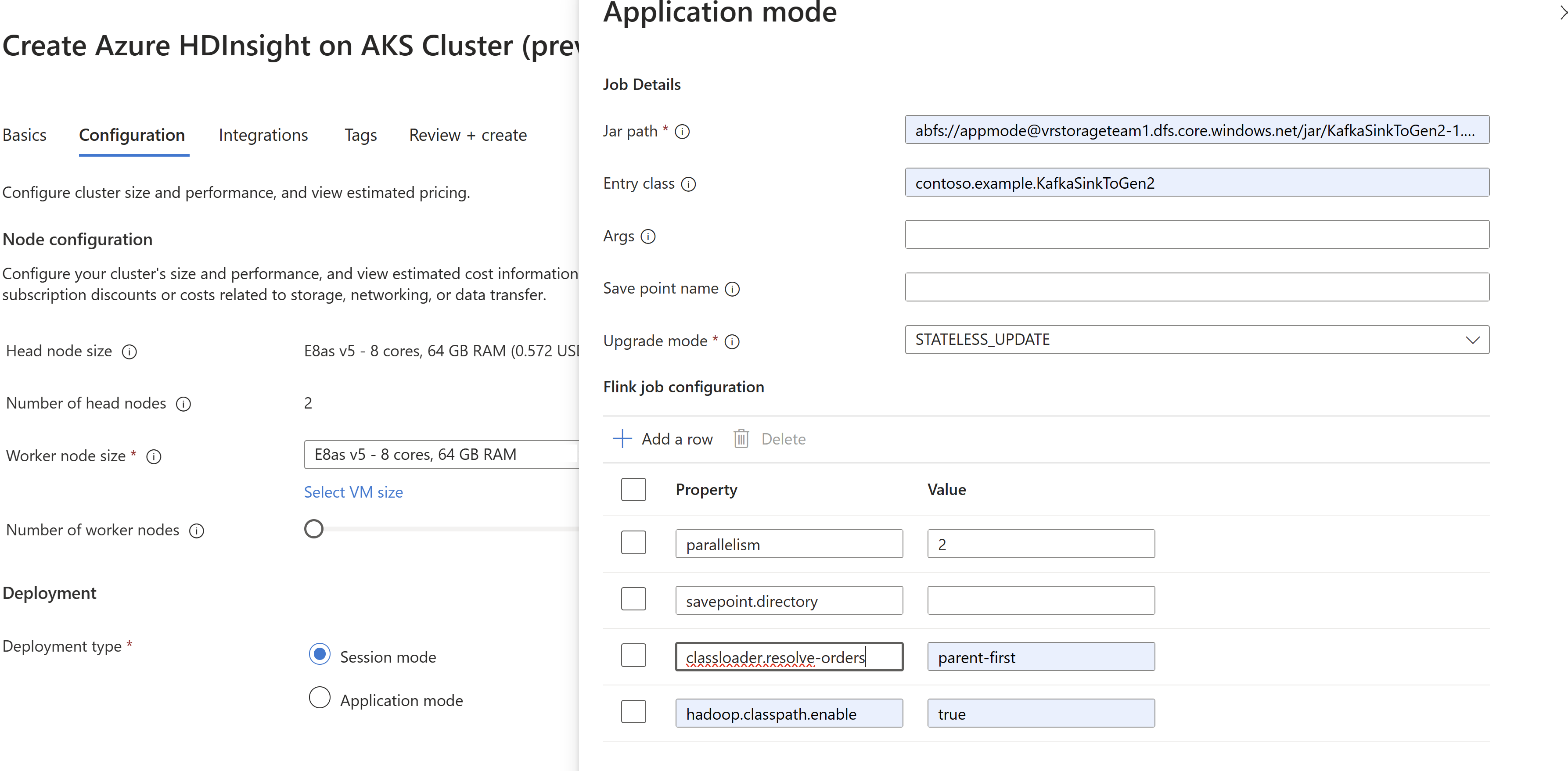
手記
classloader.resolve-order を 'parent-first' として必ず追加し、hadoop.classpath.enable を
trueとして設定してください。ジョブ ログの集計を選択して、ジョブ ログをストレージ アカウントにプッシュします。
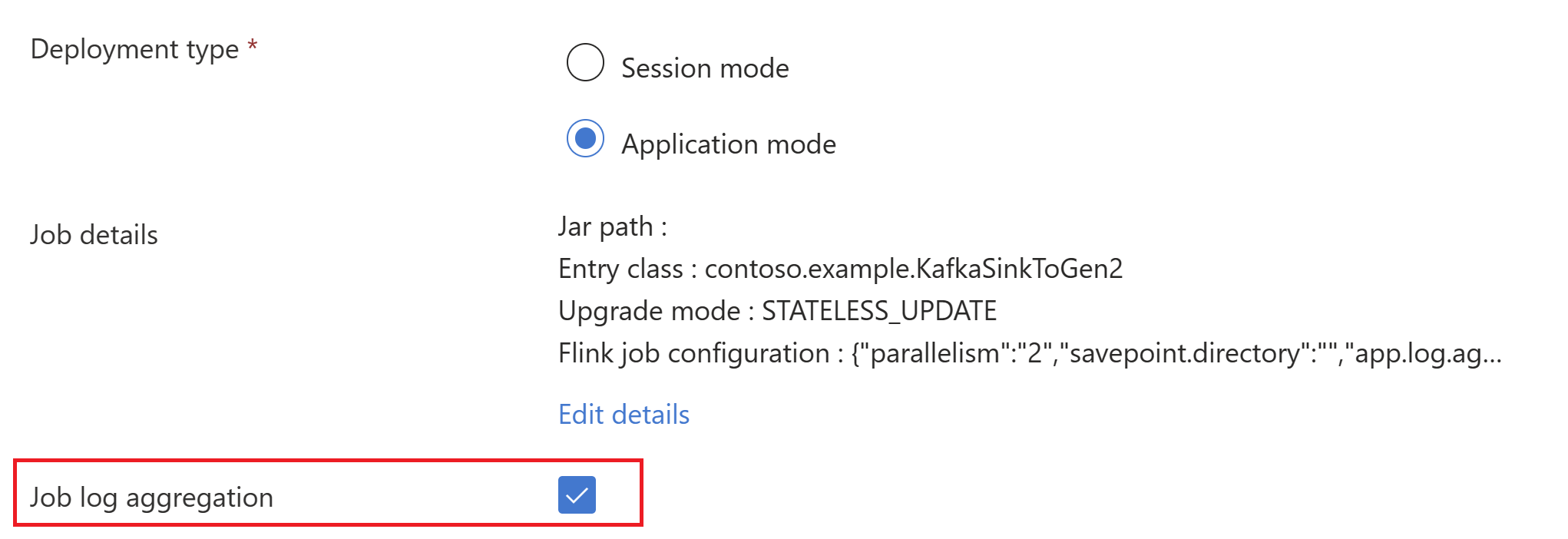
実行中のジョブを確認できます。
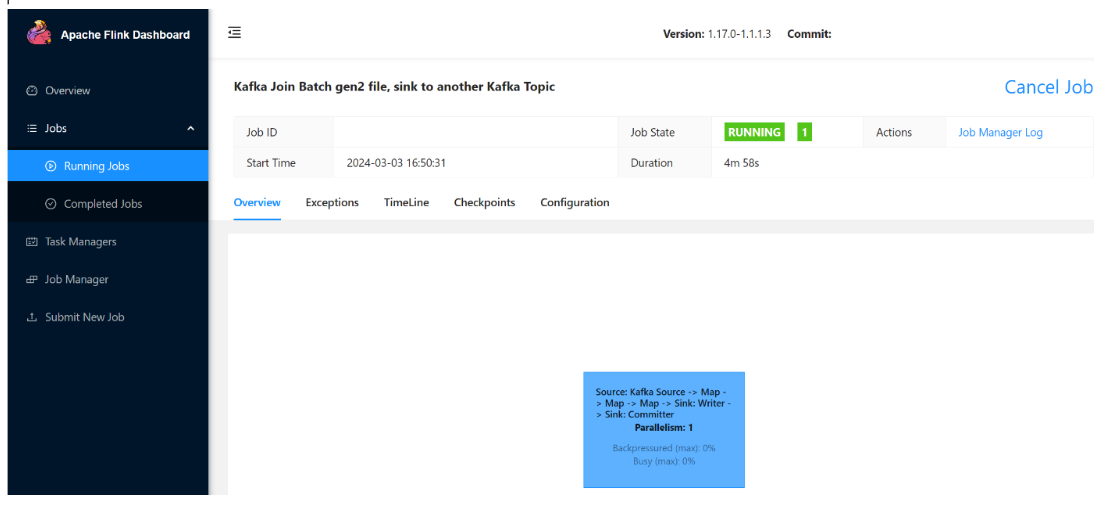




ADLS Gen2 でストリーミング データを検証する
ADLS Gen2 への click_events ストリーミングが表示されます。

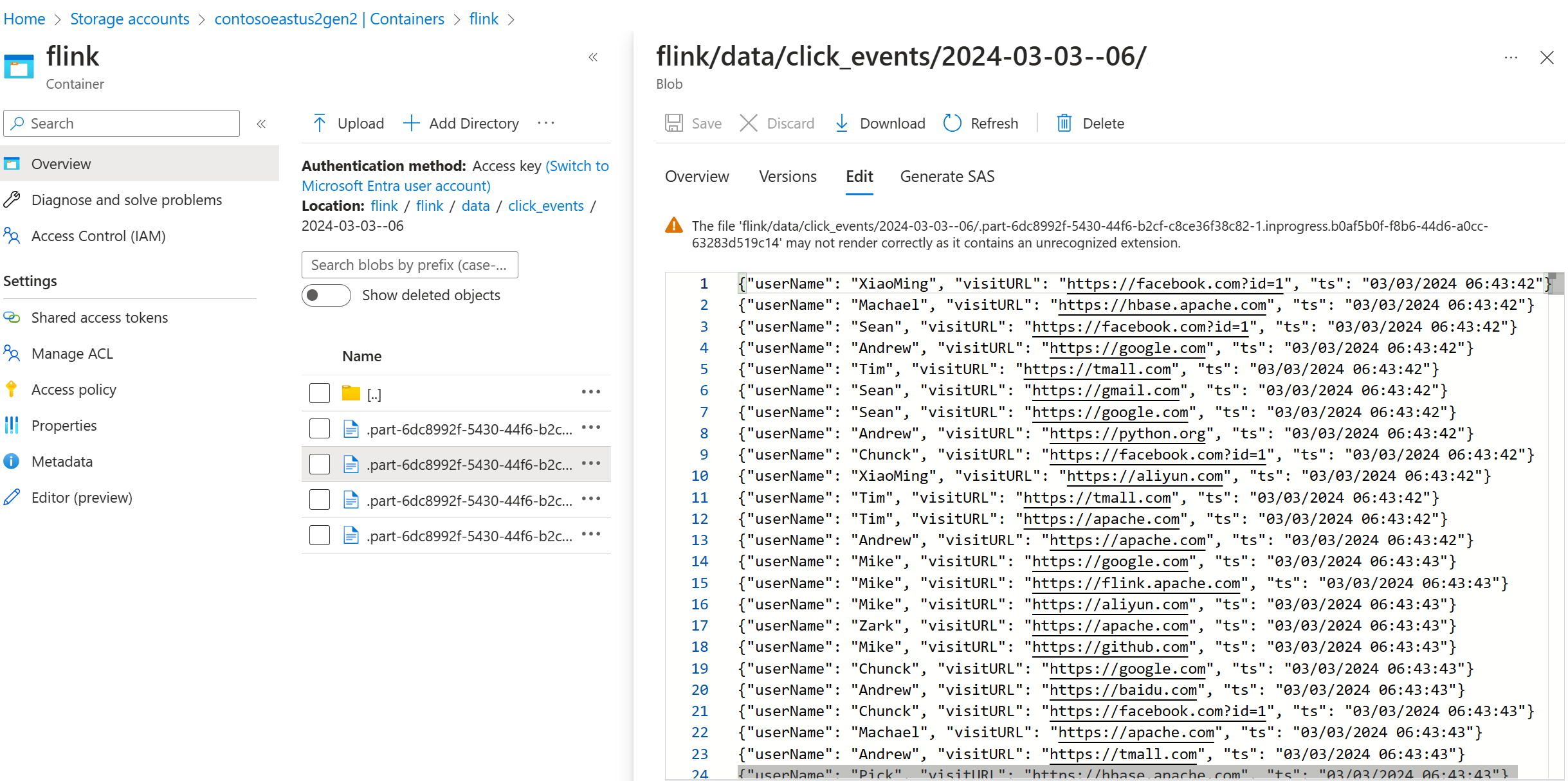
進行中のパーツ ファイルを次の 3 つの条件のいずれかにロールするローリング ポリシーを指定できます。
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(Duration.ofMinutes(5))
.withInactivityInterval(Duration.ofMinutes(3))
.withMaxPartSize(MemorySize.ofMebiBytes(5))
.build())
参考
- Apache Kafka コネクタ
- Flink DataStream のファイルシステム
- Apache Flink ウェブサイト
- Apache、Apache Kafka、Kafka、Apache Flink、Flink、およびこれらに関連するオープンソースプロジェクトの名称は、Apache Software Foundation (ASF) の 商標です。